CUTLASS-Cute 初步(4):Swizzle
Swizzle作用于SMEM的layout。给定layout范围内,Swizzle通过列异或操作(icol = irow ^ icol),周期性的coord重排,映射到新的物理地址offset。Swizzle定义了三个参数:
- $MBase$:以 $2^M$ 个一维坐标连续的元素为单位,将其当做一个元素;
- $SShift$:从
Offset中提取的高位偏移,用于提取Offset的lead dimension; - $BBits$:参与
XOR的位数,用于提取一维index中的lead dimension、fast dimension中的部分bits。
引用reed解释及图示,其输入为一个一维坐标的layout,通过swizzle将其拆分为二维坐标表示形式:
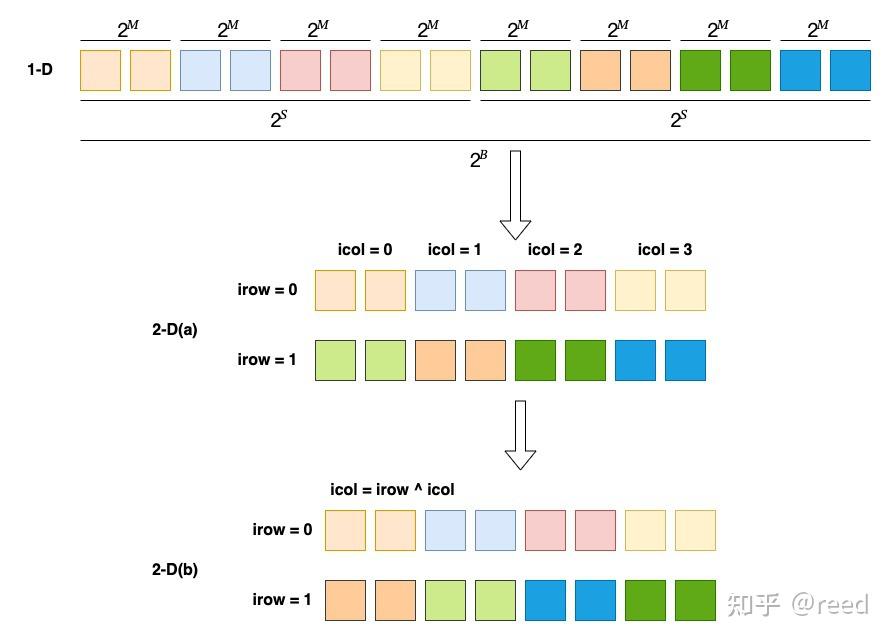
给定义一个输入Offset:<LeadBits:FastBits>:
- 提取关系为:
BBits+MBase->FastBits,SShift+MBase->LeadBits。 - 参与
XOR操作的位宽为:BBits,即LeadBits中的低BBits位,FastBits中的高BBits位。
BBits表示有$2^B$个交换模式,SShift表示交换模式的周期。通常$\mid{S}\mid \ge B$,如果$\mid{S}\mid \gt B$,则此交换模式重复$2^{\mid{S}\mid - B}$次,如果$\mid{S}\mid = B$,则只套用一次此交换模式。
一般在设置Swizzle参数时,按输入的layout一行(准确的说是fast dimension)为周期进行swizzle,$2^{S+M}$ = 输入layout的列长度(此处仅指逻辑上的,实际完整的计算公式还需要考虑到元素存储字节数,具体见下面章Swizzle 参数设计规则)。
比如 half 类型的layout (8, 32):(32, 1),定义swizzle<3, 3, 3>,即 8 个元素形成新的最小单位(M),8 个最小单位为一行(B),所以swizzle从$8 \times 8 = 64$个元素开始。见下面示例。B 为 8,则整个swizzle周期为 8 行。
- 设计
Swizzle参数时,要求S >= B,否则不能提取到LeadBits。 - 设计
Layout时,如果Layout的fast dimension长度小于 $2^{S+M}$,Swizzle不能完整的提取LeadBits,导致Swizzle失效或部分失效。 - 异或操作数学符号为 $\oplus$。
1. Cute Swizzle 示例
定义 layout (8, 32):(32, 1),定义swizzle<3, 2, 3>。定义的Swizzle含义如下:
- $2^{B+M}=2^{3+2}$ = 32:fast dimension 长度,32个elements。
- $2^{M}=2^2=4$:4个element组成一个最小单位。
- $2^{B}=2^3=8$:8个交换模式。
- $2^{S}=2^3=8$:交换模式周期为8。
代码如下:
from cutlass import cute
from cute_viz import render_layout_svg, render_swizzle_layout_svg
@cute.jit
def test_swizzle_layout():
layout_2d = cute.make_layout((8, 32), stride=(32, 1))
sw = cute.make_swizzle(3, 2, 3)
swizzled_layout = cute.make_composed_layout(sw, 0, layout_2d)
render_layout_svg(layout_2d, "out/original_layout.svg")
render_swizzle_layout_svg(swizzled_layout, "out/swizzled_layout.svg")
test_swizzle_layout()
结果如下:

2. Swizzle 逻辑及规律
class Swizzle {
public:
Swizzle(int num_bits, int num_base, int num_shft) : m_num_bits(num_bits), m_num_base(num_base), m_num_shft(num_shft) {
CHECK2(m_num_bits >= 0, "BBits must be positive.");
CHECK2(m_num_base >= 0, "MBase must be positive.");
CHECK2(std::abs(m_num_shft) >= m_num_bits, "abs(SShift) must be more than BBits.");
}
template <class Offset>
auto apply(Offset offset) const noexcept {
return offset ^ shiftr(offset & m_yyy_msk); // ZZZ ^= YYY
}
template <class Offset>
auto operator()(Offset offset) const noexcept {
return apply(offset);
}
private:
template <class Offset>
auto shiftr(Offset offset) const noexcept {
return m_msk_sft >= 0 ? offset >> m_msk_sft : offset << -m_msk_sft;
}
int m_num_bits;
int m_num_base;
int m_num_shft;
int m_bit_msk = (1 << m_num_bits) - 1;
int m_yyy_msk = m_bit_msk << (m_num_base + std::max(0, m_num_shft));
int m_zzz_msk = m_bit_msk << (m_num_base - std::min(0, m_num_shft));
int m_msk_sft = m_num_shft;
};
-
m_zzz_msk没有参与swizzle计算,在CuTe库中用作检查作用。
Swizzle根据参数BBits、SShift,生成offset的掩码:高位部分提取掩码yyy_msk、低位部分提取zzz_msk,即分别对应行提取掩码、列提取掩码。此时,可以将MBase看作是BBits的一部分。直观展示如下:
bits bits
-- --
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxZZxxx
<--------->---
shift base
针对每个offset,经过swizzle映射之后,异或更新低位掩码对应的值:
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxAAxxx
其中 AA = ZZ ^ YY。
2.1. Swizzle 参数影响规律分析
分别以行混淆周期,以及列混淆周期,这两个层次来分析。
以一个 layout (32, 16):(16, 1)为例,分析swizzle<B=4, M=0, S4> 参数变动对结果的影响规律。
经过offset & yyy_mk提取行号低四位(以及shiftr操作得到最终行号提取掩码),得到第 0 行、第 16 行(0x10)由于行号掩码提取过后的低 4 位为 0,导致swizzle无效。
2.1.1. B 参数对周期的影响
如果使用 swizzle<B=3, M=0, S=4>,导致高位掩码提取行号的低三位,行号为 0、8、16、24 时,得到的高位 YY 部分均为 0,swizzle 异或操作不生效。
如果设 S = 3,则layout的左半部分(列 0 ~ 8)呈现 0、8、16、24 的行混淆周期。右半部分暂没有理清规律。
2.1.2. S 参数以及列长度对周期的影响
如果使用 S = 5,行号提取范围扩大到 32,由于 layout 的行号、列号范围对应掩码为 4 位,导致的结果为行号有效的掩码位为 0bxxxx0 >> 1,即最低一位被丢弃,且有效的掩码位为 4 位(注意 shiftr 的实现是提取高位之后右移S位)。最终的规律为:第 0、1 行维持不变,行周期变为 32 行,即第32、33行维持不变。中间的行,则每两行异或计算结果一致,即如果应用于解决 bank conflicts,此时只能消除一半的 bank conflicts。
2.2. 测试代码
from cutlass import cute
from cute_viz import render_swizzle_layout_svg
@cute.jit
def test_swizzle_layout():
layout_2d = cute.make_layout((32, 16), stride=(16, 1))
sw = cute.make_swizzle(4, 0, 4)
swizzled_layout = cute.make_composed_layout(sw, 0, layout_2d)
# render_layout_svg(layout_2d, "out/original_layout.svg")
render_swizzle_layout_svg(swizzled_layout, "out/swizzled_layout.svg")
test_swizzle_layout()
2.3. Swizzle 与 Layout 的关系
Swizzle 的实现与 Layout 没有关系,但是从其实现看,最终形成的 index,fast dimension (即内存连续的维度)位于低位,得到的结果就是对 fast dimension 形成XOR操作,即改变其映射顺序。演示代码片段如下:
for (int i = 0; i < cute::size<0>(layout); i++) {
for (int j = 0; j < cute::size<1>(layout); j++) {
int idx = layout(i, j);
int swizzled_idx = swizzle(idx);
int bank_id = (swizzled_idx * element_size / 4) % 32;
}
}
创建一个列主序的 Layout (32, 32):(1, 32),XOR此时作用在行号上(即 fast dimension),但是从物理存储上看,其结果与行主序的 layout 是相同的。这个列主序 Layout 原始图示,以及 Swizzle 映射之后图示如下:


另外,Swizzle就是一个复合映射,演示代码如下:
constexpr auto smem_atom_layout_A = cute::make_layout(cute::make_shape(cute::Int<32>{}, cute::Int<8>{}));
constexpr auto smem_atom_layout_A_swizzled = cute::composition(swizzle_A, smem_atom_layout_A);
constexpr auto smem_shape_A = cute::make_shape(bM, bK, bP); // (bM, bK, bP)
constexpr auto smem_layout_A = cute::tile_to_shape(smem_atom_layout_A_swizzled, smem_shape_A);
3. Swizzle 参数设计规则
假定矩阵每个元素大小为 S-byte,向量化访问的宽度为N个元素,shared memory 的 fast dimension 为X个元素。即:
| 符号 | 含义 |
|---|---|
| S_elem | 每个元素的大小(bytes) |
| N | 向量化访问的元素个数 |
| X | Fast dimension 的元素个数 |
$\text{MBase} = log_{2}\text{N}$,即向量化访问的元素个数。
$\text{SShift} = log_{2}\text{X} - \text{MBase}$,即 X = $2^{\text{MBase} + \text{SShift}}$,这样使得针对每一行的 swizzle 操作,掩码偏移对齐到行号的位置。即,将提取行号的掩码分为两部分:低 MBase 位不参与 swizzle,高 SShift 位参与 swizzle。
$\text{BBits} = log_{2}\text{(32 * 4 / S)} - \text{MBase}$。其原因为要确保 BBits 对应覆盖一次 shared memory 的访问字宽:128 字节,即 $\text{S} \times 2^\text{MBase + BBits}$ = 32 * 4 = 128B。
即要求 32 个连续的 word 地址,经过
swizzle之后,分别落入shared memory的32个bank中。
3.1. Swizzle 参数设计示例1
假定 half 类型(S_elem = 2 bytes)行主序矩阵,矩阵大小为 8 * 64。采用 128-bit 向量化访问指令,即每次访问 8 个 half 元素(4 个 word)。
MBase = log2(8) = 3。
SShift = log2(64) - MBase = 6 - 3 = 3。即其约束在于 shared memory 的 fast dimension 为 64 个元素,即掩码偏移量为 fast dimension 长度。
BBits = log2(32 * 2) - MBase = 6 - 3 = 3。即要求 32 个连续的 word 地址,经过 swizzle 之后,分别落入 shared memory 的32个 bank 中。
最终,得到 swizzle<3, 3, 3>。
3.2. 一个错误的设计示例,以及修复
输入 layout,其 Offset 组成为:<LeadBits>:<FastBits>。Swizzle 对输入 layout 的约束为:
- 输入 layout 的 fast dimension 长度,即连续内存访问的维度长度,应该等于 $2^{MBase + SShift}$。
- 如果输入 layout fast dimension 长度小于 $2^{MBase + SShift}$,则导致 Swizzle 只取到
LeadBits的高位部分,低位部分取到FastBits里面去了。 - 输入 layout 的 lead dimension 长度小于 $2^{MBase + SShift}$,没有影响,即一个
交换模式周期没有被完整应用。
错误示例如下:
constexpr auto bM = cute::Int<128>{};
constexpr auto bK = cute::Int<32>{};
constexpr auto MBase_A = constexpr_log2(sizeof(cute::uint128_t) / sizeof(T)); // log2(8) = 3
constexpr auto BBits_A = constexpr_log2(32 * 4 / sizeof(T)) - MBase_A; // log2(64) - 3 = 3
constexpr auto SShift_A = constexpr_log2(bM) - MBase_A; // log2(128) - 3 = 4
constexpr auto swizzle_A = cute::Swizzle<BBits_A, MBase_A, SShift_A>{};
constexpr auto smem_atom_layout_A = cute::make_layout(cute::make_shape(cute::Int<32>{}, cute::Int<8>{}));
constexpr auto smem_atom_layout_A_swizzled = cute::composition(swizzle_A, smem_atom_layout_A);
constexpr auto smem_layout_A = cute::tile_to_shape(smem_atom_layout_A_swizzled, cute::make_shape(bM, bK));
上述示例中,输入 layout 的 fast dimension=32 => 位宽为 5;LeadBits= 8 => 位宽为 3。得到 Offset 位格式为<LeadBits=3:FastBits=5>。与 Swizzle 对齐的位宽组成要求为<X:4+3>,导致 Swizzle 只从lead dimension的高位部分获取2-Bit,低位2-Bit是从Offset的fast dimension中获取的;另外,经过BBits位与之后,LeadBits只有1-Bit起作用。
其结果就是,Swizzle 之后的结果,shape 等于输入 layout 的 shape,但是没有达到预期的效果。测试代码:
@cute.jit
def test_swizzle_layout2(): # 该swizzle不起作用
"""该swizzle不起作用, 因为fast dimension长度不满足要求"""
layout_3d = cute.make_layout((32, 8)) # 列主序布局
sw = cute.make_swizzle(3, 3, 4) # 要求fast dimension 长度为 2^(4+3) = 128
swizzled_layout = cute.make_composed_layout(sw, 0, layout_3d)
render_layout_svg(layout_3d, "out/original_layout2.svg")
render_swizzle_layout_svg(swizzled_layout, "out/swizzled_layout2.svg")
test_swizzle_layout2()
修复代码如下:
// constexpr auto bM = cute::Int<128>{};
constexpr auto smem_atom_layout_A = cute::make_layout(cute::make_shape(bM, cute::Int<8>{}));
对应的测试代码:
@cute.jit
def test_swizzle_layout3():
"""修正: fast dimension长度满足要求, swizzle生效"""
"""MBase=3: 8个元素组成一组. """
layout_3d = cute.make_layout((128, 8)) # 列主序布局
sw = cute.make_swizzle(3, 3, 4) # 要求fast dimension 长度为 2^(4+3) = 128
swizzled_layout = cute.make_composed_layout(sw, 0, layout_3d)
render_layout_svg(layout_3d, "out/original_layout3.svg")
render_swizzle_layout_svg(swizzled_layout, "out/swizzled_layout3.svg")
test_swizzle_layout3()
Swizzle之后的Layout:

4. Thread Block Swizzle
由于 CUDA 调度实际上是以 block id 的顺序进行调度的,有时候,通过对 thread block 映射的tile进行重新排序,最大限度的利用L2 cache中个的数据,提升性能。
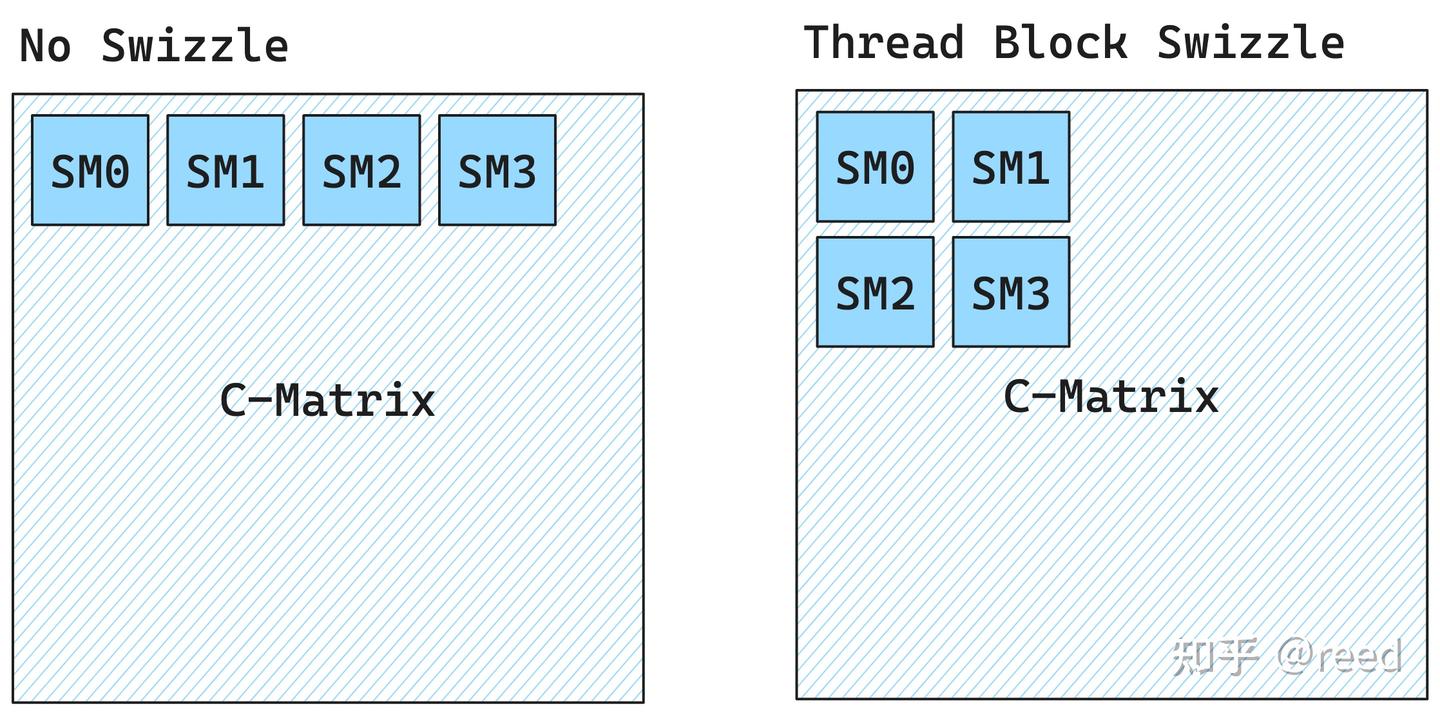
GPU 硬件调度器通常优先调度 x,然后 y,最后 z 维度(单个SM调度thread block?还是所有SM -> thread block的顺序?)。
Thread block swizzle,以及block调度顺序,见 github issue:[QST]how to understand “block swizzling”,以及博客Nvidia Tensor Core-CUDA HGEMM Advanced Optimization。
关于使用
thread block swizzle复用L2 cache,见 NVIDIA 博客Optimizing Compute Shaders for L2 Locality using Thread-Group ID Swizzling。
A. 参考资料
- cute 之 Swizzle:来自知乎 Reed 文章
- Tensor Core MMA Swizzle Layout:来自 Yang Yifan 博客。待学习
- CuTe Swizzle:来自 Lei Mao 博客,其中段落
Vectorized Memory Access讲述如何设计连续内存访问的 swizzle 参数。 - CUTLASS CuTe GEMM细节分析(四)——谈谈Swizzle模板参数中关于B和S的一些误区:知乎 Anonymous 文章
- 淺談CUTLASS / CuTe的Swizzling Functor
- CUDA 013 - Swizzle 的工作原理:网页版 swizzle 可视化
- SwizzleVis:Python 实现的 swizzle 可视化工具,网页查看结果
A.1. 其他资料
- github CUDA-Learn-Notes:很多学习用的 kernel 代码
- NVIDIA Ampere GA102 GPU Architecture Whitepaper
Enjoy Reading This Article?
Here are some more articles you might like to read next: