CUTLASS-Cute 初步(4.1):MMA Swizzle -- MMA、ldmatrix、smem swizzle
ldmatrix 指令 & HMMA 指令
一些名词:
- LDS:
LoaD Shared Memory,warp 指令,比如LDS.32 表示加载 32 位数据到寄存器 - LDSM:
LoaD Shared Memory Matrix,Tensor Core 指令,ldmatrix的 SASS 表示
ldmatrix指令为配合 Tensor Core 的 HMMA 指令使用的,数据在SMEM中的布局与mma指令一致。ldmatrix指令格式为:
ldmatrix.sync.aligned.m8n8.x4.shared.b16{.trans} { %0, %1, %2, %3 }, [ %4 ]
一个ldmatrix.x1指令加载一个8x8-BF16 = 128B矩阵,占用8个线程(比如0~7),并将从SMEM中加载的数据均分到一个warp 32个线程中,在warp线程中以32位寄存器存储。格式如下:
-
ldmatrix.x1要求提供8 x 8-BF16 SMEM地址(每个线程提供一个,共8个线程),且每个地址16B且连续。 - REG均分规律:T0 SMEM(16B = 8-BF16 = 4-REG) => T0、T1、T2、T3;T1 SMEM => T4、T5、T6、T7;…;T7 SMEM => T28、T29、T30、T31。
ldmatrix.x4指令加载一个32x8-BF16 = 512B矩阵,占用一个warp 32个线程,每个线程提供一个地址。每个线程提供4-REG = 8-BF16,对应到上述给出的ldmatrix.x4指令格式。图示如下:
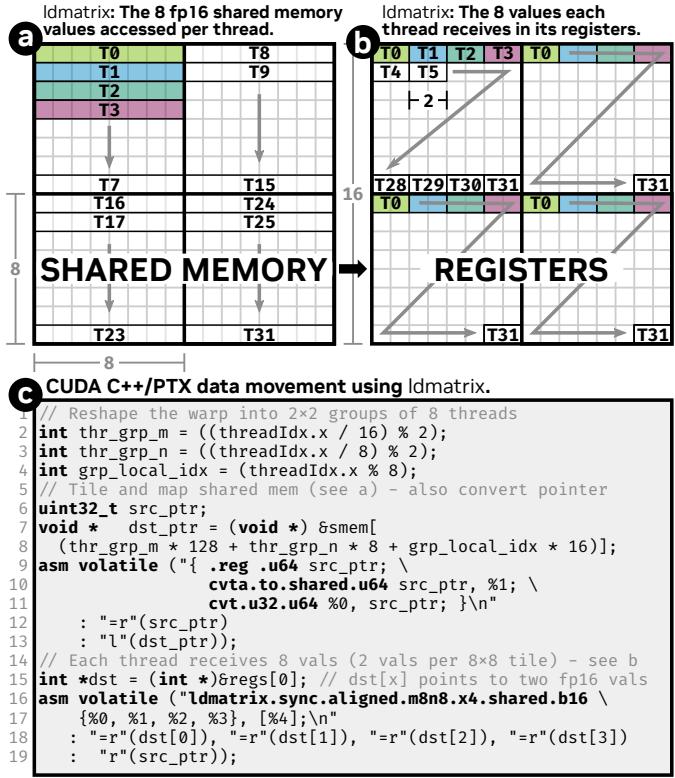
1.1. ldmatrix 与 mma 指令布局关系
以mma.sync.aligned.m16n8k8.row.col.f32.bf16.bf16.f32为例,该指令执行D = A * B +C,其中A[M, K]为row-major,B[K, N]为col-major(即B[N, K] row-major)。
以A fragment为例,该mma指令使用A[16,8],每个线程使用4-BF16(两个连续)。其SMEM的thread-value布局如下,对应官方PTX文档中的图示Figure 71 of PTX 9.0 doc:
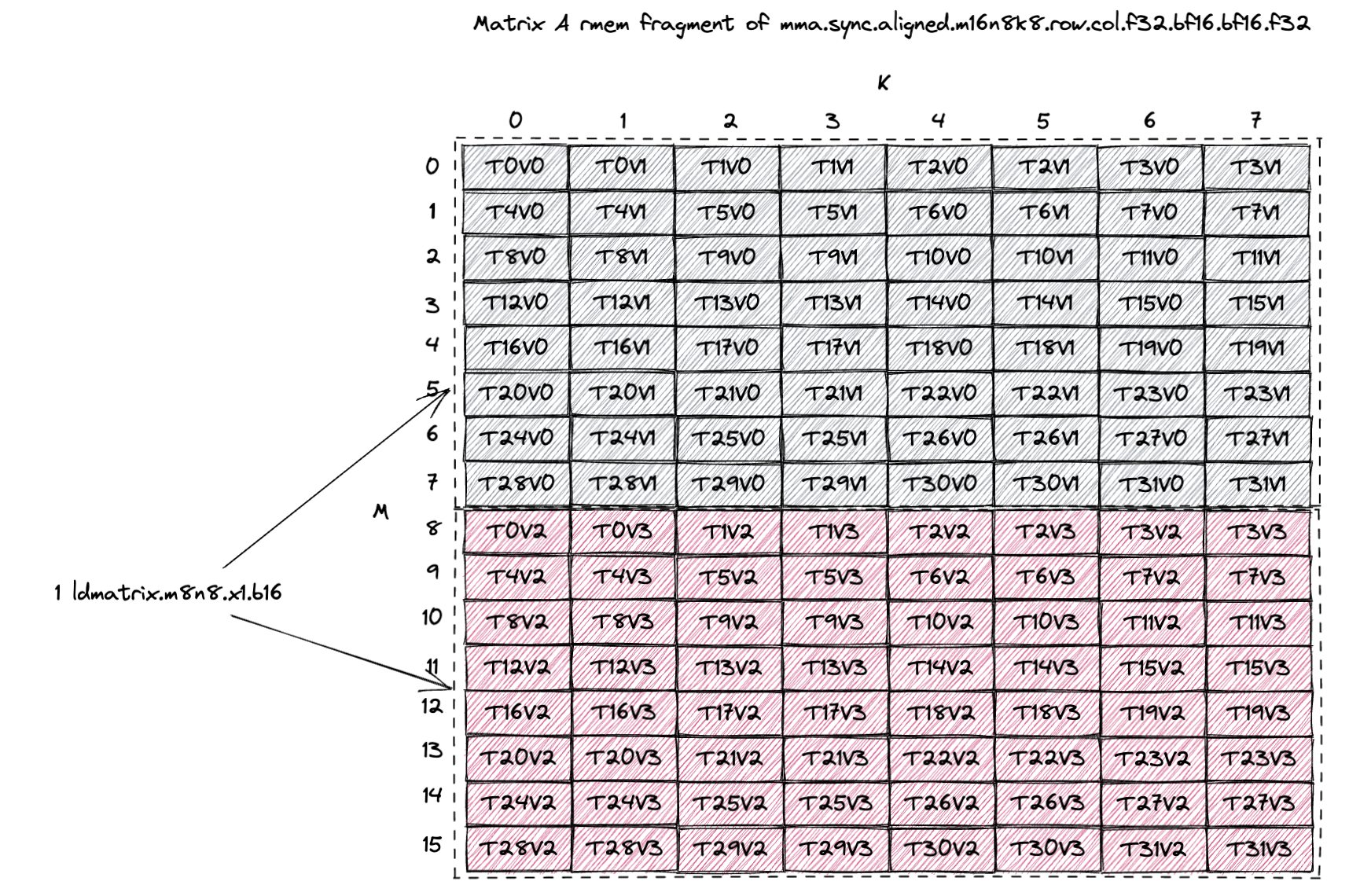
使用ldmatrix.m8n8.b16,需要两条ldmatrix.x1指令加载一个A fragment(16x8-BF16),每条指令加载8x8-BF16。上图中的示意图(上半部分或下半部分)与官方PTX文档中给出的图示Figure 104 of PTX 9.0 doc一致。
一条
ldmatrix.x1指令加载8x8-BF16 = 128B,正好等于一个32-Bank宽度。另外,ldmatrix加载以16B为单位,在分析Bank Conflict的时候,可以将32-Bank简化为8-Bank。
A. 参考资料
Enjoy Reading This Article?
Here are some more articles you might like to read next: