CUTLASS-Cute 初步(3):TiledCopy 以及 TiledMMA
1. Cute TiledCopy
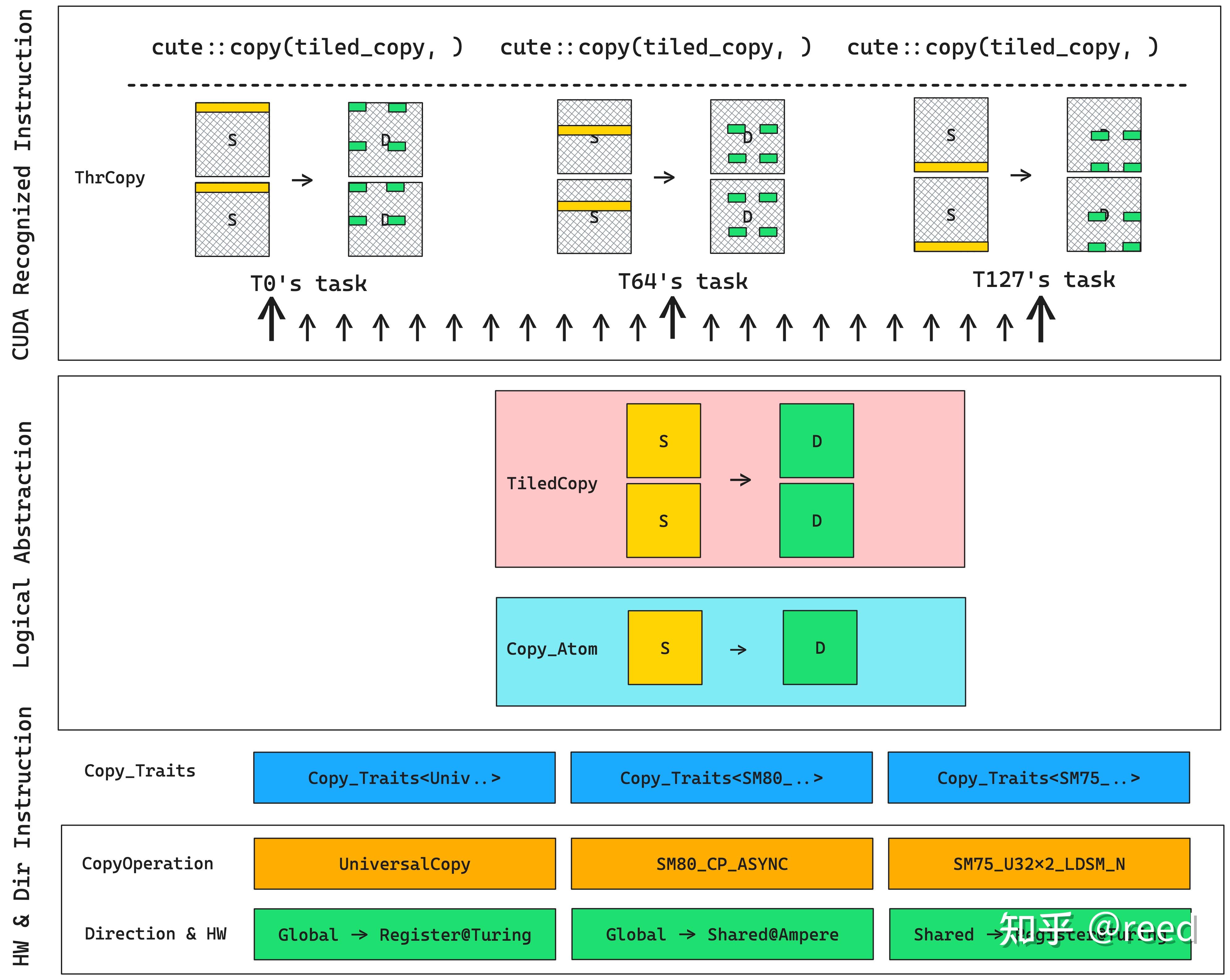
- tiled_copy.cu:官方示例
层次化的copy抽象,分为几个可组合的层次:
- CopyOperation:NVidia在不同的硬件架构、不同的存储层次之间数据搬运提供了不同的指令,如
ldmatrix和LDS等,还有针对Ampere架构的cp.async等。 - Copy_Traits:主要提供拷贝的
metadata信息:源Thread-Value Layout、目标Thread-Value Layout等。 - Copy_Atom:封装一个完整的最小数据搬运单元,包含
CopyOperation和Copy_Traits。 - TiledCopy:根据线程布局,重复使用
Copy_Atom完成分块数据搬运计算。 - make_tiled_copy{_A|B|C}:提供用户级别的API接口;
1.1. CopyOperation
CopyOperation封装了执行一次数据搬运指令,以及所需要的指令参数。其中指令参数(源参数、目的参数)描述了参数的类型以及个数,供API层级的copy函数使用。示例:
struct SM75_U16x8_LDSM_T
{
using SRegisters = uint128_t[1];
using DRegisters = uint32_t[4];
CUTE_HOST_DEVICE static void
copy(uint128_t const& smem_src,
uint32_t& dst0, uint32_t& dst1, uint32_t& dst2, uint32_t& dst3)
{
#if defined(CUTE_ARCH_LDSM_SM75_ACTIVATED)
uint32_t smem_int_ptr = cast_smem_ptr_to_uint(&smem_src);
asm volatile ("ldmatrix.sync.aligned.x4.trans.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];\n"
: "=r"(dst0), "=r"(dst1), "=r"(dst2), "=r"(dst3)
: "r"(smem_int_ptr));
#else
CUTE_INVALID_CONTROL_PATH("Trying to use ldmatrix without CUTE_ARCH_LDSM_SM75_ACTIVATED.");
#endif
}
};
1.2. Copy_Traits
执行数据拷贝操作,有如下需求:向量化指令,合并访存。
另外一般是以一个warp为单位,即需要考虑SRC/DST是如何分配给一个warp中的线程的。典型的如ldmatrix指令:一个phase要求一个warp中一组8个线程(如T0~T7),分别提供源SMEM地址uint128_t,以及32个线程的目的REG(uint32_t)。
Copy_Traits提供了源Thread-Value Layout、目的Thread-Value Layout等信息,即描述了线程如何访问数据的布局。示例:
template <>
struct Copy_Traits<SM75_U16x8_LDSM_T>
{
// Logical thread id to thread idx (warp)
using ThrID = Layout<_32>;
// Map from (src-thr,src-val) to bit
using SrcLayout = Layout<Shape < _32,_128>,
Stride<_128, _1>>;
// Map from (dst-thr,dst-val) to bit
using DstLayout = Layout<Shape <Shape < _4, _8>,Shape <_16, _2, _4>>,
Stride<Stride<_256,_16>,Stride< _1,_128,_1024>>>;
// Reference map from (thr,val) to bit
using RefLayout = DstLayout;
};
1.3. TiledCopy
通过TiledCopy,将Copy_Atom扩展到更多线程。需要提供两个参数:Thread-Value Layout,以及Tiler_MN,其中**Tiler_MN表示最终处理的M、N维度的tile大小,TV_Layout则包含了需要的线程数量,以及线程如何访问数据的布局。TiledCopy实现如下:
template <class Copy_Atom,
class LayoutCopy_TV, // (tid,vid) -> coord [Need not be 2D...]
class ShapeTiler_MN> // coord space
struct TiledCopy : Copy_Atom
{
// Layout information from the CopyAtom
using AtomThrID = typename Copy_Atom::ThrID; // thrid -> thr_idx
using AtomLayoutSrc = typename Copy_Atom::ValLayoutSrc; // (thr,val) -> offset
using AtomLayoutDst = typename Copy_Atom::ValLayoutDst; // (thr,val) -> offset
using AtomLayoutRef = typename Copy_Atom::ValLayoutRef; // (thr,val) -> offset
using AtomNumThr = decltype(size<0>(AtomLayoutRef{}));
using AtomNumVal = decltype(size<1>(AtomLayoutRef{}));
// Layout information for the TiledCopy
using Tiler_MN = ShapeTiler_MN;
using TiledLayout_TV = LayoutCopy_TV;
using TiledNumThr = decltype(size<0>(TiledLayout_TV{}));
using TiledNumVal = decltype(size<1>(TiledLayout_TV{}));
CUTE_STATIC_ASSERT_V(TiledNumThr{} % AtomNumThr{} == Int<0>{}, "TiledCopy uses too few thrs for selected CopyAtom");
CUTE_STATIC_ASSERT_V(TiledNumVal{} % AtomNumVal{} == Int<0>{}, "TiledCopy uses too few vals for selected CopyAtom");
// ....
};
从代码中,可以看到,TiledCopy中Thread数量比如为CopyAtom中线程数量的整数倍,Value数量也是CopyAtom中Value数量的整数倍。
1.4. ThrCopy
前面几个小节所描述的CopyOperation、Copy_Traits、Copy_Atom、TiledCopy等都是在编译期定义的抽象,描述了数据搬运的指令、线程访问数据的布局,以及如何将一个基本的搬运单元扩展到更多线程上。ThrCopy则是运行时根据线程 id 获取每个线程实际执行的数据搬运任务。
通过调用TiledCopy::get_slice接口,生成一个ThrCopy对象。通过ThrCopy的接口partition_S/D,获取线程拷贝的SRC/DST数据的Layout,比如(CPY, CPY_M, CPY_K)。
另外,待切分的Tensor可能其Shape不满足cute::copy的要求,使用ThrCopy::retile_S/D接口,重新切分成满足要求的Shape,retile前后Layout,其size(layout)与cosize(layout)保持一致,即指向同一块GMEM/SMEM且大小不变。
比如从TiledMMA创建的TiledCopy,其DST的Layout与SRC数据的Layout不匹配,需要使用retile_D接口重新切分成与SRC Tensor一致的Shape。
ThrCopy的定义如下:
template <class TiledCopy, class ThrIdx>
struct ThrCopy {
auto partition_S(Tensor&& stensor);
auto partition_D(Tensor&& dtensor);
auto retile_S(Tensor&& stensor);
auto retile_D(Tensor&& stensor);
};
1.5. make_tiled_copy{_A|B|C}
使用make_tiled_copy可以直接使用Thread-Value Layout创建一个TiledCopy对象,其中Tiler_MN可以从TV-Layout推导。
如果从一个TiledMMA创建TiledCopy,由于TiledMMA表示的是(M, N, K)三个维度(见下面章节TiledMMA的介绍),所以针对A/B/C,分别使用对应的make_tiled_copy_A/B/C接口创建TiledCopy对象。
使用示例:
using T = cute::half_t;
using VectorType = cute::uint128_t;
using CopyOp = cute::SM80_CP_ASYNC_CACHEALWAYS<VectorType>;
constexpr auto thread_shape_A = cute::make_shape(cute::Int<16>{}, cute::Int<8>{}); // (16M, 8K)
constexpr auto thread_stride_A = cute::make_stride(cute::Int<1>{}, cute::size<0>(thread_shape_A)); // (1, 16),M-major
constexpr auto thread_layout_A = cute::make_layout(thread_shape_A, thread_stride_A);
constexpr auto NUM_ELEMENTS_A = sizeof(VectorType) / sizeof(T);
constexpr auto vector_shape_A = cute::make_shape(cute::Int<NUM_ELEMENTS_A>{}, cute::Int<1>{}); // (8M, 1K)
constexpr auto vector_stride_A = cute::make_stride(cute::Int<1>{}, cute::size<0>(vector_shape_A));
constexpr auto vector_layout_A = cute::make_layout(vector_shape_A, vector_stride_A);
constexpr auto gmem_tiled_copy_A = cute::make_tiled_copy(cute::Copy_Atom<CopyOp, T>{}, thread_layout_A, vector_layout_A);
// constexpr auto tiler_mn = decltype(gmem_tiled_copy_A)::Tiler_MN{};
cute::print(gmem_tiled_copy_A);
std::cout << "-----------------------------" << std::endl;
cute::print_latex(gmem_tiled_copy_A);
打印信息如下:
TiledCopy
Tiler_MN: (_128,_8)
TiledLayout_TV: (_128,_8):(_8,_1)
Copy_Atom
ThrID: _1:_0
ValLayoutSrc: (_1,_8):(_0,_1)
ValLayoutDst: (_1,_8):(_0,_1)
ValLayoutRef: (_1,_8):(_0,_1)
ValueType: 16b
含义如下:
-
Tiler_MN: (_128,_8):表示分块的M维度大小为128,K维度大小为8。 -
TiledLayout_TV: (_128,_8):(_8,_1):表示线程访问数据的布局,其中(_128,_8)表示线程数量为128,且每个线程处理8个元素,Stride信息表明了每个线程处理的数据在内存中是连续的。 -
Tiler_MN和TiledLayout_TV,其size表示整个tile的大小,即M维度和K维度的总元素数量。
1.6. cute::copy – 执行数据搬运指令
copy 函数是拷贝的实际执行函数,完成线程指令的执行:
void copy(TiledCopy const& copy, Tensor const& src, Tensor& dst);
void copy_if(TiledCopy const& copy, PrdTensor const& pred, Tensor const& src, Tensor& dst);
2. MMAAtom 以及 TiledMMA
分块 MMA 抽象,将 MMA_Atom 分为几个可组合的层次:
- MMAOperation:是对 D=A*B + C 的 PTX 指令封装,以使用不同的数据类型以及 PTX 指令,包括使用 CUDA Core / Tensor Core。如 UniversalFMA<>、SM80_16x8x8_F32F16F16F32_TN。
- MMA_Traits:和 Copy_Traits 类似,提供了 MMAOperation 类型没有提供,但是其使用者 MMA_Atom 却需要的起到桥梁作用的信息。如数据类型信息,TV layout 信息。
- MMA_Atom:将 MMAOperation 和 MMA_Traits 结合,并提供 fragment 划分接口。
- TiledMMA:根据 LayoutTile_TV 切分的线程布局,重复使用 MMA_Atom 完成分块矩阵乘加计算。
- ThrMMA:完成实际的生成线程对应的 tensor。
2.1. MMAOperation
以SM80_16x8x8_F32F16F16F32_TN为例,封装了 SM80 架构下,16x8x8 大小的矩阵乘加指令 D=A * B + C,数据类型为 A:F16、B:F16、C:F32、D:F32。A 矩阵 row-major,B 矩阵 column-major。
- BLAS 中约定 normal 矩阵为列优先。T(transpose) 表示使用转置矩阵,即 row-major 存储。
- 下图原图见 Thakkar_BLISRetreat2023.pdf 第 30 页。
SM80_16x8x8_F32F16F16F32_TN 对应的 inverse TV-Layout 如下:
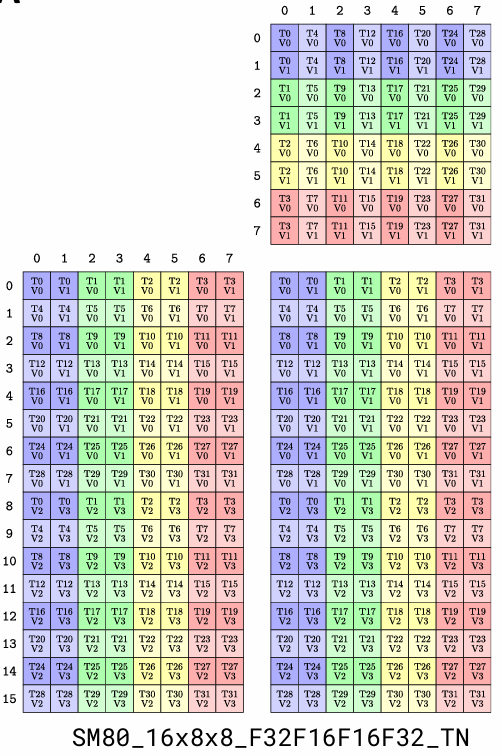
inverse TV-Layout 表示 element coordinate -> thread index的映射关系。
SM80_16x8x8_F32F16F16F32_TN 对应的 MMA_Atom 信息如下:
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_16,_8,_8)
LayoutA_TV: ((_4,_8),(_2,_2)):((_32,_1),(_16,_8))
LayoutB_TV: ((_4,_8),_2):((_16,_1),_8)
LayoutC_TV: ((_4,_8),(_2,_2)):((_32,_1),(_16,_8))
对应的代码如下:
print(MMA_Atom<SM80_16x8x8_F32F16F16F32_TN>{});
// using MMA = MMA_Traits<SM80_16x8x8_F32F16F16F32_TN>;
// print("ALayout: "), print(typename MMA::ALayout{}), print("\n");
// print("BLayout: "), print(typename MMA::BLayout{}), print("\n");
// print("CLayout: "), print(typename MMA::CLayout{}), print("\n");
MMA_Atom<SM80_16x8x8_F32F16F16F32_TN> mma;
print_latex(mma);
/* 或者如下写法
TiledMMA tiled_mma = make_tiled_mma(SM80_8x8x4_F64F64F64F64_TN{});
print_latex(tiled_mma);
*/
📌 SM80_16x8x8_F32F16F16F32_TN 使用一个 warp(32 个线程)处理 MNK 规模为 16 * 8 * 8 的一个 sub-tile。一个线程处理 A 中的 2 * 2 个数据,即LayoutATV 中的第二个 mode (_2, _2),则线程数位 $ThrNum{A} = 16 \times 8 \div 4 = 32$。同理可以知道,每个线程处理 B、C 中多少个数据,以及需要的线程数。
CUDA PTX 文档也给出了指令 m16n8k8 的布局信息:9.7.14.5.7. Matrix Fragments for mma.m16n8k8。
2.2. MMA_Traits
MMA_Traits 提供数据类型信息,以及 TV layout 信息,比如需要根据 MMAOperation 中定义的指令,补充 A/B/C 的 layout 信息。需要提供的信息如下:
using ElementDVal = // Logical A-value type
using ElementAVal = // Logical B-value type
using ElementBVal = // Logical C-value type
using ElementCVal = // Logical D-value type
using ElementAFrg = // A-type consumed by MMA (if ommitted, same as ElementAVal)
using ElementBFrg = // B_type consumed by MMA (if ommitted, same as ElementBVal)
using ElementCFrg = // C_type consumed by MMA (if ommitted, same as ElementCVal)
using Shape_MNK = // Logical MxNxK shape of the MMA
using ThrID = // Logical thread id (tid) -> tidx
using ALayout = // (Logical thread id (tid), Logical value id (vid)) -> Flat MK-coord
using BLayout = // (Logical thread id (tid), Logical value id (vid)) -> Flat NK-coord
using CLayout = // (Logical thread id (tid), Logical value id (vid)) -> Flat MN-coord
2.3. MMA_Atom
MMA_Atom 封装了 MMAOperation 和 MMA_Traits。
创建寄存器 fragment
提供了创建寄存器 fragment 的接口 make_fragment_A/B/C:
template <class CTensor>
static constexpr auto make_fragment_C(CTensor&& ctensor);
template <class ATensor>
static constexpr auto make_fragment_A(ATensor&& atensor);
template <class BTensor>
static constexpr auto make_fragment_B(BTensor&& btensor);
调用 FMA 指令
提供 call 接口,调用 MMAOperation 指令:
template <class TD, class DLayout,
class TA, class ALayout,
class TB, class BLayout,
class TC, class CLayout>
constexpr void call(Tensor<TD, DLayout>& D,
Tensor<TA, ALayout> const& A,
Tensor<TB, BLayout> const& B,
Tensor<TC, CLayout> const& C) const;
- TODO: 调用之前进行一个 unpack 操作?
2.4. TiledMMA
TiledMMA的模版参数表达了TiledMMA对MMA_Atom上的扩展逻辑:AtomLayoutMNK表示M、N、K方向上分别扩展的倍数(同时处理的MNK问题的规模也会相应倍数的增加)。TiledMMA::get_slice、TiledMMA::get_thread_slice函数功过给定线程 id 则获取线程对应到ThrMMA对象。
template <class MMA_Atom,
class AtomLayoutMNK,
class PermutationMNK = Tile<Underscore,Underscore,Underscore>>
struct TiledMMA : MMA_Atom {
auto get_slice(ThrIdx const& thr_idx) const {
auto thr_vmnk = thr_layout_vmnk_.get_flat_coord(thr_idx);
return ThrMMA<TiledMMA, decltype(thr_vmnk)>{*this, thr_vmnk};
}
auto get_thread_slice(ThrIdx const& thr_idx) const {
return get_slice(thr_idx);
}
auto thrfrg_C(CTensor&& ctensor) const {
....
}
};
三个模板参数的含义:
| 参数名 | 类型 | 说明 |
|---|---|---|
| MMA_Atom | 底层指令 | 定义单条 MMA 指令涉及的线程和值的布局 |
| AtomLayoutMNK | Layout<Shape<_2,_2,_1>> | 在 M/N/K 方向上重复多少个 atom(分配更多线程) |
| PermutationMNK | Tile<_8, _16, _8>{} | 每个线程在 M/N/K 方向上处理更多的值(不增加线程) |
AtomLayoutMNK决定如何将MMA_Atom复制到更多的线程上执行,且将MMA_Atom处理的线程扩展为size(AtomLayoutMNK)倍数。注意:AtomLayoutMNK是以倍数的形式给出的,且AtomLayoutMNK定义的是mma_layout。
在cutlass / CuTe 3.4之前版本还有ValLayoutMNK参数,从3.4版本开始去掉该模板参数。PermutationMNK可以替代 ValLayoutMNK的功能。PermutationMNK 定义的是mma_tile,即定义这个TiledMMA最终处理的MNK规模,不影响线程的扩展(cAtomLayoutMNK已经定义了线程扩展的布局)。
PermutationMNK 的展开讲述见下面章节。
2.4.1. 四层 Layout 以及获取线程 fragment
根据给定的 MMA_Atom、以及 AtomLayoutMNK 参数,生成一个四层 Layout 结构:
using ThrLayoutVMNK = decltype(tiled_product(AtomThrID{}, AtomLayoutMNK{}));
ThrLayoutVMNK thr_layout_vmnk_;
- Mode 0 (V): Threads within a single atom
- Mode 1 (M): Atom tiles in M dimension
- Mode 2 (N): Atom tiles in N dimension
- Mode 3 (K): Atom tiles in K dimension
以 thrfrg_A 为例:
// Tile a tensor or a layout from shape
// (M,K,...)
// to shape
// ((ThrV,(ThrM,ThrK)),(FrgV,(RestM,RestK,...)))
// where
// ThrV: The threads local to an MMA. layout<0>(ThrLayoutVMNK): ThrV -> thread_idx
// ThrM: The threads tiled in M. layout<1>(ThrLayoutVMNK): ThrM -> thread_idx
// ThrK: The threads tiled in K. layout<3>(ThrLayoutVMNK): ThrK -> thread_idx
// FrgV: The values local to an MMA.
// RestM: The values tiled in M.
// RestK: The values tiled in K.
template <class ATensor>
constexpr auto thrfrg_A(ATensor&& atensor) const;
即得到的线程切分后的 subtile 布局为 ((ThrV,(ThrM,ThrK)),(FrgV,(RestM,RestK,…)))。
2.4.2. TiledMMA 流程示意
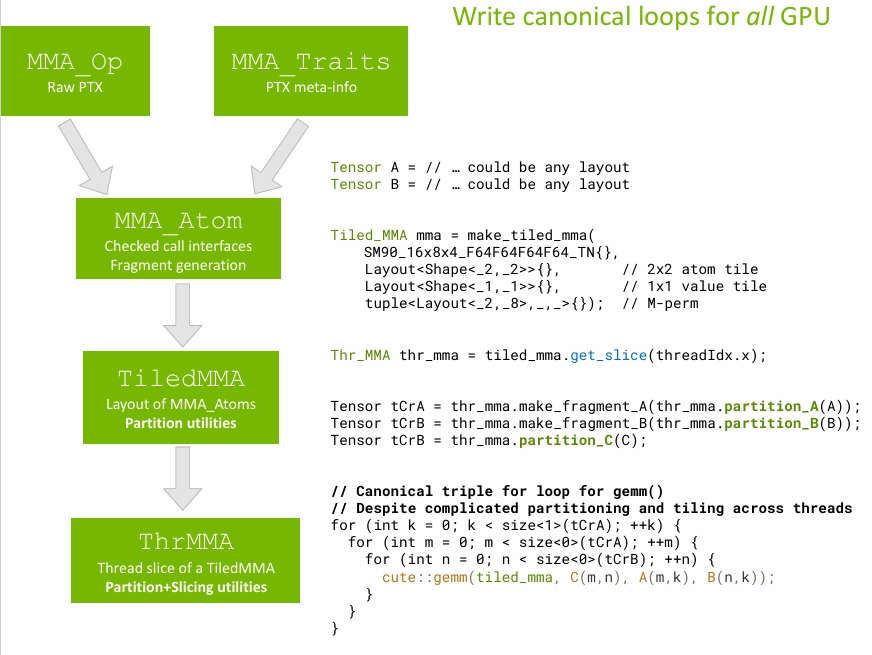
2.5. ThrMMA
TiledMMA 根据具体的线程 id 分解得到 ThrMMA 结构,提供 partition 函数接口,以及 partition_fragment 函数接口。
如 Tensor C 为 BLK_M x BLK_N,则 partition_C 可以得到线程级别的任务,维度为 (MMA, MMA_M, MMA_N), MMA 表达了 TileMMA 一次能计算的单元,MMA_M, MMA_N 表达了 M 方向和 N 方向需要分块数量。
partition_fragment 类函数是按照 partition 类函数返回的 Tensor 形状生成的对应的寄存器表示。
template <class TiledMMA, class ThrVMNK>
struct ThrMMA : TiledMMA {
Tensor partition_C(Tensor C);
Tensor partition_A(Tensor A);
Tensor partition_B(Tensor B);
Tensor partition_fragment_C(Tensor C);
Tensor partition_fragment_A(Tensor A);
Tensor partition_fragment_B(Tensor B);
}
2.6. Permutation:置换
Permutation是一个Tiler,由三个独立的分量组成,分别作用于M、N、K维度。Permutation可以实现两种变换:
- 创建
Tiler,即定义最终TiledMMA处理的MNK规模。 - 对
M、N、K维度的逻辑坐标进行重新映射。
以SM80_8x8x4_F64F64F64F64_TN为例,这个MMA_Atom的Inverse TV-Layout如下:
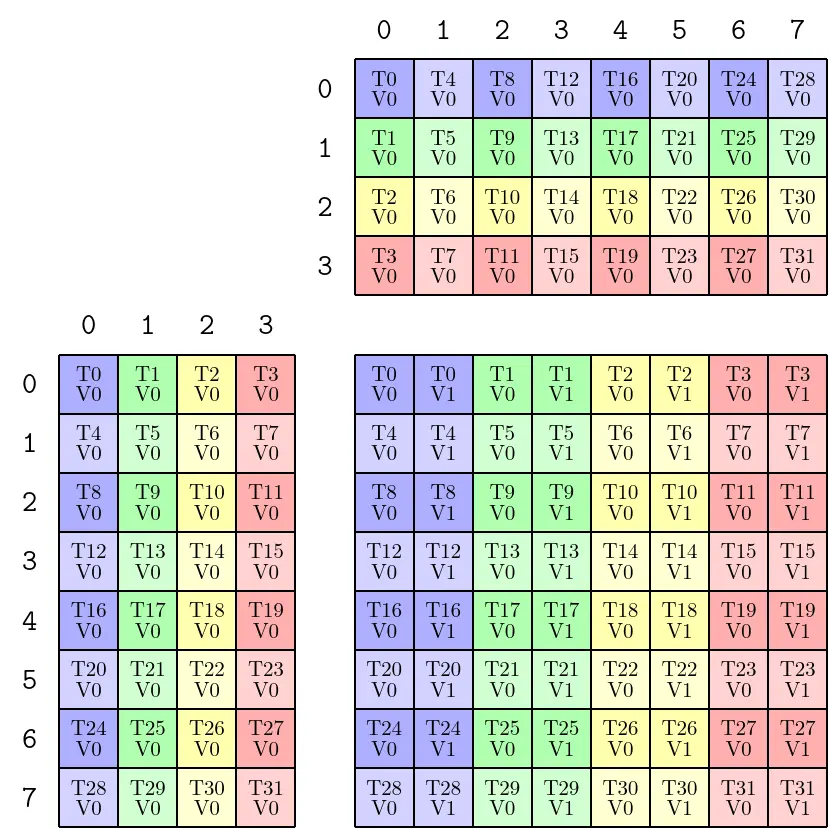
TiledMMA
ThrLayoutVMNK: (_32,_1,_1,_1):(_1,_0,_0,_0)
PermutationMNK: (_,_,_)
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_8,_8,_4)
LayoutA_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutB_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutC_TV: ((_4,_8),_2):((_16,_1),_8)
代码如下:
using namespace cute;
TiledMMA tiled_mma = make_tiled_mma(SM80_8x8x4_F64F64F64F64_TN{});
std::cout << "=== SM80_8x8x4_F64F64F64F64_TN ===\n";
print(tiled_mma), print("\n");
std::cout << "=== SM80_8x8x4_F64F64F64F64_TN latex format ===\n";
print_latex(tiled_mma);
std::cout << "\n";
2.6.1. PermutationMNK 的作用1:Tiler
using namespace cute;
TiledMMA tiled_mma = make_tiled_mma(SM80_8x8x4_F64F64F64F64_TN{},
Layout<Shape<_1, _1, _1>>{}, // AtomLayout
Tile<_8, _16, _8>{}); // Tiler
std::cout << "=== SM80_8x8x4_F64F64F64F64_TN ===\n";
print(tiled_mma), print("\n");
std::cout << "=== SM80_8x8x4_F64F64F64F64_TN latex format ===\n";
print_latex(tiled_mma);
std::cout << "\n";
TiledMMA
ThrLayoutVMNK: (_32,_1,_1,_1):(_1,_0,_0,_0)
PermutationMNK: (_8,_16,_8)
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_8,_8,_4)
LayoutA_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutB_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutC_TV: ((_4,_8),_2):((_16,_1),_8)
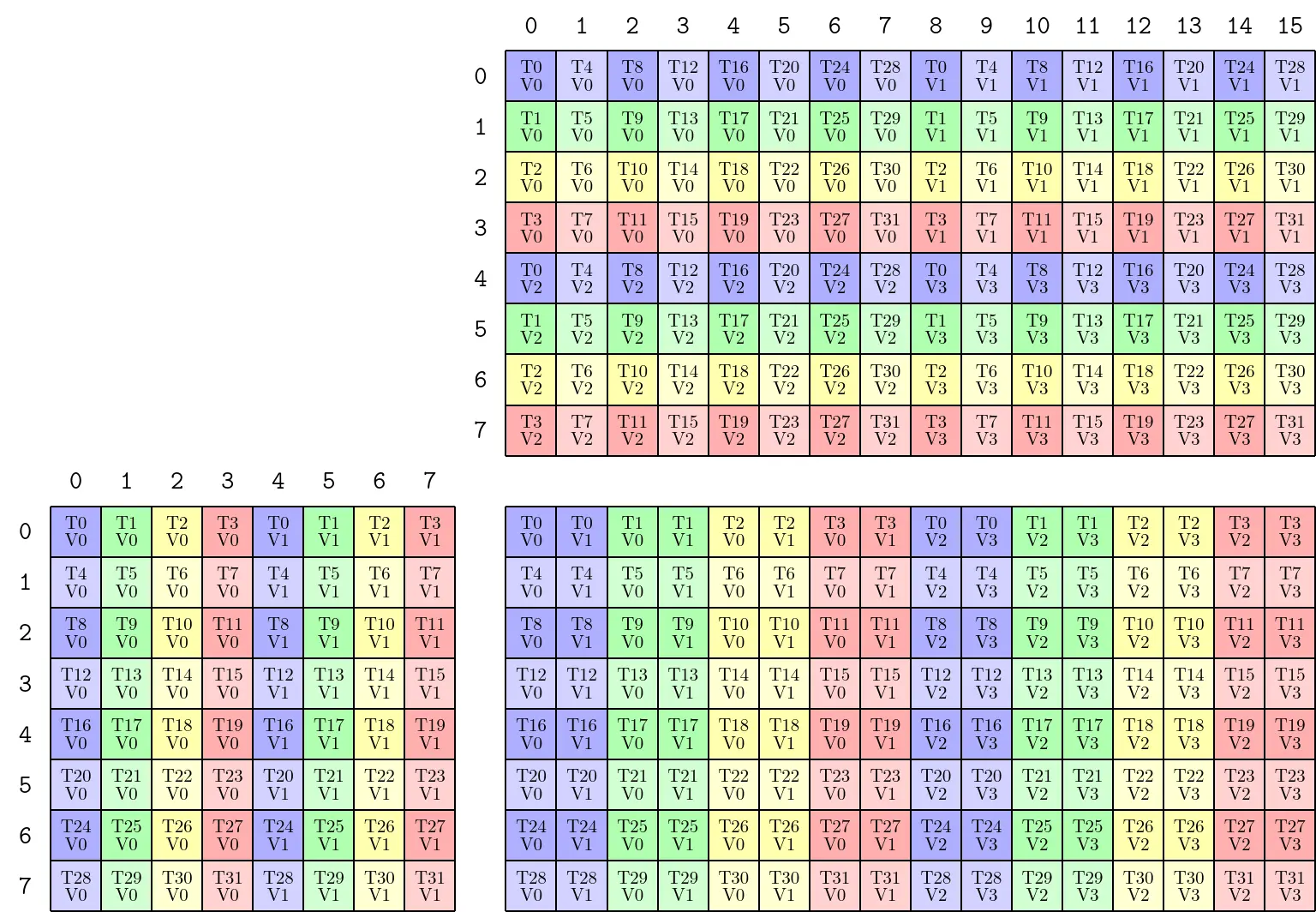
2.6.2. PermutationMNK 的作用2:重新映射逻辑坐标
通过对M、N、K这三个维度进行置换操作,即逻辑坐标重新映射,实现线程访问数据的合并,即合并访存。
using namespace cute;
TiledMMA tiled_mma_perm = make_tiled_mma(SM80_8x8x4_F64F64F64F64_TN{},
Layout<Shape<_1, _1, _1>>{}, // AtomLayout
Tile<_8, // Permutation on M, equivalent to 8:1, identity
Layout<Shape<_2, _4, _2>, Stride<_1, _4, _2>>, // Permutation on N, size 16
_8>{});
std::cout << "=== SM80_8x8x4_F64F64F64F64_TN ===\n";
print(tiled_mma_perm), print("\n");
std::cout << "=== SM80_8x8x4_F64F64F64F64_TN latex format ===\n";
print_latex(tiled_mma_perm);
std::cout << "\n";
TiledMMA
ThrLayoutVMNK: (_32,_1,_1,_1):(_1,_0,_0,_0)
PermutationMNK: (_8,(_2,_4,_2):(_1,_4,_2),_8)
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_8,_8,_4)
LayoutA_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutB_TV: ((_4,_8),_1):((_8,_1),_0)
LayoutC_TV: ((_4,_8),_2):((_16,_1),_8)
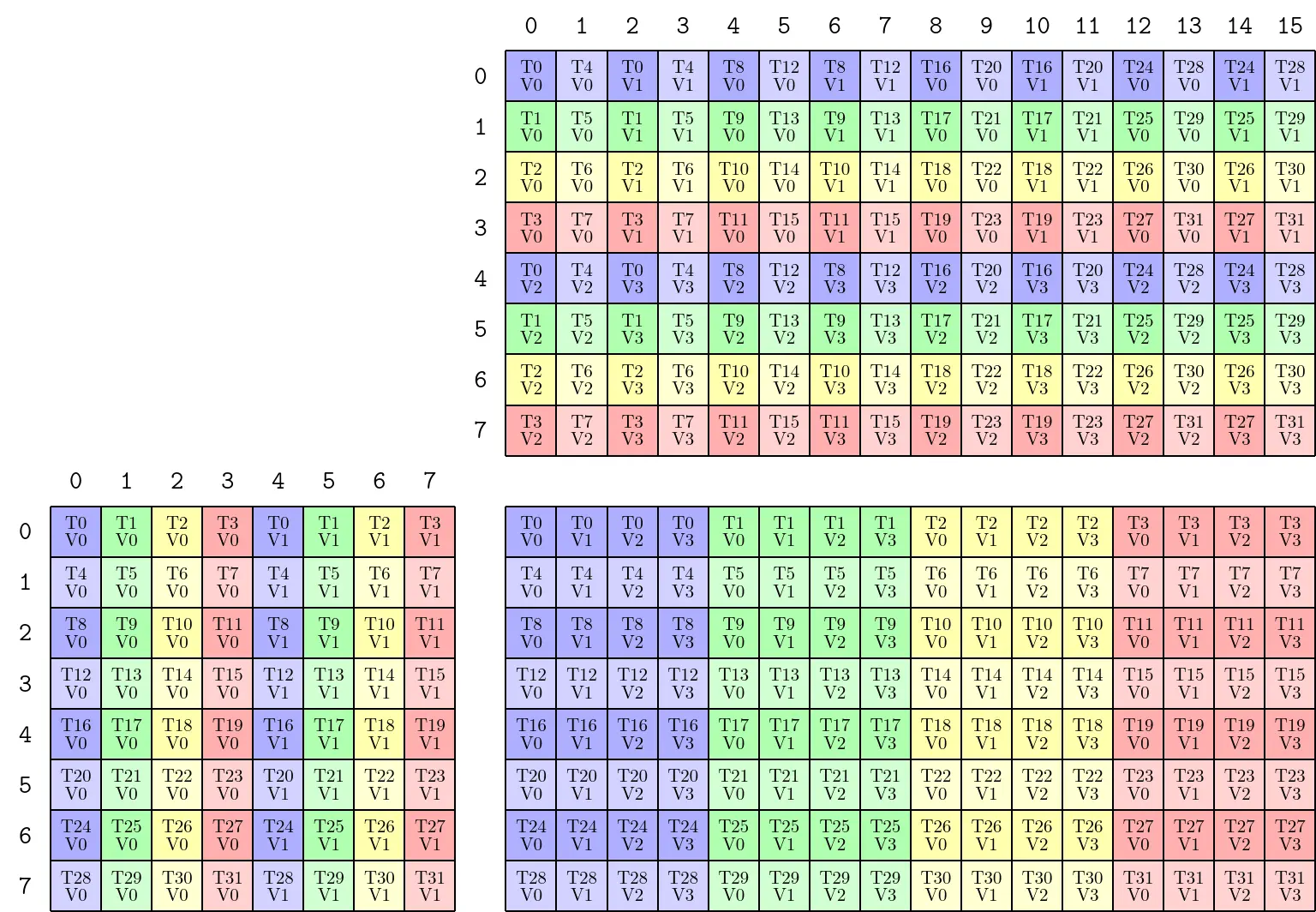
2.6.3. 参考资料
- 0t_mma_atom:官方文档,讲了
Permute操作,包括scatter permutation - [QST] What is PermutationMNK in TiledMMA in CUTLASS 3.4 changes?
- 02_layout_algebra.md – Logical Divide 2-D Example
- 0t_mma_atom – TiledMMAs
2.7. UniversalFMA
可以参考 Thakkar_BLISRetreat2023.pdf 第 26 页。
UniversalFMA 是一个标量 FMA 操作的 MMAOperation 实现,定义如下:
template <class D, class A = D, class B = A, class C = D>
struct UniversalFMA {
using DRegisters = D[1];
using ARegisters = A[1];
using BRegisters = B[1];
using CRegisters = C[1];
CUTE_HOST_DEVICE static constexpr void
fma(D& d, A const& a, B const& b, C const& c) {
// Forward to an ADL/cute free function for these types
using cute::fma;
fma(d, a, b, c); // 这里的实现就是d = a * b + c;
}
};
template <class D, class A, class B, class C>
struct MMA_Traits<UniversalFMA<D,A,B,C>> {
using ValTypeD = D;
using ValTypeA = A;
using ValTypeB = B;
using ValTypeC = C;
// Logical shape of the MMA
using Shape_MNK = Shape<_1,_1,_1>;
// Logical thread id (tid) -> tidx
using ThrID = Layout<_1>; // 只有一个thread参与
// (Logical thread id (tid), Logical value id (vid)) -> coord
// (tid,vid) -> (m,k)
using ALayout = Layout<Shape<_1,_1>>;
// (tid,vid) -> (n,k)
using BLayout = Layout<Shape<_1,_1>>;
// (tid,vid) -> (m,n)
using CLayout = Layout<Shape<_1,_1>>;
};
参考官方示例函数gemm_nt:https://github.com/NVIDIA/cutlass/blob/main/examples/cute/tutorial/sgemm_sm80.cu#L478,从中提取部分代码如下:
using TA = float;
using TB = float;
using TC = float;
TiledMMA mmaC = make_tiled_mma(UniversalFMA<TC, TA, TB>{}, Layout<Shape<_16, _16, _1>>{}); // 16x16x1 TiledMMA
std::cout << "\nTiledMMA Layouts (UniversalFMA 16 16 1):" << std::endl;
print(mmaC), print("\n");
/*print("ALayout: "), print(typename decltype(mmaC)::ALayout{}), print("\n");
print("BLayout: "), print(typename decltype(mmaC)::BLayout{}), print("\n");
print("CLayout: "), print(typename decltype(mmaC)::CLayout{}), print("\n");*/
std::cout << "\nMMA Atom Layout:" << std::endl;
print_latex(mmaC);
Inverse TV-Layout 如下:

MMA_Atom 信息如下:
TiledMMA
ThrLayoutVMNK: (_1,_16,_16,_1):(_0,_1,_16,_0)
PermutationMNK: (_,_,_)
MMA_Atom
ThrID: _1:_0
Shape_MNK: (_1,_1,_1)
LayoutA_TV: (_1,_1):(_0,_0)
LayoutB_TV: (_1,_1):(_0,_0)
LayoutC_TV: (_1,_1):(_0,_0)
A. 资料
- A Generalized Micro-kernel Abstraction for GPU Linear Algebra:BLIS Retreat 2023 上的论文,介绍了 CUTLASS-Cute 中 TiledCopy 和 TiledMMA 的设计细节。待阅读
- Introduction to CUDA Performance Optimization:CUDA Programming and Optimization 课程的 PPT,介绍了 CUDA 优化相关的知识,其中第 28-30 页介绍了 CUTLASS-Cute 中 TiledMMA 的设计细节。待阅读
A.1. TiledCopy 资料
- CuTe Tiled Copy:Mao Lei 博客
- cute 之 Copy抽象:reed 知乎文章
- CUTLASS 笔记 (4):Tiled Copy:知乎杨远航文章
- cute/tutorial/tiled_copy.cu:官方示例代码
A.2. MMA Atom 资料
- 0t_mma_atom.md:官方文档,MMA Atom 文档
- cute 之 MMA抽象:reed 知乎文章
- CuTe Tiled MMA:Mao Lei 博客,如何配置 TiledMMA
- Thakkar_BLISRetreat2023.pdf
- MMA Atoms and TiledMMA
A.3. 参考代码
- sm80_mma_multistage.hpp:官方示例代码
- sgemm_sm80.cu:官方示例代码
A.4. Latex转换工具
A.5. Layout / TV-Layout 可视化
- cutlass-viz
- cute_render
- cute-viz
- example_cute_tv_layout:使用cute-viz可视化的测试代码
Enjoy Reading This Article?
Here are some more articles you might like to read next: