CUDA 架构(1.1):Hopper架构及性能分析(ncu) + 性能优化
1. GPU thread hierarchy, SIMT, and Warp divergence
1.1. Thread Hierarchy: Grid & Blocks
grid是thread blocks的集合,代表这次启动kernel的全部工作。thread block之间完全独立,不能共享数据,不能通过__syncthreads同步,不能假设他们的执行顺序,不能假设两个thread block同时启动及运行。
有关thread block与SM:
- 若干个thread block可以同时在一个SM上运行(可以达到Hide Latency),前提是它们的资源需求(寄存器、共享内存等)满足SM的资源限制(Occupancy)。
- 同一个thread block的所有线程必须在同一个SM上运行,因为它们需要共享资源(如共享内存)和进行同步。
| 资源 | SM上限 | 如何影响 |
|---|---|---|
| 最大Block数 | 32 | 硬性上限,不管Block多小 |
| 最大Warp数 | 64 | 即最多2048个线程同时驻留 |
| 最大线程数 | 2048 | 同上 |
| 寄存器文件 | 65536个32-bit寄存器 | 每个线程用的寄存器越多,能驻留的线程越少 |
| 共享内存 | 最大228 KB | 每个Block用的shared memory越多,能放的Block越少 |
计算Occupancy举例:
场景1:每个Block有256个线程,每个线程用32个寄存器,每个Block用0 shared memory
线程数限制: 2048 / 256 = 8 个Block
Warp数限制: 64 / (256/32) = 64/8 = 8 个Block
寄存器限制: 65536 / (256 × 32) = 65536/8192 = 8 个Block
Block数限制: 32
→ 结果:min(8, 8, 8, 32) = 8 个Block可以驻留
即哪个资源限制最紧,该资源就形成瓶颈。
1.2. Thread Hierarchy: Clusters
Hopper架构引入了Thread Block Clusters,以及硬件上的分布式共享内存(Distributed Shared Memory, DSMEM)。
- Cluster可配置为1/2/4/8/16个thread block。
- Cluster保证Cluster内的Thread Block同时被调度到不同的SM上执行,以保证他们之间的通信,以及避免等待死锁。
- Clusters:将多个thread block组织成一个cluster,允许它们共享数据和进行更高效的通信。每个cluster内的thread block可以通过DSM进行数据交换。
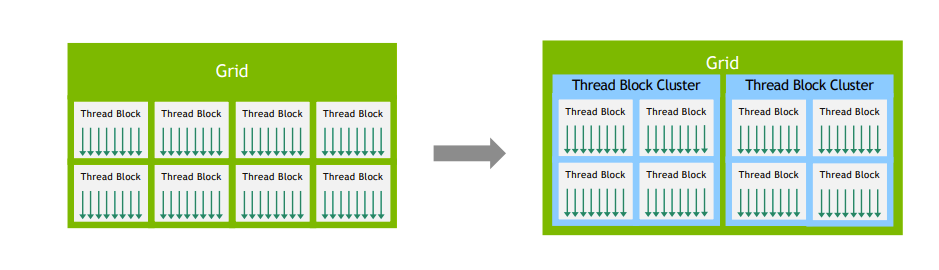
应用场景:
- GEMM:每个block负责一个tile,多个block组成一个cluster,cluster内的block通过DSM共享tile数据,不用重复从全局内存访问。
- Reduction:每个block负责一部分数据,多个block组成一个cluster,cluster内的block通过DSM共享中间结果。
1.3. SIMT Architecture
有条件分支的时候,warp内每个线程需要执行所有的分支路径,即线程分叉(warp diverge),导致部分clock浪费。
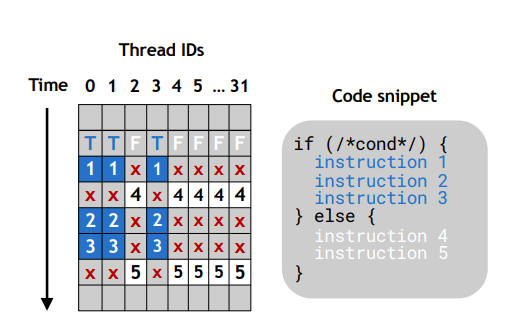
图中,标记红叉的部分是浪费的时钟周期,这部分计算生成输出。
在使用ncu分析时,从Warp State Statistics中查看线程分叉指标,以及从Source页面查看一些指标。
2. Warp scheduling and Kernel profiling at a glance
2.1. Warp Scheduler Statistics
Warp Slot状态(在Warp Scheduler Statistics页面中查看):
| 状态 | 含义 | 性能影响 |
|---|---|---|
| Unused | Slot空闲,没有Warp | Occupancy低,浪费硬件能力 |
| Active | Warp驻留在SM上 | 越高越好(更多Warp可供调度) |
| Stalled | Active但在等待某些东西 | 正常现象,但占比过高说明有瓶颈 |
| Eligible | 万事俱备,等待被选中 | 越多越好(调度器有的选) |
| Selected | 本周期被选中发射指令 | 受限于Scheduler数量(每SM 4个) |
含义:这个Warp Slot上有一个Warp驻留在SM上,它的寄存器、状态等都保存在硬件中。Active = Stalled + Eligible(包括Selected)。
Stall Reasons原因分类:
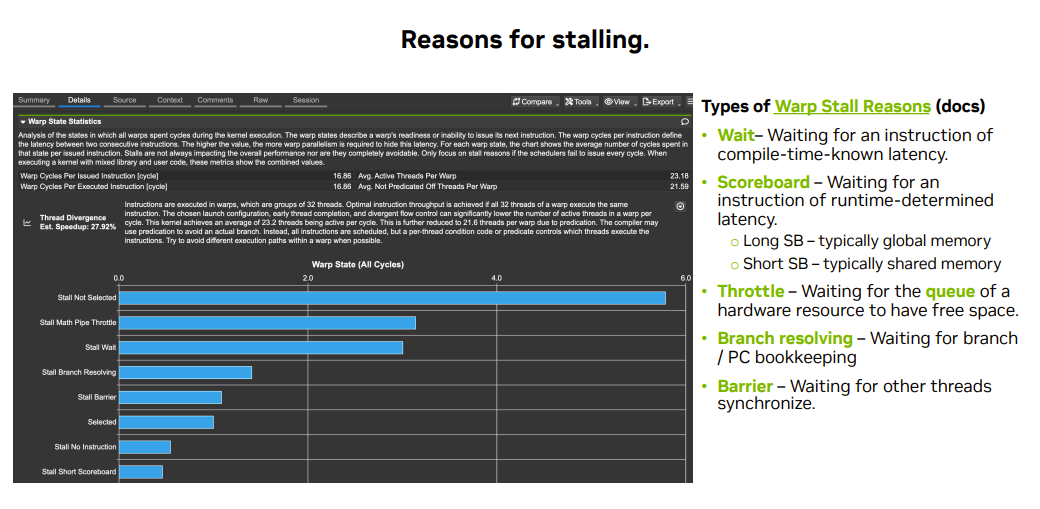
Stall来源列表:
| Warp State / Stall Reason | 含义 | 常见触发场景 |
|---|---|---|
| Stall Math Pipe Throttle | 需要的数学/计算流水线(FP/INT/SFU 等)繁忙,当前 warp 发不进去(结构性拥塞) | 大量 FMA/FP64/INT/特殊函数 sin/exp/rsqrt 等,或者指令高度集中在同一类计算管线 |
| Stall LG Throttle | Local/Global 内存管线(LD/ST)相关资源/队列饱和,导致新的 LD/ST 不能及时发射 | 频繁 global load/store、local memory(寄存器溢出导致的本地内存访问)、大量 scatter/gather 访问 |
| Stall MIO Throttle | 内存 I/O 相关的“杂项/特殊”管线拥塞(通常是某类内存/原子/特殊访存通路资源受限),warp 因结构性资源不足而等待 | 原子操作密集、某些特殊内存指令组合(不同于纯 LG/纯 TEX 的那类)、高频内存系统操作 |
| Stall Long Scoreboard | 等待长延迟指令的结果(典型:global memory、L2/DRAM miss),数据没回来导致后续指令依赖无法就绪 | 读取全局内存后立刻使用(依赖链短)、cache miss 多、访问不合并 |
| Stall Short Scoreboard | 等待相对短延迟指令的结果(例如 shared/常量/某些管线较短的依赖),仍未就绪 | shared memory 访问后紧接使用、shared bank conflict、常量/纹理命中但仍有固定延迟 |
| Stall Barrier | 等待同步点(barrier)满足(如 __syncthreads()),本 warp 已到但其他 warp 未到 | 线程块内工作不均衡、分支导致部分 warp 慢、sync 过频繁 |
| Stall Branch Resolving | 控制流相关原因导致等待(分支目标/谓词/重汇合等处理阶段),本周期无法发射 | 分支多、分支发散严重、间接跳转/复杂控制流 |
| Stall Wait | 等待某类“等待/依赖管理”相关的内部条件完成(NCU 将其归为 Wait 类等待) | 某些需要等待条件满足的指令序列(与依赖/同步/内存子系统管理相关) |
| Stall Not Selected | warp 其实是 Eligible,但当周期调度器选了别的 warp(发射槽位有限) | Eligible warps 很多、调度竞争激烈;通常是“系统健康”的表现之一 |
| Selected | (积极状态) Warp 被调度器选中,在本周期发射了一条指令。 | 无阻塞。这是性能良好的标志,表明调度器能持续找到可执行的 Warp。该值应尽可能高。若 Selected 低而 Stall 高,说明存在瓶颈。 |
2.2. ncu 瓶颈分析
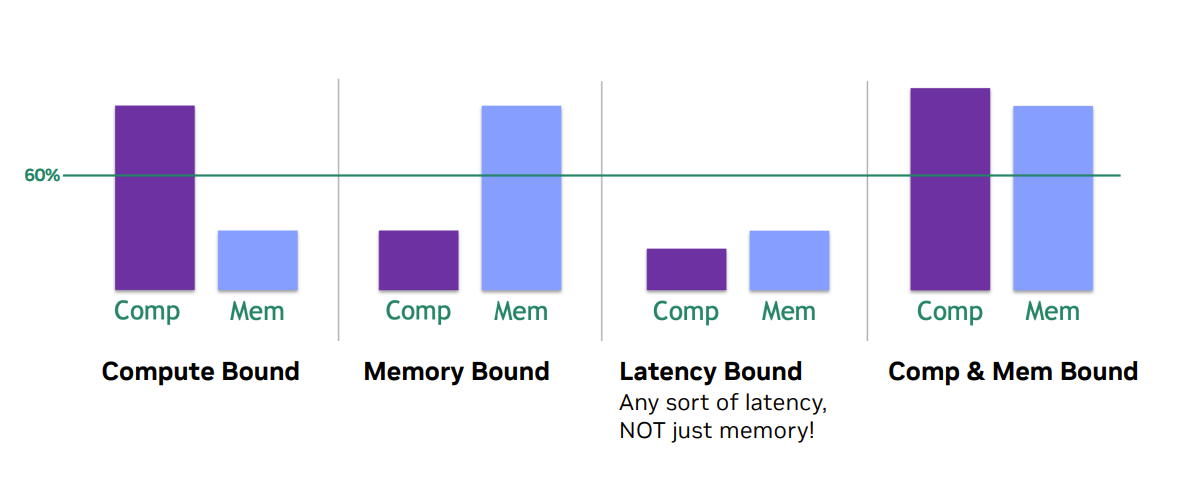
其中,Latency Bound是最糟糕的情况。既没有充分利用计算资源,也没有跑满内存带宽。程序的执行速度受限于各种操作的延迟(如内存读取延迟、分支延迟、同步延迟)。由于没有足够的并行工作(Warp)来隐藏这些延迟,导致GPU的执行单元大部分时间处于空闲等待状态。优化手段包括:
- 增加
occupancy(减少寄存器/共享内存占用、调整 block 大小)、增加并行度; - 减少同步与串行化:减少
__syncthreads()、减少热点原子; - 降低依赖链:插入独立计算、流水化/双缓冲,或增加流水深度;
- 减少发散:数据重排、warp 内路径一致;
Comp & Mem Bound,最理想的状态,性能已接近硬件的Roofline,意味着已经成功地将程序的计算和内存利用都推向了硬件的极限。系统同时处于计算和带宽的饱和状态。
2.3. ncu 中相关 Page 页面
首先,使用GPU Speed of Light页面总体区分是否存在性能优化空间,以及性能瓶颈的类型。
Speed Of Light (SOL) Throughput给出是compute bound还是memory bound,或者latency bound。
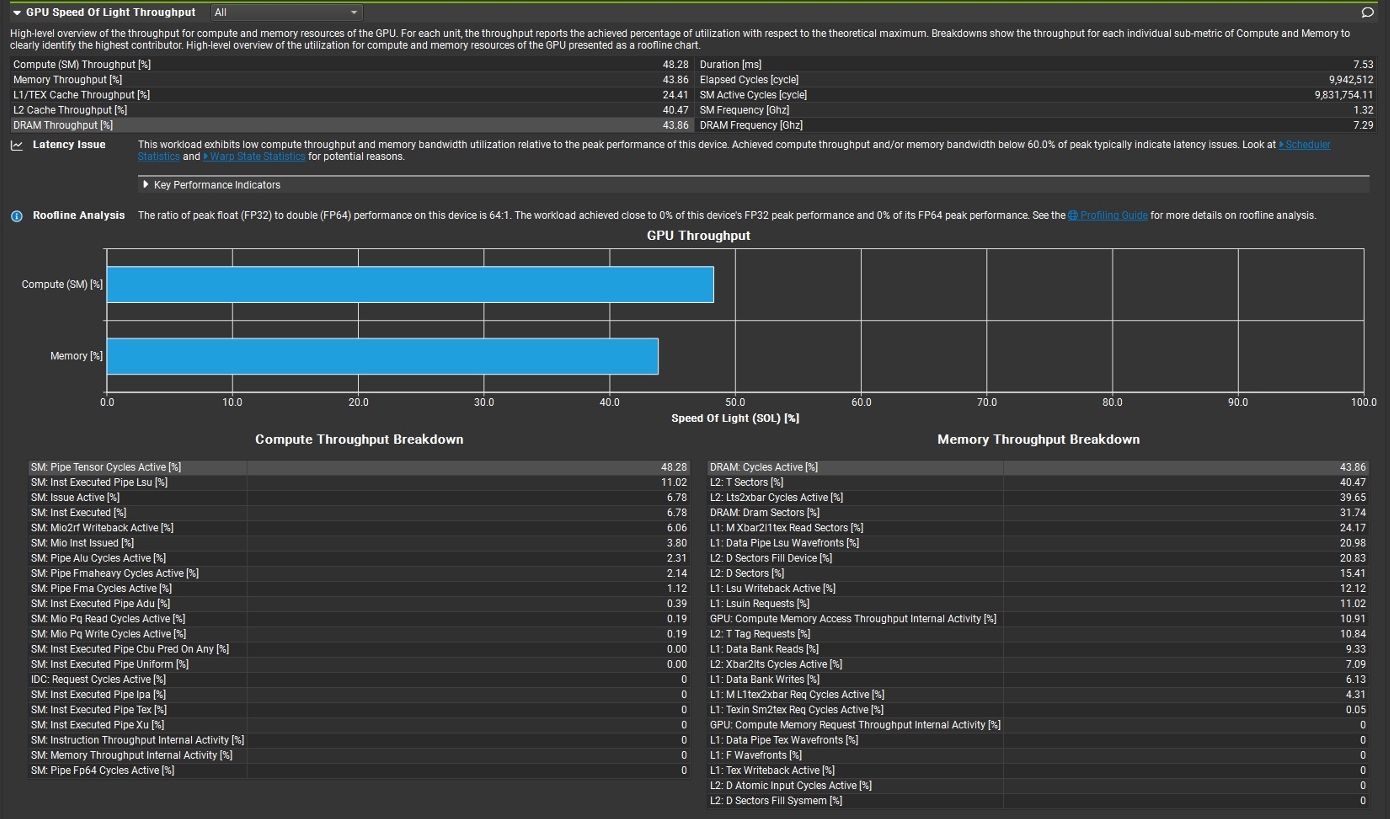
如上图中,红圈中的占比数值对应上面表格中的蓝色条。百分比小的性能指标,表示数据量小,或者复用率高。
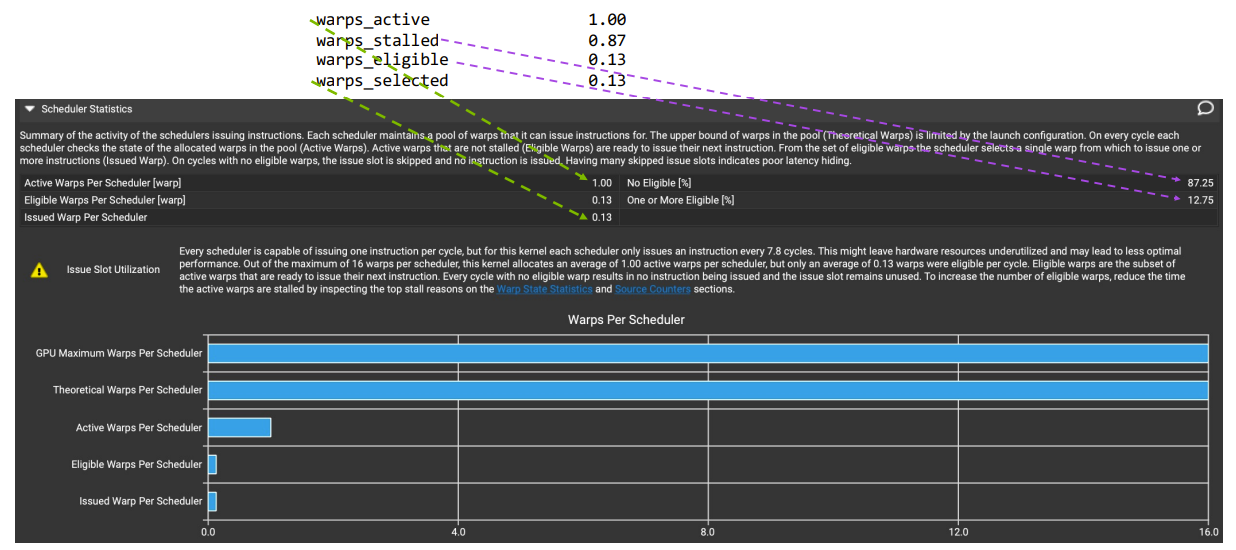
Scheduler statistics页面给出warp调度状态统计信息:Stall占比、Eligible(就绪)占比、Select(被选中)占比等。
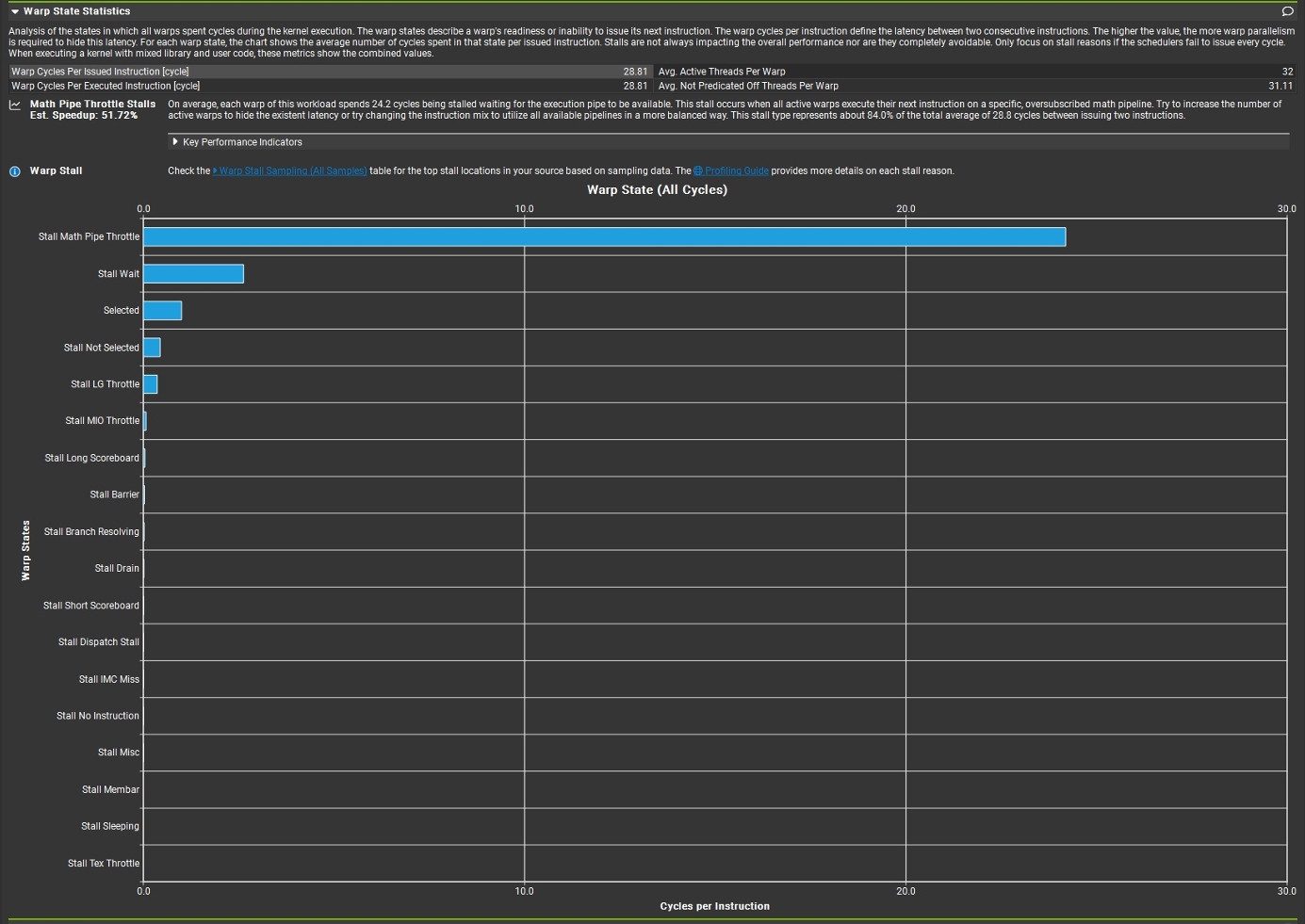
Warp State Staticstics则给出了具体Stall占比,即性能瓶颈的来源。
2.4. Source Page 中的性能指标
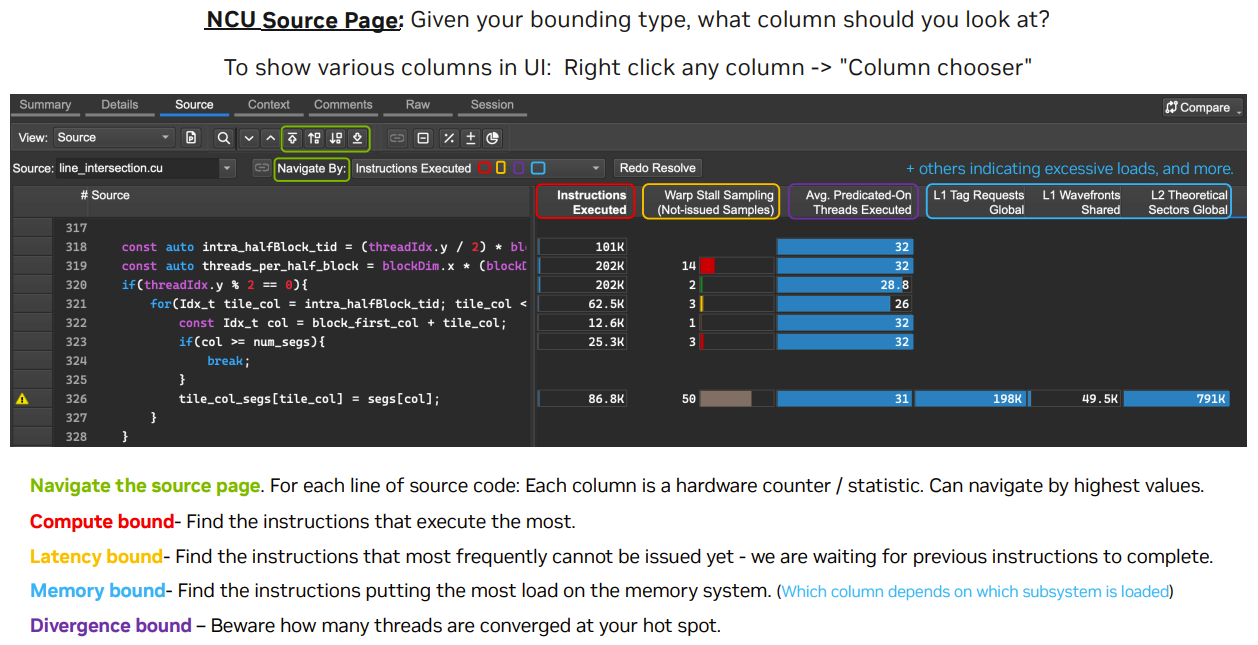
📝在
Source Page页面中,查看瓶颈的对应的代码/汇编,比如:
Compute Bound:查看Instructions Executed(指令执行栏),并通过菜单栏定位到占比最多的指令;Memory Bound:查看L1 Tag Requests Global/L1 Wavefronts Shared/L2 Theotetical Sectors Global等栏目;Latency Bound:查看Warp Stall Samplining(Not issued Samplies)栏目;

📝对一些Stall比较长的计算指令,使用
Scoreboard Dependencies查看其依赖的指令和资源,从而分析瓶颈原因。(Scoreboard即记分牌,有专门的硬件记录指令的状态,比如在等待从内存加载数据)
3. Roofline 模型
Roofline模型是一个性能分析工具,用于评估程序的性能瓶颈。它将程序的性能限制分为两类:计算限制(Compute Bound)和内存限制(Memory Bound)。通过分析程序的算术强度(Arithmetic Intensity)和硬件的计算能力与内存带宽,可以确定程序是受计算资源限制还是内存带宽限制。
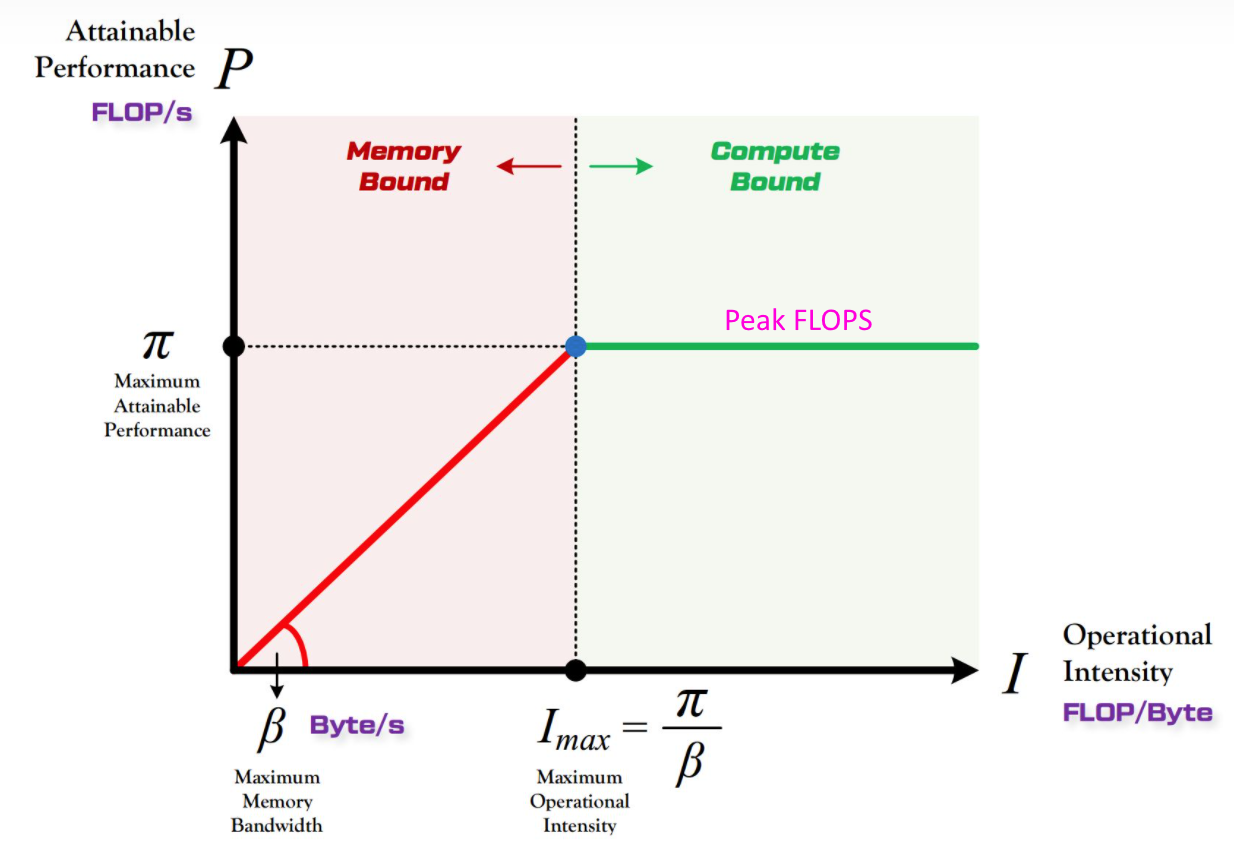
其中:
- $\pi$:理论计算性能峰值,单位为
FLOPS或FLOP/s(每秒浮点运算次数)。 - $\beta$:理论内存带宽峰值,单位为
Bytes/s(每秒字节数)。 - $I$:算术强度,单位为
FLOP/Byte(每字节的浮点运算次数)。 - $P$:当前$I$能达到的性能,单位为
FLOPS或FLOP/s。
Roofline限制线描述的是:
- 当数据搬运的速度比较小的时候,此时计算在等待数据,性能受内存带宽限制(Memory Bound),性能随算术强度$I$线性增长。
- 当数据搬运速度达到一定程度时,计算速度达到理论峰值,此时性能受计算资源限制(Compute Bound),性能达到平台的计算峰值$\pi$,不再随算术强度$I$增加。
用公式描述Roofline的这两段瓶颈区如下:
或者:
\[P = \begin{cases} \beta \cdot I & \text{if } I < I_{max} & \text{Memory Bound} \\ \pi & \text{if } I \geq I_{max} & \text{Compute Bound} \end{cases}\] \[I_{max} = \frac{\pi}{\beta}\]补充理解:当实际点落在斜坡线上时,说明程序的数据搬运比较慢:没有合并访存,
L1/L2 Cache Miss比较高等原因。
3.1. Roofline演示1
定位性能瓶颈类型:
- 落在带宽斜坡 → 内存受限(Memory Bound)
- 落在算力平顶 → 计算受限(Compute Bound)
- 两者都远未达到 → 延迟受限(Latency Bound)
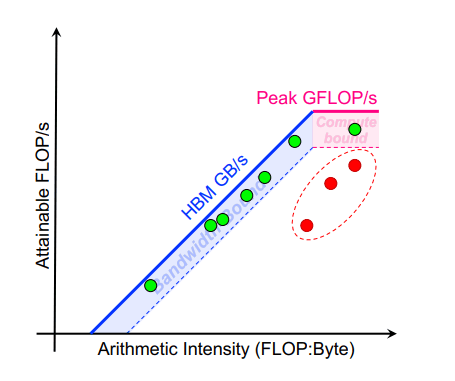
图中,红色点表示Latency Bound,即FLOPS上不去,瓶颈可能来自:
- 内存访问延迟,如
L1/L2 Cache Miss较高,没有合并访存; - 指令延迟,如指令依赖,或者分支发散严重(此时
issue Slot Utilization较低); -
SM occupancy较低,无法隐藏指令/内存访问的延迟; - 同步开销,如
__syncthreads()过多,原子操作等; - 存在非FMA计算;
3.2. Roofline 瓶颈优化
3.2.1. Memory Bound 时重点查看
| NCU 指标 | 问题信号 | 对应优化方向 |
|---|---|---|
| Global Load/Store Efficiency | < 100% | 未合并访问,检查 SoA/AoS、对齐、stride |
| L1 Hit Rate | 过低 | 数据局部性差,考虑 tiling / __ldg() |
| L2 Hit Rate | 过低 | 工作集超出 L2;考虑 L2 persistence / 减小 tile |
| Shared Memory Efficiency | < 100% | 存在 bank conflict |
| DRAM Throughput | 接近峰值但 kernel 仍慢 | 已达带宽极限,需减少访存量(fusion / 算法改进) |
| Sectors/Request | > 1(理想值为 1) | 未对齐或未合并 |
| Stall Long Scoreboard | 高 | 全局内存访问延迟未隐藏 |
3.2.2. Compute Bound 时重点查看
| NCU 指标 | 问题信号 | 对应优化方向 |
|---|---|---|
| Branch Efficiency | < 100% | 分支发散 |
| Eligible Warps Per Cycle | 过低 | ILP 不足或 occupancy 过低 |
| Issue Slot Utilization | < 50% | 指令调度不饱和 |
| FP32/FP16/Tensor Pipe Utilization | 不均衡 | 未使用合适的计算管线(如该用 Tensor Core 没用) |
| Register Spill (Local Memory) | > 0 | 寄存器溢出 |
3.2.3. Latency Bound 时重点查看
| NCU 指标 | 问题信号 | 对应优化方向 |
|---|---|---|
| Occupancy (Achieved vs Theoretical) | 差距大 | 寄存器 / Shared Memory 用量过高 |
| Stall Reasons 面板 | 高 Stall Not Selected / Stall Barrier | 同步开销过大 |
| Stall Long Scoreboard | 高 | 全局内存延迟未隐藏 |
| Stall Short Scoreboard | 高 | Shared Memory / L1 延迟未隐藏,special math instructions (MUFU)、dynamic branching (BRX/JMX) |
| Stall LG Throttle(LG 指令队列满) | 高 |
A. 资料
- CUDA Techniques to Maximize Compute and Instruction Throughput
- CUDA Techniques to Maximize Compute and Instruction Throughput(pdf)
- HOW TO UNDERSTAND AND OPTIMIZE SHARED MEMORY ACCESSES USING NSIGHT COMPUTE(S41723)(pdf)
A.1. Roofline 模型资料
- Roofline Model与深度学习模型的性能分析
- 手把手建立Roofline模型(CPU)
- Roofline模型
- CUDA 算子迭代优化方案(NCU 驱动)
- Profiling Guide:官方文档
- GTC Silicon Valley-2019: Performance Analysis of GPU-Accelerated Applications using the Roofline Model
- GTC Silicon Valley-2019: Performance Analysis of GPU-Accelerated Applications using the Roofline Model(pdf)
Enjoy Reading This Article?
Here are some more articles you might like to read next: