Intel TBB malloc 内存分配器
1. TBB Malloc 使用入门
有两种方式使用TBB Malloc:Run-Time替换,Link-Time替换。替换的函数(routines)包括:
| routines | Linux | MacOS | Windows |
|---|---|---|---|
| global C++ new / delete | √ | √ | √ |
| C库:malloc / calloc / realloc / free | √ | √ | √ |
| C库(C11):aligned_alloc | √ | - | - |
| POSIX:posix_memalign | √ | √ | - |
Run-Time替换方法:
| 平台 | 替换方法 |
|---|---|
| Linux | export LD_PRELOAD=$TBBROOT/lib/intel64/gcc4.8/libtbbmalloc_proxy.so.2 |
| MacOS | export DYLD_INSERT_LIBRARIES=$TBBROOT/lib/intel64/gcc4.8/libtbbmalloc_proxy.dylib |
Link-Time替换方法:
| 平台 | 替换方法 |
|---|---|
| Linux & MacOS | -L$TBBROOT/lib/intel64/gcc4.8 -ltbbmalloc_proxy |
| Windows | tbbmalloc_proxy.lib /INCLUDE:"__TBB_malloc_proxy" |
Link-Time替换,需要添加编译flags。不添加这些编译flags,可能导致malloc等这些函数被内联为汇编,即失去了符号,也就没有办法替换了。需要添加的flags如下:
Linux/MacOS平台下,添加如下编译flags(适用于Linux/MacOS):
-fno-builtin-malloc
-fno-builtin-calloc
-fno-builtin-realloc
-fno-builtin-free
Windows平台下,icc编译器添加如下编译flags:
- /Qfno-builtin-malloc
- /Qfno-builtin-calloc
- /Qfno-builtin-realloc
- /Qfno-builtin-free
替换Proxy入口代码文件为
src/tbbmalloc_proxy/proxy.cpp。
1.1. 直接使用TBB malloc(Compile-Time)
| Allocation Routine | Deallocation Routine | 对应系统运行时库 |
|---|---|---|
| scalable_malloc, scalable_calloc, scalable_realloc | scalable_free | C Standard library |
| scalable_aligned_malloc, scalable_aligned_realloc | scalable_aligned_free | Microsoft C runtime |
与C++ STL对应的allocator:

一个简单使用示例:
#include <vector>
#include <algorithm>
#include <execution>
#include <tbb/scalable_allocator.h>
std::vector<int, tbb::scalable_allocator<int>> v{…};
std::sort(std::execution::par, v.begin(), v.end());
1.2. Huge Pages
TBB malloc支持Huge Pages,可以通过设置环境变量TBB_MALLOC_USE_HUGE_PAGES来启用,或者在代码中设置:
scalable_allocation_mode( TBBMALLOC_USE_HUGE_PAGES,1);
Huage Pages可以减少malloc调用,减少TLB Miss,提高性能,尤其是在分配大块内存时。
1.3. memory_pool_allocator
TBB malloc提供了一个memory_pool_allocator,它通过预先分配一大块内存,避免TBB Malloc模块的管理开销。管理器需要查找空闲块、分割块、记录元数据(这块内存多大、是否在用等)。
其约束为,每次分配的大小为固定的P,因为它是通过简单的基于 P 取模的偏移量获取内存块的。适用于作为STL容器的分配器。一个示例如下:
#define TBB_PREVIEW_MEMORY_POOL 1
#include "oneapi/tbb/memory_pool.h"
#include <list>
int main() {
oneapi::tbb::memory_pool<std::allocator<int>> my_pool;
typedef oneapi::tbb::memory_pool_allocator<int> pool_allocator_t;
std::list<int, pool_allocator_t> my_list(pool_allocator_t{my_pool});
my_list.emplace_back(1);
}
当memory_pool中内存用尽之后,将向底层Alloc申请内存进行扩容。新增的内存切分成若干FreeBlock,并添加到pool内部的空闲链表。扩容大小由extMemPool->granularity决定,扩容的内存可能来自其他线程丢弃的的orphaned blocks,也可能来自底层Alloc分配的内存。其类声明如下:
//! Thread-safe growable pool allocator for variable-size requests
template <typename Alloc>
class memory_pool : public pool_base
另外,定义了一个fixed_pool,内存池耗尽之后不会扩展。
1.4. 局部替代 new & delete
当某些模块需要自定义allocator时,可以通过局部替代new和delete来实现:
#include <tbb/parallel_for.h>
#include <tbb/tbb_allocator.h>
// No retry loop because we assume that
// scalable_malloc does all it takes to allocate the memory,
// so calling it repeatedly will not improve the situation at all
// No use of std::new handler because it cannot bedone in portable and
// thread-safe way We throw std::bad alloc() when scalable mallocreturns NULL
// (we return NULL if it is a no-throw implementation)
void *operator new(size_t size) throw(std::bad_alloc) {
if (size == 0) size = 1;
if (void *ptr = scalable_malloc(size))
return ptr;
throw std::bad_alloc();
}
void *operator new[](size_t size) throw(std::bad_alloc) {
return operator new(size);
}
void *operator new(size_t size, const std::nothrow_t &) throw {
if (size == 0) size = 1;
if (void *ptr = scalable_malloc(size))
return ptr;
return NULL;
}
void *operator new[](size_t size, const std::nothrow_t &) throw {
return operator new(size, std::nothrow);
}
void operator delete(void *ptr) throw() {
if (ptr != 0) scalable_free(ptr);
}
void operator delete[](void *ptr) throw() { operator delete(ptr); }
void operator delete(void *ptr, const std::nothrow_t &) throw() {
if (ptr != 0) scalable_free(ptr);
}
void operator delete[](void *ptr, const std::nothrow_t &) throw() {
operator delete(ptr, std::nothrow);
}
int main(int argc, char **argv) {
const size_t size = 1000;
const size_t chunk = 100;
// scalable malloc will be called to allocate
// the memory for this array of integers
int *p = new int[size];
tbb::parallel_for(size_t{0}, size, [=](size_t chunk) {
// scalable_malloc will be called to allocate the memory for this
// array of integers
int *p = new int[chunk];
// scalable_free will be called to deallocate the memory for this
// array of integers
delete[] p;
});
return 0;
}
代码示例来自
Pro TBB第七章:Scalable Memory Allocation。
2. TBB scalable allocator 架构分析
TBB scalable allocator基于前后端两层分层架构:分为Frontend和Backend两层。Frontend负责处理基于线程的内存分配请求,Backend负责物理内存分配和全局内存管理(线程分配及回收)。
每个线程都有一个自己独立的本地缓存(local cache)。当线程请求内存时,首先检查本地缓存中分配,如果有空闲块,则直接返回本地的空闲块,这个查询及分配操作是无锁的。另外,本地维护的空闲链表,被分类为不同大小的内存块(Size Class),每个Size Class维护一个空闲链表,比如8字节、16字节、2KB等。
Backend负责物理内存分配/释放、处理碎片。当某个线程的缓存空了,会向Backend请求内存块,当线程本地的缓存太多时,会将多余的内存块返回给Backend。
由于Backend是共享的,所有访问Backend需要加锁。另外,Huge Pages的支持也是在Backend实现的。
这套前端/后端的分层架构,特点为:
- Thread-Local Storage (TLS): 利用 TLS 存储每个线程的分配器状态,避免全局锁。
- Cross-Thread Recycling: 如果线程 A 释放了内存,而线程 B 需要内存,分配器需要能安全地将 A 释放的块转交给 B。TBB malloc 使用一种延迟回收或集中式回收的机制来处理这种跨线程转移,同时尽量减少锁竞争。
- Object Caching: 释放的内存不会立即还给 OS,而是保留在缓存中,以便下次快速重用。
Frontend代码路径:src/tbbmalloc/frontend.cpp。Backend代码路径:src/tbbmalloc/backend.cpp。 tbbmalloc相关的部分高层代码路径:include/oneapi/tbb/memory_pool.hsrc/tbb/allocator.cppsrc/tbbmalloc_proxy/proxy.cpp。
2.1. Linux系统符号替换
ELF 格式中,符号有三种绑定类型(st_bind):
| 类型 | 说明 |
|---|---|
| STB_GLOBAL | 强符号,全局可见,重复定义时链接报错 |
| STB_WEAK | 弱符号,可被强符号覆盖,未覆盖时使用弱版本 |
| STB_LOCAL | 局部符号,仅文件内可见 |
dlopen以及动态链接器只加载找到的第一个强符号,在proxy.cpp中,定义这些符号(部分定义截图):
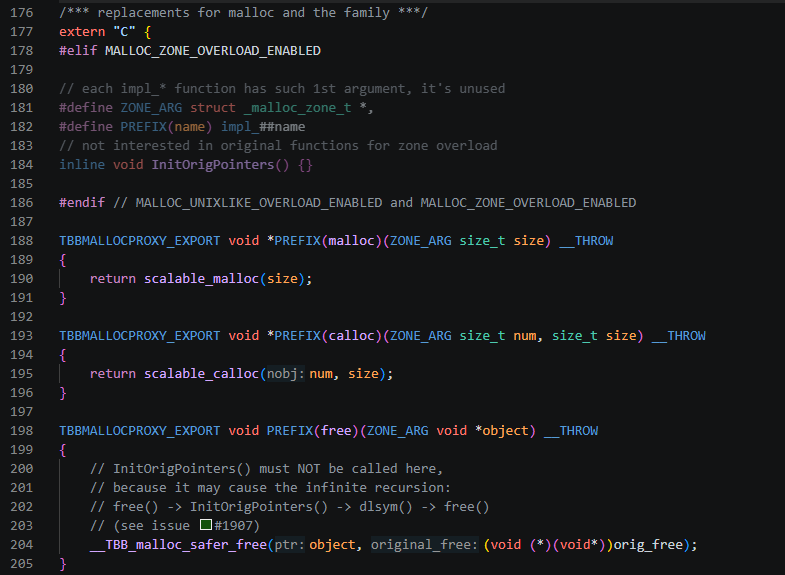
并调用dlsym(RTLD_NEXT, ...)保留系统原始的symbol,用作初始化阶段bootstrap调用:
inline void InitOrigPointers()
{
// race is OK here, as different threads found same functions
if (!origFuncSearched.load(std::memory_order_acquire)) {
orig_free = dlsym(RTLD_NEXT, "free");
orig_realloc = dlsym(RTLD_NEXT, "realloc");
orig_msize = dlsym(RTLD_NEXT, "malloc_usable_size");
orig_libc_free = dlsym(RTLD_NEXT, "__libc_free");
orig_libc_realloc = dlsym(RTLD_NEXT, "__libc_realloc");
origFuncSearched.store(true, std::memory_order_release);
}
}
另外,使用__attribute__((alias))将libc库中的__libc_*等函数替换为对应的routines:
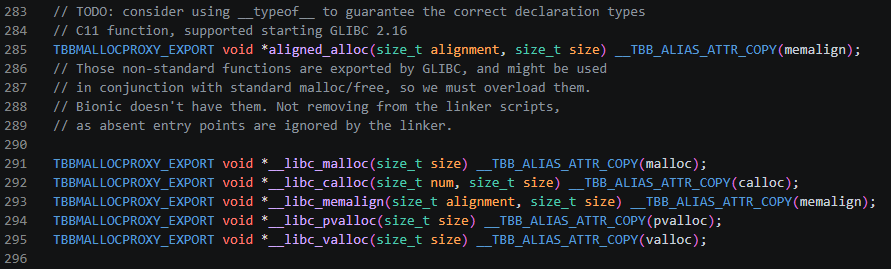
alias(“sym”) 让当前符号成为 sym 的别名,两个名字指向同一段代码。即将
__libc_free等符号截获并替换为free等符号。
2.2. TBB scalable allocator 的实现
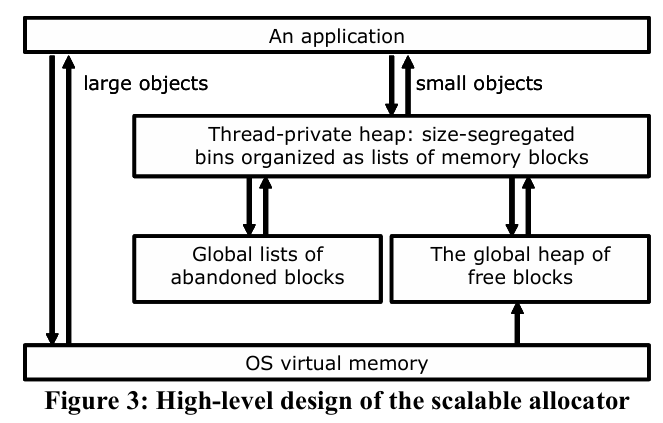
初始化的时候,Backend以1MB为单位,从系统申请内存,并将这些内存切分成Block(每个Block大小为16KB,内存对齐为16KB),并放在global heap of free blocks中。这个时候,申请的global heap of free blocks常驻内存,不会被释放,以保证这些内存的复用。ExtMemoryPool::backend实现了Backend。
当线程TLS内存不够时,再向Backend从global heap of free blocks中申请内存块(Block),此时Backend需要从系统申请新的内存块(以1MB为单位)。
另外,还有一个Global Heap of Abandoned Blocks。线程退出时,TLSData 中尚未释放的 Slab 会被孤立化(orphaned),放入全局废弃队列(shareOrphaned/privatizeOrphaned),供其他线程认领复用。
2.2.1. Size Class
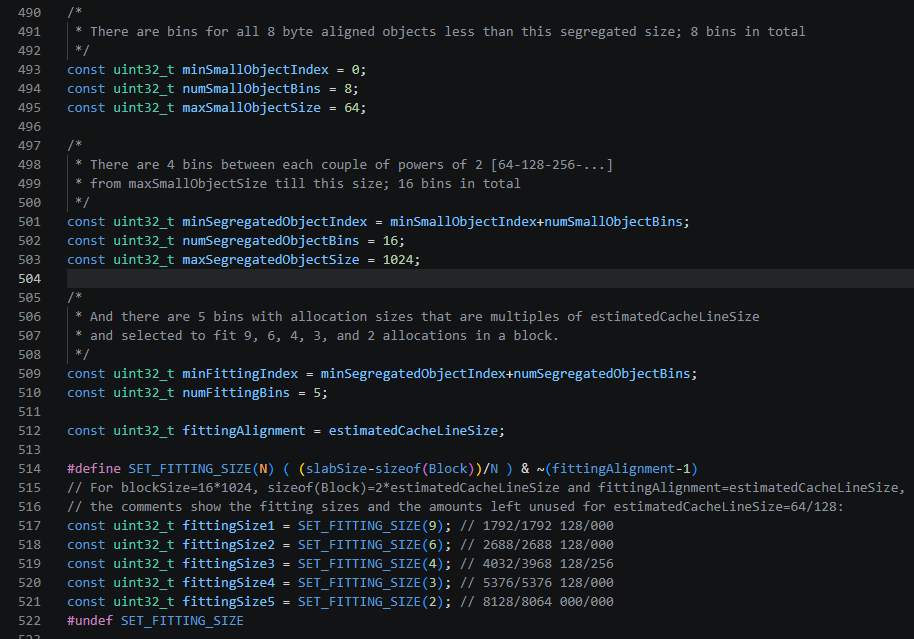
Frontend分配的最小单位是Object,并分成不同Size Class的Object:
- 小对象(Small):≤64字节,共8个bin
- 分隔对象(Segregated):64~1024字节,共16个bin
- 拟合对象(Fitting):1792字节、2688字节、…8128字节,共5个bin
- 大对象(Large):>8128字节(即大于fittingSize5)
- 巨型对象(Huge):>4MB,直接从操作系统分配–mmap/munmap
Size Class划分定义如下:
2.2.2. bin(桶) 以及 Memory Block / Slab
Object并不是直接从整块内存中分配的,而是从Block中分配的。每个Block包含多个Object,并且每个Size Class维护一个空闲链表(free list)来管理这些Block。
由于Object有不同的Size Class,所以按Size Class分类,创建对应的链表,即有若干个Block链表,每个链表管理一个Size Class的Block。当线程请求内存时,从Size Class对应的的Block空闲链表查找,如果有空闲的Block,则从中分配一个Object;如果没有,则向Backend请求新的Block。
不同Size Class的Block链表,存在对应的bin(桶)中,一共定义了32个bin。每个线程有一个TLSData,里面存了一个Bin bin[numBlockBins]。每个bin中定义了一个activeBlk,以及一个mailbox。
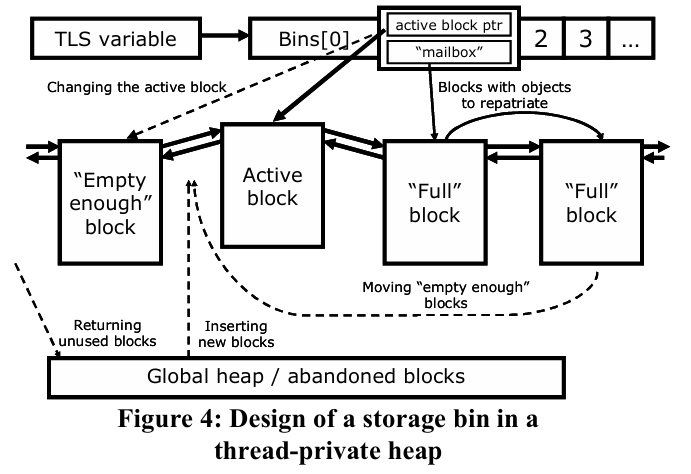
整个Frontend核心数据结构可以示意如下:
TLSData // 每个线程独立一份(Thread Local Storage)
└── bin[numBlockBins] // 32个bin,按Size Class分类
├── bin[0] // Size Class: 小对象 8字节
│ ├── activeBlk ──────────────► Block // 当前活跃Block的指针
│ ├── mailbox // 跨线程回收的Object队列
│ └── BlockList (LIFO)
│ ├── Block
│ │ ├── BlockHeader // 元数据:size class、已分配数等
│ │ └── Object[N] // N个等大的Object槽位
│ └── ...
├── bin[1] // Size Class: 16字节
│ └── ...
└── ... // 共32个bin
Object的分配:在一个bin中Block的索引顺序为Full Block(后) => Active Block => Empty enough block(前),bin中有activeBlk信息,当需要分配Object时,查询activeBlk中是否有空槽位(Slot),有则直接返回这个Slot,如果没有则移动到下一个索引继续查找,这样顺序索引速度快。当一个Block中Object槽位被释放足够多时(满足Empty enough block条件),这个Block移动到Active Block的前面。
Object的释放:每个Block包含一个BlockHeader(LocalBlockFields/GlobalBlockFields),里面有Size Class等信息,所以释放Object需要的信息直接从Block中获取,而不需要在Object自身存储这些信息。当一个Block中的所有被释放之后,这个Block归还到global heap of free blocks中。(Empty enough block是指有足够多的槽位空位–低于1/4,并不是完全槽位被释放。)
使用
Block/Object结构以及等分设计,是的内存更紧凑,针对小Object具有良好的内存局部性以及缓存局部性,即相同Size Class的内存对象都分配在一起。实际实践上,附近的变量更可能被访问到,这样就能更好地利用CPU缓存,提升性能。
2.2.3. 生产-消费模型:跨线程回收
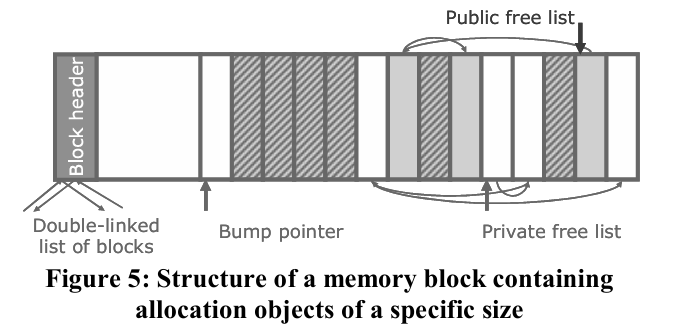
由于Frontend是线程本地的,如果允许其他线程访问则需要加锁。为了避免锁竞争,在Block内,定义了两个链表:freeList以及publicFreeList,并定义了两个接口函数,用于释放public free list、将public free list里面的Object回收到free list:
void freePublicObject(FreeObject *objectToFree);
void privatizePublicFreeList(bool reset = true);
public free list的访问性能略有下降,其使用atomic操作保证线程安全:
std::atomic<FreeObject*> publicFreeList;
2.2.4. 碎片整理:Coalescing(合并)
Coalescing流程主要发生在Backend,目的是将相邻的空闲内存块合并,以减少碎片,并在整个内存区域(MemRegion)空闲时将其归还给操作系统。
2.2.4.1. 核心数据结构 GuardedSize
其中定义枚举:
enum State {
LOCKED, // 块正在被使用
COAL_BLOCK, // 块正在参与合并,block is coalescing now
MAX_LOCKED_VAL = COAL_BLOCK,
LAST_REGION_BLOCK, // 区域末尾的标记块,used to mark last block in region
// values after this are "normal" block sizes
MAX_SPEC_VAL = LAST_REGION_BLOCK // 正常的大小值(> MAX_SPEC_VAL):块空闲
};
2.2.4.2. 核心数据结构:FreeBlock
- myL:保护本块大小的锁
- leftL:保护左侧邻居大小的锁(存在于右侧块头部,供合并时快速访问)
- nextToFree:用于组成合并延迟队列的链表指针
2.2.4.3. 核心类:CoalRequestQ — 延迟合并请求队列
当合并因邻居块被锁定而无法立即进行时,当前块会被放入这个无锁队列,等待后续处理。
coalescQ 的存在是为了避免死锁与过度竞争:当两个线程同时释放相邻块时,有一方会检测到邻居正在合并(COAL_BLOCK 状态),并将自己的块放入 coalescQ,由后续任意线程的分配/清理操作来处理。
2.2.4.4. 核心合并函数:doCoalesc
doCoalesc()尝试将一个块与其左右邻居进行合并,返回合并后的大块;若无法立即合并,则将块放入coalescQ并返回nullptr。
2.2.4.5. 其他核心处理函数
函数coalescAndPutList()对合并后的块列表逐一处理,
- 场景 A:整个区域已空(memRegion != nullptr 且块大小等于区域的初始块大小)
- 场景 B:合并后的块放回 bin
- 最终解锁
函数scanCoalescQ():延迟合并队列。scanCoalescQ() 负责将 coalescQ 中积压的块取出并重新尝试合并,在以下时机被调用:
- 分配时(genericGetBlock()):每次尝试获取块前,先扫描延迟队列
- 等待块释放时(BackendSync::waitTillBlockReleased()):监测 inFlyBlocks,若有进展则扫描队列
- 软限制清理时(releaseCachesToLimit()):超过内存软限制时扫描
- 全局清理时(Backend::clean()):清理 advance regions 前先扫描
2.3. Frontend: handling large objects
TODO
A. 资料
- Memory Allocation:官方文档
- Scalable Memory Allocation for Parallel Algorithms:PPT资料,介绍TBB Malloc的使用
- scalable_allocators:Intel TBB scalable_malloc benchmark
- The_Foundations_for_Scalable_Multi-Core_Software_in_Intel_Threading_Building_Blocks:早期讲述TBB scalable allocator设计的文章(
Scalable Memory Allocator Architecture),介绍了当时的设计思路和实现细节 - COMP522-2019-TBB-OpenMP:设计思路对应的PPT资料
- How to Use oneTBB for Efficient Memory Allocation in C++ Applications:Intel 官方文章,介绍了tbbmalloc架构(不够完整清晰,作为补充材料)
- On the Impact of Memory Allocation on High-Performance Query Processing:性能测试对比论文
Enjoy Reading This Article?
Here are some more articles you might like to read next: