CUTLASS-Cute 初步(3):TiledCopy 以及 TiledMMA
- tiled_copy.cu:官方示例
1. Cute TiledCopy
层次化的 copy 抽象,将 Copy_Atom 分为几个可组合的层次:
- CopyOperation:NVidia在不同的硬件架构、不同的存储层次之间数据搬运提供了不同的指令,如 ldmatrix 和 LDS 等,还有针对Ampere架构的 cp.async 等。
- Copy_Traits:和 MMA_Traits 类似,提供了 CopyOperation 类型没有提供,但是其使用者 Copy_Atom 却需要的起到桥梁作用的信息;
- Copy_Atom:封装了基本的拷贝指令,针对 SRC-DST 的一次搬运;
TiledCopy 则根据提供的 LayoutCopy_TV 执行 Copy_Atom,可能需要重复多次的 atom 搬运操作。
1.1. Copy_Atom
Copy_Atom 封装基本的拷贝指令,所以叫 Atom,即针对 SRC-DST 的一次搬运。适配不同的硬件指令集,比如通用拷贝/向量化 UniversalCopy<…>,cp.async(Ampere架构)。
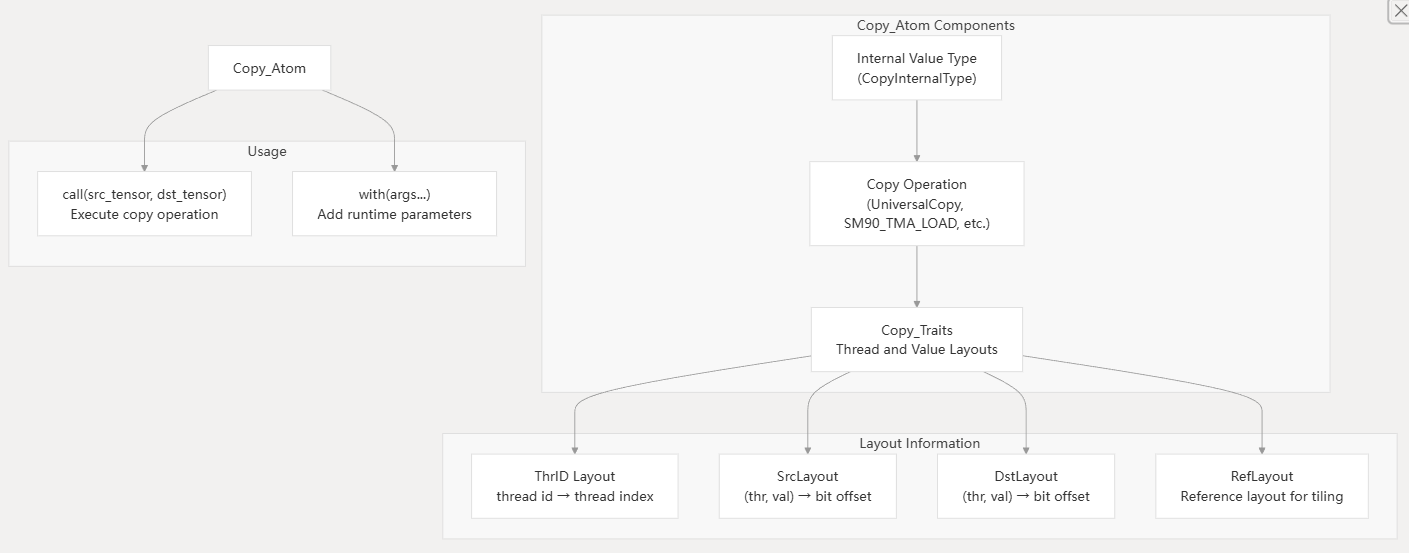
需要关注的两个模板参数是:CopyOperation 和 Copy_Traits。CopyOperation 定义了具体的拷贝指令,而 Copy_Traits 定义了拷贝的元信息,比如每次拷贝多少个元素(元素类型),SRC-DST 的 Layout 等。不同平台,实现不同的 Copy_Traits。(个人理解:一些 copy 操作也需要用到 layout 信息,以及 bits 位宽等信息)
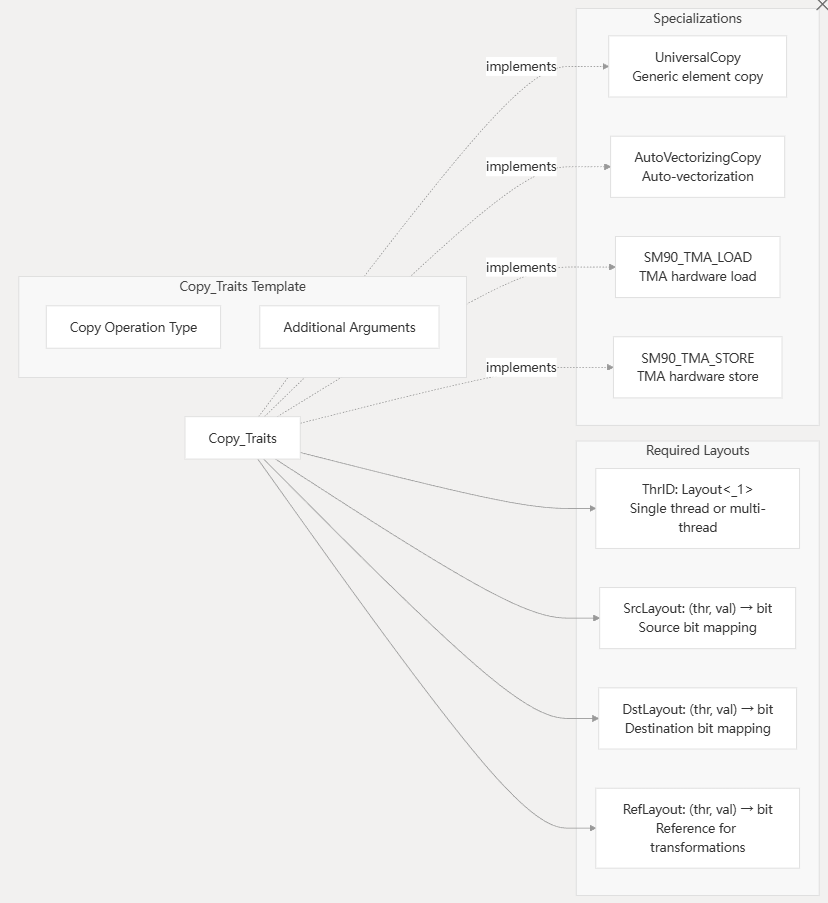
部分代码实现文件列表:
- cute/atom/copy_atom.hpp – Copy_Atom
- cute/atom/copy_traits.hpp – copy_unpack
- cute/atom/copy_traits.hpp – Copy_Traits
- cute/arch/copy_sm90.hpp:针对 SM90 架构的 Copy_Traits 实现
1.2. TiledCopy
TiledCopy 封装 Copy_Atom,根据 LayoutCopy_TV 执行 Copy_Atom,可能需要重复多次的 atom 搬运操作。其 template 参数有:
- LayoutCopy_TV:定义 Thread Layout,以及 Value Layout;
- ShapeTiler_MN:切分器的 shape;
- Copy_Atom:定义复制指令;
ThrCopy 完成实际的生成线程对应的 tensor(软件工程功能划分需要,剥离出来的功能模块)。
1.3. make_tiled_copy
提供工厂函数,提供 thr_layout、val_layout、CopyOperation 参数生成 TiledCopy 实例。其中,thr_layout、val_layout 分别定义线程划分 layout 和每个线程拷贝数据的 layout。
make_tiled_copy(copy_atom, thr_layout, val_layout)
1.4. copy 执行
copy 函数是拷贝的实际执行函数,完成线程指令的执行:
void copy(TiledCopy const& copy, Tensor const& src, Tensor& dst);
void copy_if(TiledCopy const& copy, PrdTensor const& pred, Tensor const& src, Tensor& dst);
1.5. 可视化工具
2. MMAAtom 以及 TiledMMA
分块 MMA 抽象,将 MMA_Atom 分为几个可组合的层次:
- MMAOperation:封装 D=A*B + C 的指令封装,以使用不同的数据类型以及 PTX 指令,包括使用 CUDA Core / Tensor Core。如 UniversalFMA<>、SM80_16x8x8_F32F16F16F32_TN。
- MMA_Traits:和 Copy_Traits 类似,提供了 MMAOperation 类型没有提供,但是其使用者 MMA_Atom 却需要的起到桥梁作用的信息。如数据类型信息,TV layout 信息。
- MMA_Atom:将 MMAOperation 和 MMA_Traits 结合,并提供 fragment 划分接口。
- TiledMMA:根据 LayoutTile_TV 切分的线程布局,重复使用 MMA_Atom 完成分块矩阵乘加计算。
- ThrMMA:完成实际的生成线程对应的 tensor。
2.1. MMAOperation
以SM80_16x8x8_F32F16F16F32_TN为例,封装了 SM80 架构下,16x8x8 大小的矩阵乘加指令 D=A * B + C,数据类型为 A:F16、B:F16、C:F32、D:F32。A 矩阵 row-major,B 矩阵 column-major。
BLAS 中约定 normal 矩阵为列优先。T(transpose) 表示使用转置矩阵,即 row-major 存储。 下图原图见 Thakkar_BLISRetreat2023.pdf 第 30 页。
SM80_16x8x8_F32F16F16F32_TN 对应的 inverse TV-Layout 如下:
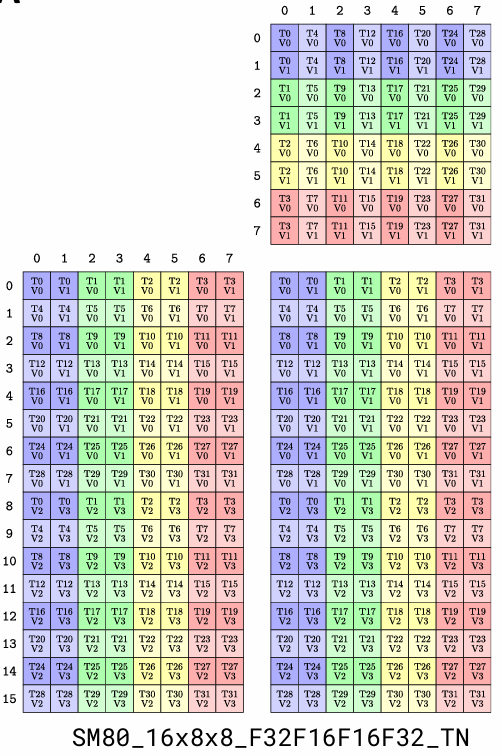
inverse TV-Layout 表示 element coordinate -> thread index的映射关系。
SM80_16x8x8_F32F16F16F32_TN 对应的 MMA_Atom 信息如下:
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_16,_8,_8)
LayoutA_TV: ((_4,_8),(_2,_2)):((_32,_1),(_16,_8))
LayoutB_TV: ((_4,_8),_2):((_16,_1),_8)
LayoutC_TV: ((_4,_8),(_2,_2)):((_32,_1),(_16,_8))
对应的代码如下:
print(MMA_Atom<SM80_16x8x8_F32F16F16F32_TN>{});
// using MMA = MMA_Traits<SM80_16x8x8_F32F16F16F32_TN>;
// print("ALayout: "), print(typename MMA::ALayout{}), print("\n");
// print("BLayout: "), print(typename MMA::BLayout{}), print("\n");
// print("CLayout: "), print(typename MMA::CLayout{}), print("\n");
MMA_Atom<SM80_16x8x8_F32F16F16F32_TN> mma;
print_latex(mma);
/* 或者如下写法
TiledMMA tiled_mma = make_tiled_mma(SM80_8x8x4_F64F64F64F64_TN{});
print_latex(tiled_mma);
*/
- TODO: SM80_16x8x8_F32F16F16F32_TN 一条指令处理几个数据?
- TODO:Tensor Core 的指令是什么,对应的布局是什么规则?
CUDA PTX 文档也给出了指令 m16n8k8 的布局信息:9.7.14.5.7. Matrix Fragments for mma.m16n8k8。
2.2. MMA_Traits
MMA_Traits 提供数据类型信息,以及 TV layout 信息,比如需要根据 MMAOperation 中定义的指令,补充 A/B/C 的 layout 信息。需要提供的信息如下:
using ElementDVal = // Logical A-value type
using ElementAVal = // Logical B-value type
using ElementBVal = // Logical C-value type
using ElementCVal = // Logical D-value type
using ElementAFrg = // A-type consumed by MMA (if ommitted, same as ElementAVal)
using ElementBFrg = // B_type consumed by MMA (if ommitted, same as ElementBVal)
using ElementCFrg = // C_type consumed by MMA (if ommitted, same as ElementCVal)
using Shape_MNK = // Logical MxNxK shape of the MMA
using ThrID = // Logical thread id (tid) -> tidx
using ALayout = // (Logical thread id (tid), Logical value id (vid)) -> Flat MK-coord
using BLayout = // (Logical thread id (tid), Logical value id (vid)) -> Flat NK-coord
using CLayout = // (Logical thread id (tid), Logical value id (vid)) -> Flat MN-coord
2.3. MMA_Atom
MMA_Atom 封装了 MMAOperation 和 MMA_Traits。
创建寄存器 fragment
提供了创建寄存器 fragment 的接口 make_fragment_A/B/C:
template <class CTensor>
static constexpr auto make_fragment_C(CTensor&& ctensor);
template <class ATensor>
static constexpr auto make_fragment_A(ATensor&& atensor);
template <class BTensor>
static constexpr auto make_fragment_B(BTensor&& btensor);
调用 FMA 指令
提供 call 接口,调用 MMAOperation 指令:
template <class TD, class DLayout,
class TA, class ALayout,
class TB, class BLayout,
class TC, class CLayout>
constexpr void call(Tensor<TD, DLayout>& D,
Tensor<TA, ALayout> const& A,
Tensor<TB, BLayout> const& B,
Tensor<TC, CLayout> const& C) const;
- TODO: 调用之前进行一个 unpack 操作?
2.4. TiledMMA
TiledMMA 的模版参数表达了 TiledMMA 在 MMA_Atom 上的扩展逻辑:AtomLayoutMNK 表示 M、N、K 方向上分别重复几次 Atom,这种重复会要求更多的执行线程。get_slice、get_thread_slice 函数功过给定线程 id 则获取线程对应到 ThrMMA 结构。
template <class MMA_Atom,
class AtomLayoutMNK,
class PermutationMNK = Tile<Underscore,Underscore,Underscore>>
struct TiledMMA : MMA_Atom {
auto get_slice(ThrIdx const& thr_idx) const {
auto thr_vmnk = thr_layout_vmnk_.get_flat_coord(thr_idx);
return ThrMMA<TiledMMA, decltype(thr_vmnk)>{*this, thr_vmnk};
}
auto get_thread_slice(ThrIdx const& thr_idx) const {
return get_slice(thr_idx);
}
auto thrfrg_C(CTensor&& ctensor) const {
....
}
};
三个模板参数的含义:
| 参数名 | 类型 | 说明 |
|---|---|---|
| MMA_Atom | 底层指令 | 定义单条 MMA 指令涉及的线程和值的布局 |
| AtomLayoutMNK | Layout<Shape<_2,_2,_1>> | 在 M/N/K 方向上重复多少个 atom(分配更多线程) |
| PermutationMNK | Layout<Shape<_1,_2,_1>> | 每个线程在 M/N/K 方向上处理更多的值(不增加线程) |
AtomLayoutMNK 决定如何将 MMA_Atom 复制到更多的线程上执行,且将 MMA_ATOM 处理的线程扩展为 size(AtomLayoutMNK) 倍数。PermutationMNK 决定每个线程如何处理更多的值(即哪些逻辑坐标位置的值)。
3.4 之前版本还有 ValLayoutMNK 参数,从 3.4 版本开始 去掉该模板参数。PermutationMNK 可以替代 ValLayoutMNK 的功能。即 AtomLayoutMNK 定义 Thread 扩展,PermutationMNK 定义 Value 级别的扩展,即执行多次 Atom,使用 PermutationMNK 导致线程需要占用更多的寄存器。
PermutationMNK 的展开讲述见下面章节。
2.4.1. 四层 Layout 以及获取线程 fragment
根据给定的 MMA_Atom、以及 AtomLayoutMNK 参数,生成一个四层 Layout 结构:
using ThrLayoutVMNK = decltype(tiled_product(AtomThrID{}, AtomLayoutMNK{}));
ThrLayoutVMNK thr_layout_vmnk_;
- Mode 0 (V): Threads within a single atom
- Mode 1 (M): Atom tiles in M dimension
- Mode 2 (N): Atom tiles in N dimension
- Mode 3 (K): Atom tiles in K dimension
以 thrfrg_A 为例:
// Tile a tensor or a layout from shape
// (M,K,...)
// to shape
// ((ThrV,(ThrM,ThrK)),(FrgV,(RestM,RestK,...)))
// where
// ThrV: The threads local to an MMA. layout<0>(ThrLayoutVMNK): ThrV -> thread_idx
// ThrM: The threads tiled in M. layout<1>(ThrLayoutVMNK): ThrM -> thread_idx
// ThrK: The threads tiled in K. layout<3>(ThrLayoutVMNK): ThrK -> thread_idx
// FrgV: The values local to an MMA.
// RestM: The values tiled in M.
// RestK: The values tiled in K.
template <class ATensor>
constexpr auto thrfrg_A(ATensor&& atensor) const;
即得到的线程切分后的 subtile 布局为 ((ThrV,(ThrM,ThrK)),(FrgV,(RestM,RestK,…)))。
2.5. ThrMMA
TiledMMA 根据具体的线程 id 分解得到 ThrMMA 结构,提供 partition 函数接口,以及 partition_fragment 函数接口。
如 Tensor C 为 BLK_M x BLK_N,则 partition_C 可以得到线程级别的任务,维度为 (MMA, MMA_M, MMA_N), MMA 表达了 TileMMA 一次能计算的单元,MMA_M, MMA_N 表达了 M 方向和 N 方向需要分块数量。
partition_fragment 类函数是按照 partition 类函数返回的 Tensor 形状生成的对应的寄存器表示。
template <class TiledMMA, class ThrVMNK>
struct ThrMMA : TiledMMA {
Tensor partition_C(Tensor C);
Tensor partition_A(Tensor A);
Tensor partition_B(Tensor B);
Tensor partition_fragment_C(Tensor C);
Tensor partition_fragment_A(Tensor A);
Tensor partition_fragment_B(Tensor B);
}
2.6. Permutation:置换
Permutation 是一个 Tiler,由三个独立的分量组成,分别作用于 M、N、K 维度。它在 TV-layout 分配之前,对逻辑坐标进行重新映射。以 SM80_8x8x4_F64F64F64F64_TN 为例,其 inverse TV-Layout 如下:
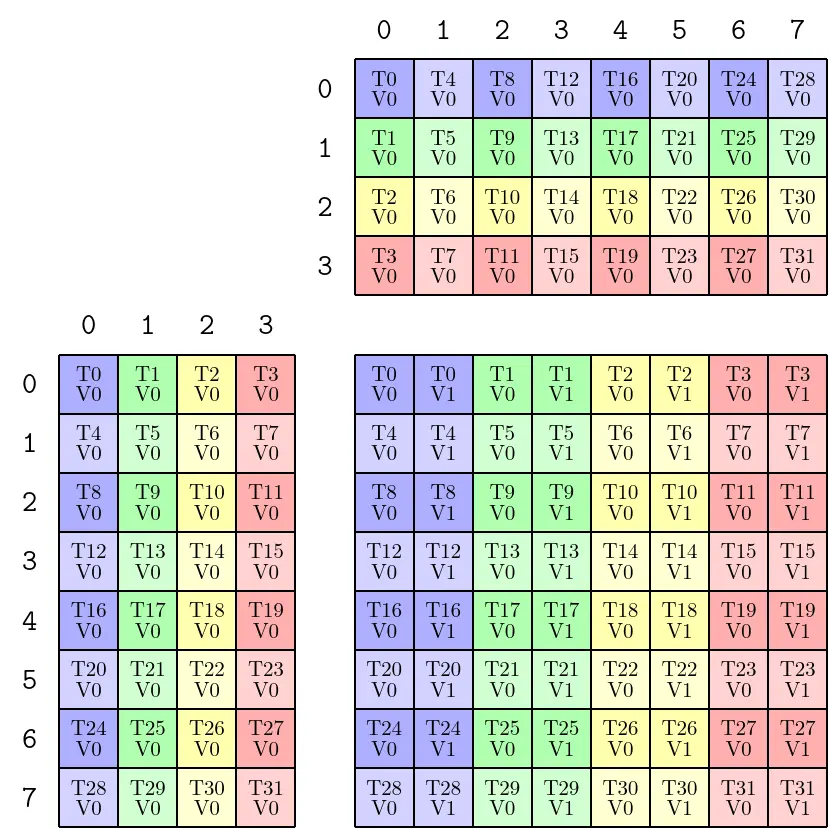
TiledMMA
ThrLayoutVMNK: (_32,_1,_1,_1):(_1,_0,_0,_0)
PermutationMNK: (_,_,_)
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_8,_8,_4)
LayoutA_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutB_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutC_TV: ((_4,_8),_2):((_16,_1),_8)
代码如下:
TiledMMA tiled_mma = make_tiled_mma(SM80_8x8x4_F64F64F64F64_TN{});
/* TiledMMA tiled_mma = make_tiled_mma(SM80_8x8x4_F64F64F64F64_TN{}, Layout<Shape<_1, _1, _1>>{}, Tile<_8, _8, _4>{}); */
print(tiled_mma), print("\n");
/*print("ALayout: "), print(typename decltype(tiled_mma)::ALayout{}), print("\n");
print("BLayout: "), print(typename decltype(tiled_mma)::BLayout{}), print("\n");
print("CLayout: "), print(typename decltype(tiled_mma)::CLayout{}), print("\n");*/
std::cout << "\nMMA Atom Layout:" << std::endl;
print_latex(tiled_mma);
使用 permutation 参数将线程处理的单元 size 修改为 8x16x8,即 N、K 方向扩大为两倍,M 方向不变:
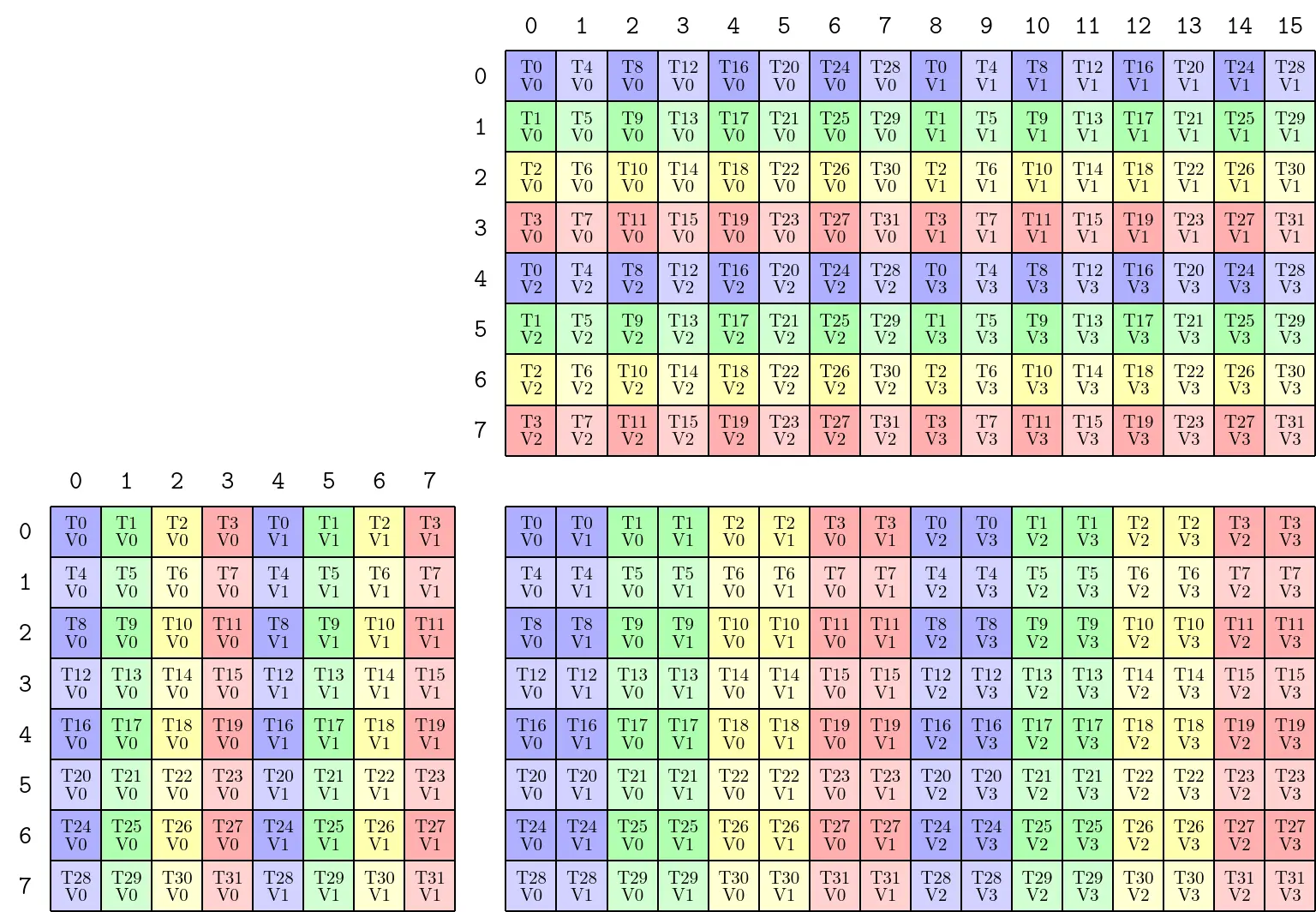
TiledMMA
ThrLayoutVMNK: (_32,_1,_1,_1):(_1,_0,_0,_0)
PermutationMNK: (_8,_16,_8)
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_8,_8,_4)
LayoutA_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutB_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutC_TV: ((_4,_8),_2):((_16,_1),_8)
代码如下:
TiledMMA tiled_mma = make_tiled_mma(SM80_8x8x4_F64F64F64F64_TN{},
Layout<Shape<_1, _1, _1>>{}, // AtomLayout
Tile<_8, _16, _8>{}); // Tiler
print(tiled_mma), print("\n");
/*print("ALayout: "), print(typename decltype(tiled_mma)::ALayout{}), print("\n");
print("BLayout: "), print(typename decltype(tiled_mma)::BLayout{}), print("\n");
print("CLayout: "), print(typename decltype(tiled_mma)::CLayout{}), print("\n");*/
std::cout << "\nMMA Atom Layout:" << std::endl;
print_latex(tiled_mma);
如何理解? This doesn’t actually affect the partitioning of input/output tensors because, by convention, only a single atom is ever partitioned out. It will affect the output of
tile_sizeandget_layoutC_MNandget_layoutC_TVetc, which could affect anyTiledCopythat rely on those partitioning patterns by being built on thisTiledMMA. Regardless, you’ll find the resulting tensors frompartition_Cetc to be exactly the same since the atom partitioning is exactly the same.
2.6.1. 映射重排
上面的例子中,使用的 PermutationMNK:Tile<_8, _16, _8>{},T0划分的逻辑坐标不连续。使用scatter permutation,可以得到连续的逻辑坐标划分,如下代码将对 N-coord 进行重排:
TiledMMA tiled_mma =
make_tiled_mma(SM80_8x8x4_F64F64F64F64_TN{},
Layout<Shape<_1, _1, _1>>{}, // AtomLayout
Tile<_8, // Permutation on M, equivalent to 8:1, identity
Layout<Shape<_2, _4, _2>, Stride<_1, _4, _2>>, // Permutation on N, size 16
_8>{}); // Permutation on K, equivalent to 8:1, identity
print_latex(tiled_mma);
这将对 N 模式重排如下(影响 B、C):
- 前 2 个元素保持原位
- 接下来 4 组(每组 2 个元素)被发送到 n 坐标 4
- 再接下来 2 组(每组 8 个元素)被发送到 n 坐标 2
对应的 layout 如下:
(2,(4,2)):(1,(4,2))
0 1 2 3 4 5 6 7
+----+----+----+----+----+----+----+----+
0 | 0 | 4 | 8 | 12 | 2 | 6 | 10 | 14 |
+----+----+----+----+----+----+----+----+
1 | 1 | 5 | 9 | 13 | 3 | 7 | 11 | 15 |
+----+----+----+----+----+----+----+----+
auto shape = make_shape(2, make_shape(4, 2));
auto stride = make_stride(1, make_stride(4, 2));
print_layout(make_layout(shape, stride)), print("\n");
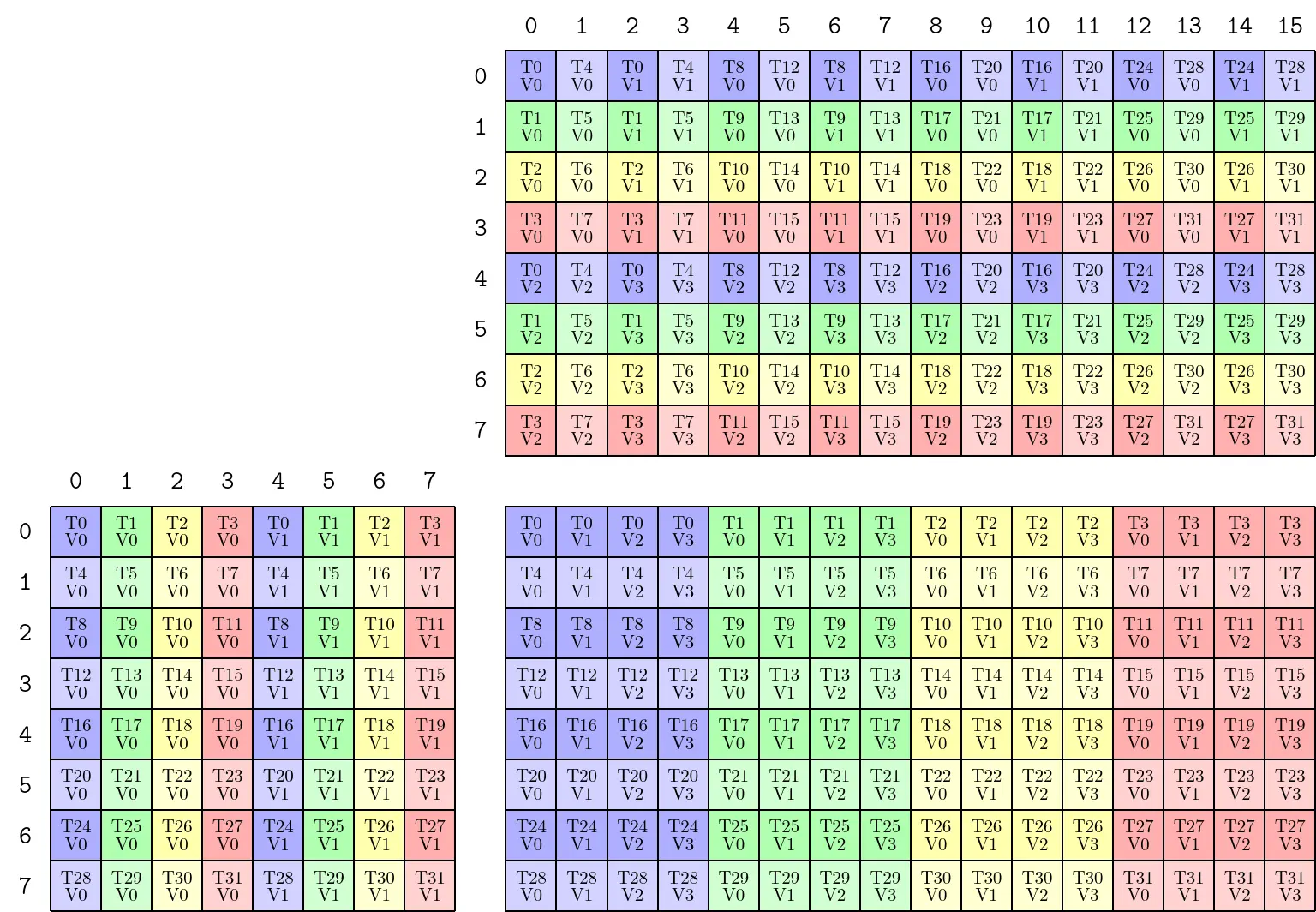
映射重排以获得简洁的内存布局,从而提高内存访问效率,避免 bank conflicts。
2.6.2. 参考资料
- [QST] What is PermutationMNK in TiledMMA in CUTLASS 3.4 changes?
- 02_layout_algebra.md – Logical Divide 2-D Example
- 0t_mma_atom – TiledMMAs
2.7. UniversalFMA
可以参考 Thakkar_BLISRetreat2023.pdf 第 26 页。
UniversalFMA 是一个标量 FMA 操作的 MMAOperation 实现,定义如下:
template <class D, class A = D, class B = A, class C = D>
struct UniversalFMA {
using DRegisters = D[1];
using ARegisters = A[1];
using BRegisters = B[1];
using CRegisters = C[1];
CUTE_HOST_DEVICE static constexpr void
fma(D& d, A const& a, B const& b, C const& c) {
// Forward to an ADL/cute free function for these types
using cute::fma;
fma(d, a, b, c); // 这里的实现就是d = a * b + c;
}
};
template <class D, class A, class B, class C>
struct MMA_Traits<UniversalFMA<D,A,B,C>> {
using ValTypeD = D;
using ValTypeA = A;
using ValTypeB = B;
using ValTypeC = C;
// Logical shape of the MMA
using Shape_MNK = Shape<_1,_1,_1>;
// Logical thread id (tid) -> tidx
using ThrID = Layout<_1>; // 只有一个thread参与
// (Logical thread id (tid), Logical value id (vid)) -> coord
// (tid,vid) -> (m,k)
using ALayout = Layout<Shape<_1,_1>>;
// (tid,vid) -> (n,k)
using BLayout = Layout<Shape<_1,_1>>;
// (tid,vid) -> (m,n)
using CLayout = Layout<Shape<_1,_1>>;
};
参考官方示例函数gemm_nt:https://github.com/NVIDIA/cutlass/blob/main/examples/cute/tutorial/sgemm_sm80.cu#L478,从中提取部分代码如下:
using TA = float;
using TB = float;
using TC = float;
TiledMMA mmaC = make_tiled_mma(UniversalFMA<TC, TA, TB>{}, Layout<Shape<_16, _16, _1>>{}); // 16x16x1 TiledMMA
std::cout << "\nTiledMMA Layouts (UniversalFMA 16 16 1):" << std::endl;
print(mmaC), print("\n");
/*print("ALayout: "), print(typename decltype(mmaC)::ALayout{}), print("\n");
print("BLayout: "), print(typename decltype(mmaC)::BLayout{}), print("\n");
print("CLayout: "), print(typename decltype(mmaC)::CLayout{}), print("\n");*/
std::cout << "\nMMA Atom Layout:" << std::endl;
print_latex(mmaC);
Inverse TV-Layout 如下:

MMA_Atom 信息如下:
TiledMMA
ThrLayoutVMNK: (_1,_16,_16,_1):(_0,_1,_16,_0)
PermutationMNK: (_,_,_)
MMA_Atom
ThrID: _1:_0
Shape_MNK: (_1,_1,_1)
LayoutA_TV: (_1,_1):(_0,_0)
LayoutB_TV: (_1,_1):(_0,_0)
LayoutC_TV: (_1,_1):(_0,_0)
A. 资料
A.1. TiledCopy 资料
- CuTe Tiled Copy:Mao Lei 博客
- cute 之 Copy抽象:reed 知乎文章
- cute/tutorial/tiled_copy.cu:官方示例代码
A.2. MMA Atom 资料
- 0t_mma_atom.md:官方文档,MMA Atom 文档
- cute 之 MMA抽象:reed 知乎文章
- CuTe Tiled MMA:Mao Lei 博客,如何配置 TiledMMA
- Thakkar_BLISRetreat2023.pdf
- MMA Atoms and TiledMMA
A.3. 参考代码
- sm80_mma_multistage.hpp:官方示例代码
- sgemm_sm80.cu:官方示例代码
A.3. 工具
Enjoy Reading This Article?
Here are some more articles you might like to read next: