CUTLASS-Cute 初步(2.1):Tensor & Layout 实操笔记
1. local_tile
给定一个 tiler,使用 local_tile 函数,将 Tensor 按 tiler 的 shape 切分成多个 tile。由于切分之后,每个 tile 保留输入 Tensor 的stride信息,以及rest mode的shape,故称为Inner-Partition。
1.1. 示例一:常规使用(常规 CTA 切分)
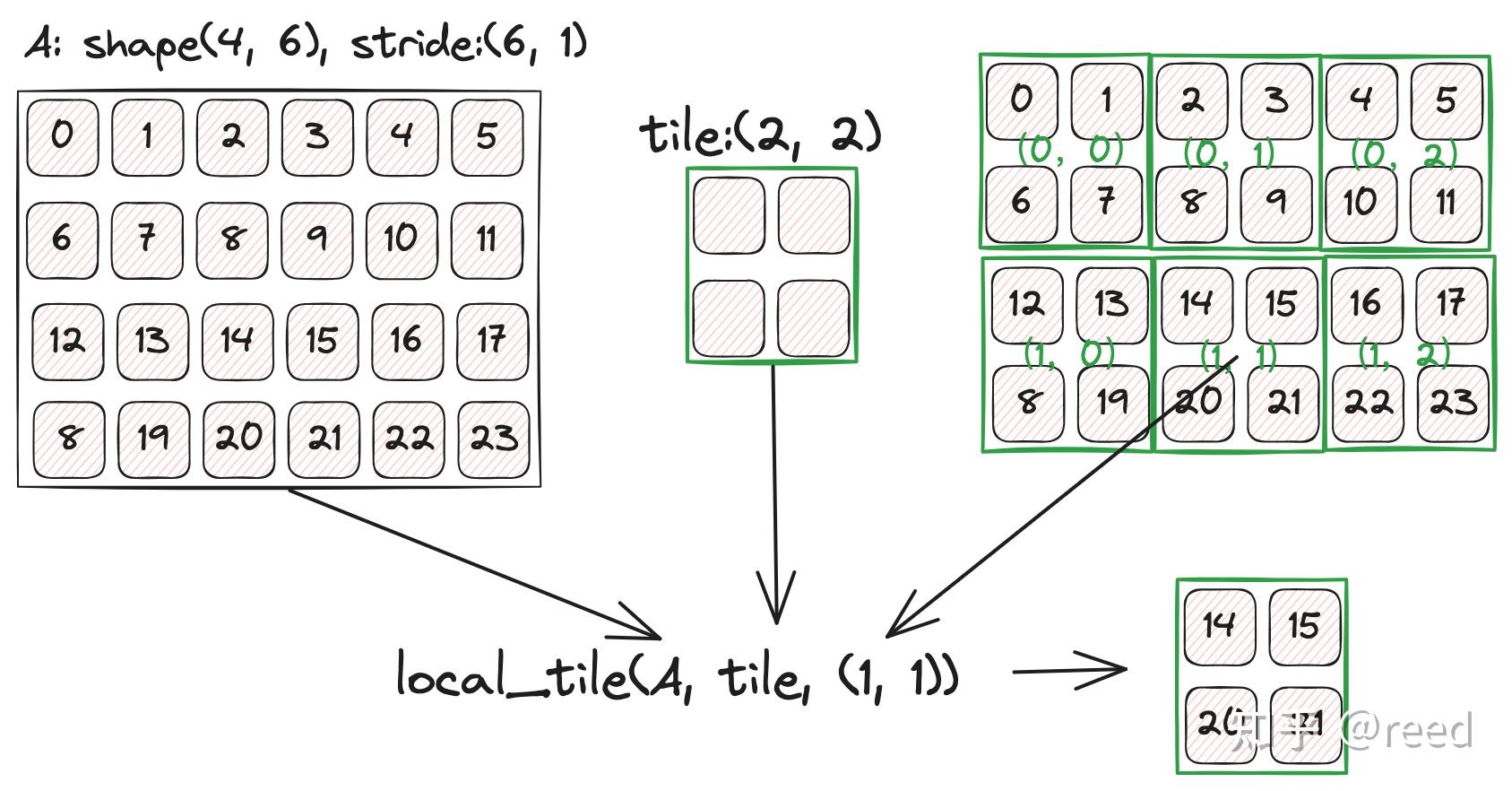
比如有一个 4x6 的 Tensor,将其切分并分配到 thread block,每个 thread block 获取到的 tile 大小为 (2,2),当前 thread block 的 coord 为 (1,1),就可以使用如下代码:
constexpr int M = 4, N = 6;
auto layout = cute::make_layout(cute::make_shape(M, N), cute::make_stride(N, cute::Int<1>{}));
auto tensor = cute::make_tensor(h_data.data(), layout);
constexpr auto tiler = cute::make_shape(cute::Int<2>{}, cute::Int<2>{});
constexpr auto coord = cute::make_coord(1, 1); // 第(1,1)块(0-indexed)
auto tile = cute::local_tile(tensor, tiler, coord);
cute::print(tile);
输出:
ptr[32b](0xaaaafc5faa38) o (_2,_2):(6,_1)
图示如下:
1.1.1. 输入 Tensor 轴数量多余于 tiler 的轴数量
下面测试输入 Tensor 轴数量多余于 tiler 的轴数量。测试代码:
constexpr int M = 4, N = 6, K = 8;
auto layout = cute::make_layout(cute::make_shape(M, N, K), cute::make_stride(N * K, K, cute::Int<1>{}));
auto tensor = cute::make_tensor(h_data.data(), layout);
constexpr auto tiler = cute::make_shape(cute::Int<2>{}, cute::Int<2>{});
constexpr auto coord = cute::make_coord(1, 2);
auto tile12 = cute::local_tile(tensor, tiler, coord);
cute::print(tile12);
输出:
ptr[32b](0xaaab0eebc6f0) o (_2,_2,8):(48,8,_1)
1.1.2. 总结
local_tile的逻辑是:首先使用zipped_divide将输入 Tensor 切分,比如 输入 Tensor:(4,6,8):(48,8,1),使用 tiler(2,2)切分,得到:zipped_divide得到的结果是((_2,_2),(2,3,8)):((48,8),(96,16,_1))。 其中(_2,_2)表示每个 tile 的 shape 是 (2,2),(2,3,8)表示每个 tile 的 rest mode shape 是 (2,3,8),(48,8)表示每个 tile 的 stride 是 (48,8),(96,16,_1)表示每个 tile 的 rest mode stride 是 (96,16,_1)。最后根据 coord 获取对应的 tile。
zipped_divide返回一个 rank-2 的 tensor:
([tile mode], [rest mode])
| 顶层 mode | 内容 | 含义 |
|---|---|---|
| tile mode (mode-0) | (_2,_2):(48,8) | 一个 tile 内部的坐标系:2×2 个元素,stride 保留自原 tensor |
| rest mode (mode-1) | (2,3,8):(96,16,_1) | tile 外部的坐标系:有多少个 tile,以及未被切分的 trailing 维度 |
“rest”的字面意思是剩余,指”tile 坐标系之外剩下的所有东西”:
- 已切分维度的块编号(你选哪一块?→ 2 个 M 块 × 3 个 N 块)
- 未切分维度的完整范围(K=8 没有被 tiler 动过,直接挂在 rest 末尾)
如何切分,与 stride 没有关系,即选择前两个轴来切分,不是依照 stride 来选择轴(即与内存布局没有关系)。
完整测试代码:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/study_tests/test_local_tile.cu中的 Case03。
1.2. 示例二:在 coord 中使用 cute::_,得到该轴方向上的 tile 集合
使用cute::_作用于 coord 中的某个轴,其含义是获取该轴方向上的 tile 集合,即在该轴方向上,生成新的 trailing mode。示例代码如下:
constexpr int M = 4, N = 6;
auto layout = cute::make_layout(cute::make_shape(M, N), cute::make_stride(N, cute::Int<1>{}));
auto tensor = cute::make_tensor(h_data.data(), layout);
constexpr auto tiler = cute::make_shape(cute::Int<2>{}, cute::Int<2>{});
constexpr auto coord = cute::make_coord(0, cute::_);
auto tile00 = cute::local_tile(tensor, tiler, coord); // (tileM, tileN, k)
cute::print(tile00);
输出:
ptr[32b](0xaaaafd59bed0) o (_2,_2,3):(6,_1,_2)
从结果看到,在第二个轴上使用 slice 操作符,shape 中的最后一个轴 3 表示在该轴上有 3 个 tile。
完整测试代码:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/study_tests/test_local_tile.cu中的 Case04。
1.3. 示例三:tiler 中使用 Step筛选 tiler 以及 coord,使用 cute::X 标记的轴不参与切分
Step 本质上是一个轴选择器,筛选出需要的 tiler 以及 coord,使用 cute::X 标记的轴不参与切分。
constexpr int M = 4, N = 6, K = 8;
constexpr auto problem_shape = cute::make_shape(M, N, K);
auto stride_A = cute::make_stride(K, cute::Int<1>{});
auto layout_A = cute::make_layout(cute::select<0, 2>(problem_shape), stride_A);
auto tensor_A = cute::make_tensor(h_data.data(), layout_A);
constexpr auto tiler = cute::make_shape(cute::Int<2>{}, cute::Int<2>{}, cute::Int<4>{});
constexpr auto coord = cute::make_coord(0, 0, cute::_);
// tile_A (tileM, tileK, k)
auto tile_A = cute::local_tile(tensor_A, tiler, coord, cute::Step<cute::_1, cute::X, cute::_1>{});
print_tile(tile_A);
输出:
ptr[32b](0xaaaafe0c3860) o (_2,_4,2):(8,_1,_4)
即得到一个 MK 方向的 tile(2, 4) 的集合,K 方向上有两个 tile,这两个 tile 在 M 方向上坐标为 0(划分成 2*2 个分块)。
另外,在 cute::Step<> 中使用 cute::X 标记的轴不参与切分,例如:
// tiler rank=2,Step<_1,X> 表示只切第0维,第一维整体保留
local_tile(tensor, make_shape(Int<2>{}), coord_m, Step<_1, X>{});
A. 资料
Enjoy Reading This Article?
Here are some more articles you might like to read next: