CUTLASS-Cute 初步(4.1):MMA Swizzle -- MMA、ldmatrix、smem swizzle
1. ldmatrix 指令 与 MMA 指令
一些名词:
- LDS:
LoaD Shared Memory,warp 指令,比如 LDS.32 表示加载 32 位数据到寄存器 - LDSM:
LoaD Shared Memory Matrix,Tensor Core 指令,ldmatrix的 SASS 表示
ldmatrix指令为配合 Tensor Core 的 MMA 指令使用的,数据在RF中的布局与mma指令一致(准确的理解应该是:加载RF之后的Thread-Value布局)。ldmatrix指令格式为(以.x1、.x4为例):
ldmatrix.sync.aligned.m8n8.x1.shared.b16{.trans} { %0 }, [ %1 ]
ldmatrix.sync.aligned.m8n8.x4.shared.b16{.trans} { %0, %1, %2, %3 }, [ %4 ]
一个ldmatrix.x1指令加载一个8x8-BF16 = 128B矩阵,占用8个线程(比如0~7),并将从SMEM中加载的数据均分到一个warp 32个线程中,在warp线程中以32位寄存器存储。格式如下:
-
ldmatrix.x1要求提供8 x (8-BF16 = 16B) SMEM地址(每个线程提供一个,共8个线程),且每个地址16B且连续。 -
REG均分规律:T0 SMEM(16B = 8-BF16 = 4-REG) => T0、T1、T2、T3;T1 SMEM => T4、T5、T6、T7;…;T7 SMEM => T28、T29、T30、T31。
ldmatrix.x4指令加载一个32x8-BF16 = 512B矩阵,占用一个warp(32个线程),依旧是每个线程提供一个16B SMEM地址。每个线程提供4-REG = 8-BF16,对应到上述给出的ldmatrix.x4指令格式。图示如下:
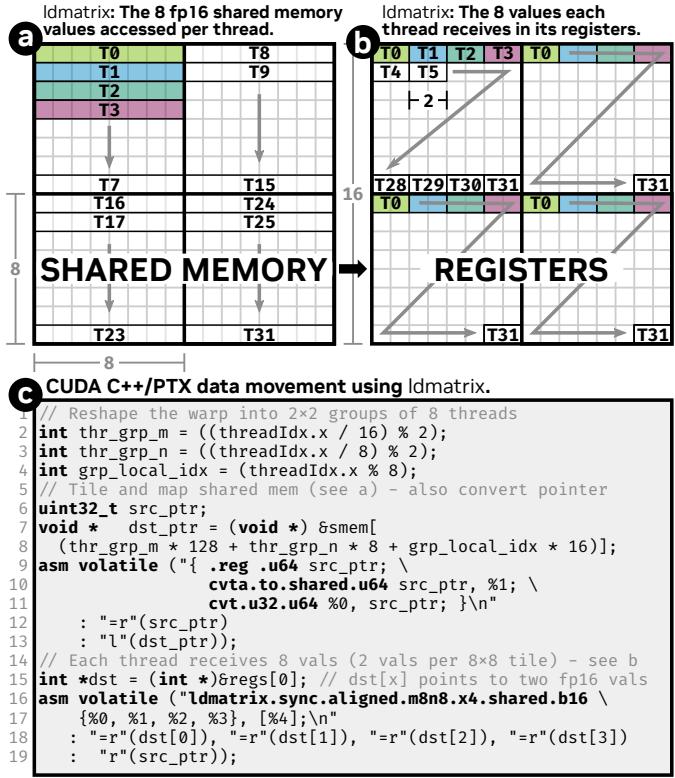
ldmatrix.x4的加载分成4个phase,即四个阶段。每个phase加载一个8x8-BF16 = 128B矩阵,且每个phase占用8个线程(比如phase使用T0~T7)。- 从图示可以看出来,
ldmatrix.x4覆盖一个16x16-BF16矩阵,按线程将其划分为2x2的子块阵列,即这个16x16-BF16矩阵可以表示为((2, 2), (8, 8))。- 在 PTX DOC 中,与上图对应的
HMMA指令是MMA.m16n18k16,对应的MMA指令的layout为 Figure 79 of PTX doc,两个图示的layout一致。- 原图修订来自知乎文章:cutlass swizzle机制解析(一)
1.1. ldmatrix 与 mma 指令布局关系
以mma.sync.aligned.m16n8k8.row.col.f32.bf16.bf16.f32(封装为cute::SM80_16x8x16_F16F16F16F16_TN)为例:
- 该指令执行
D = A * B + C。 -
A[M, K]为row-major,即对应到BLAS命名约定的T。 -
B[K, N]为col-major即对应到BLAS命名约定的N(即B[N, K] row-major)。
以A fragment为例,该mma指令使用A[16,8],每个线程使用4-BF16(两个连续)。其RF的thread-value布局如下,对应官方PTX文档9.7.14.5.7. Matrix Fragments for mma.m16n8k8中的图示:Figure 71 of PTX 9.0 doc:
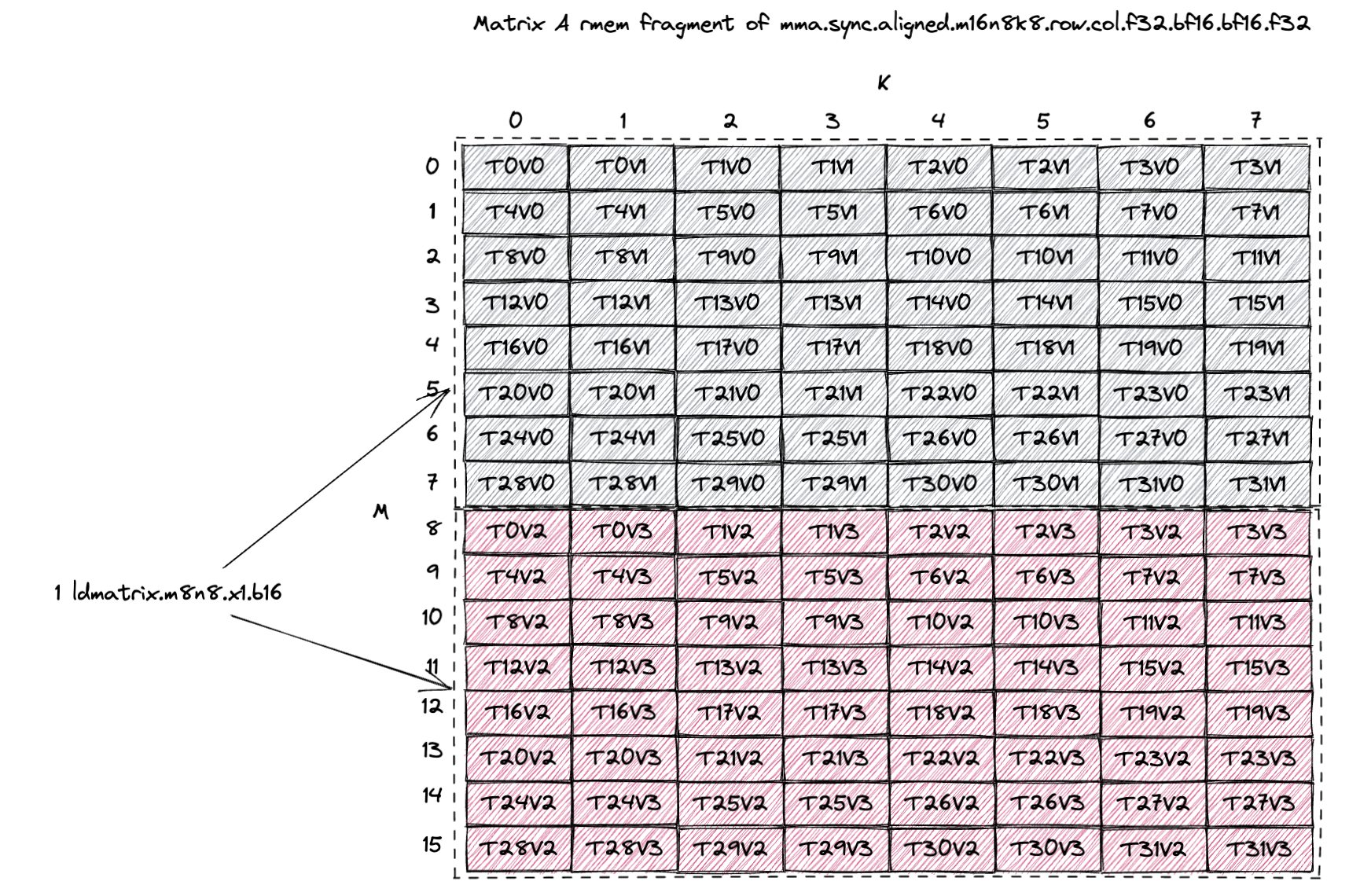
使用ldmatrix.m8n8.b16,需要两条ldmatrix.x1指令加载一个A fragment(16x8-BF16),每条指令加载8x8-BF16。上图中的示意图(上半部分或下半部分)与官方PTX文档中给出的图示:Figure 104 of PTX doc 一致。
一条
ldmatrix.x1指令加载8x8-BF16 = 128B,正好等于一个32-Bank宽度。另外,ldmatrix加载以16B为单位,在分析Bank Conflict的时候,可以将32-Bank简化为8-Bank。
由指令mma.sync.aligned.m16n8k8.row.col.f32.bf16.bf16.f32可知,B fragment的布局为col-major。官方PTX文档9.7.14.5.7. Matrix Fragments for mma.m16n8k8中给出的图示:Figure 74 of PTX doc:
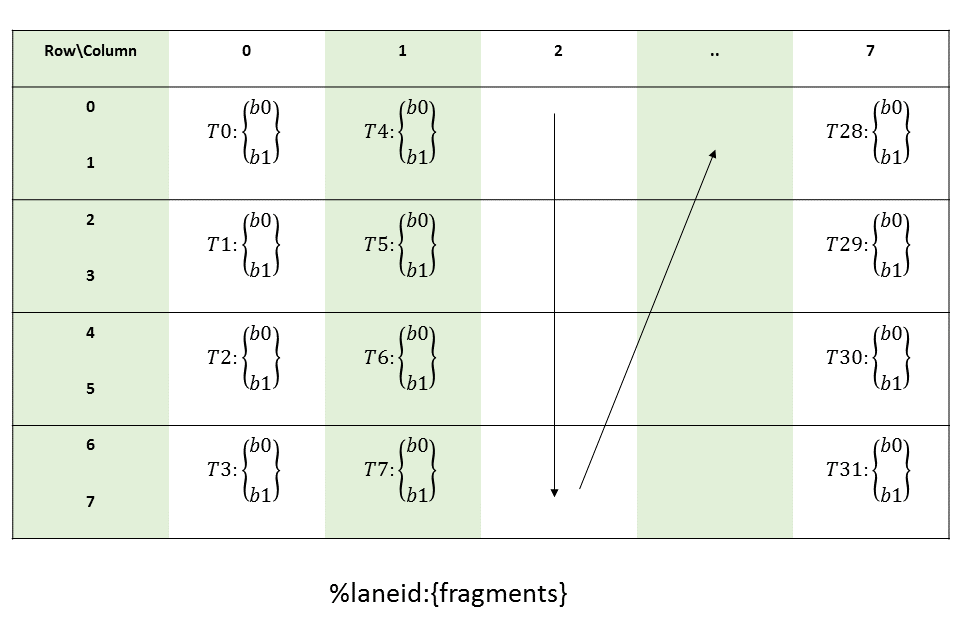
对于B fragment的加载,需要使用一条ldmatrix.m8n8.b16.trans指令。
1.2. MMA 指令的线程布局
Taking m16n8k16 FP16 as an example, the calculation distribution of elements in each tile on the threads in the warp is shown in the figure below. It can be clearly found that the fragments calculated by each thread are discontinuous.
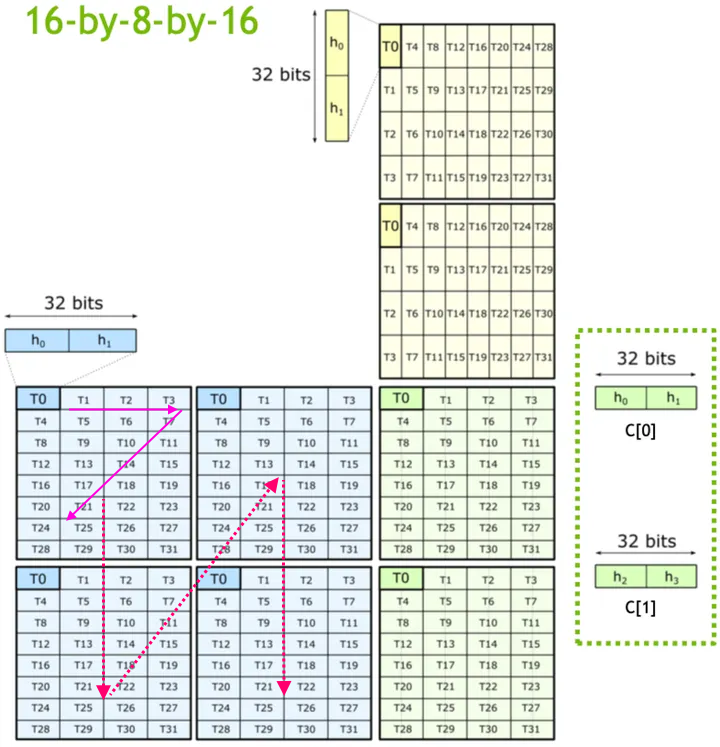
从图中可以看出,MMA中,A fragment与C fragment都是row-major,B fragment是col-major。C fragment与A fragment的布局相同,这对连续进行MMA计算非常有利,比如Flash Attention中,三个矩阵相乘,前两个矩阵计算得到的中间结果,布局满足MMA要求,可以直接用于后续计算。
另外,每个线程计算的元素在矩阵中是不连续的。
1.3. ldmatrix 与 ldmatrix.trans 布局对比
TEST(TiledCopy, Case02) {
using namespace cute;
TiledMMA mmaC = make_tiled_mma(MMA_Atom<SM80_16x8x16_F16F16F16F16_TN>{}, Layout<Shape<_1, _1>>{});
{
Copy_Atom<SM75_U32x4_LDSM_N, cute::half_t> s2r_atom_A;
TiledCopy s2r_copy_a = make_tiled_copy_A(s2r_atom_A, mmaC);
std::cout << "TiledCopy s2r_copy_a: " << std::endl;
print(s2r_copy_a);
std::cout << "\n-----------------------------" << std::endl;
print_latex(s2r_copy_a);
}
{
Copy_Atom<SM75_U16x4_LDSM_T, cute::half_t> s2r_atom_B;
TiledCopy s2r_copy_b = make_tiled_copy_B(s2r_atom_B, mmaC);
std::cout << "TiledCopy s2r_copy_b: " << std::endl;
print(s2r_copy_b);
std::cout << "\n-----------------------------" << std::endl;
print_latex(s2r_copy_b);
}
}
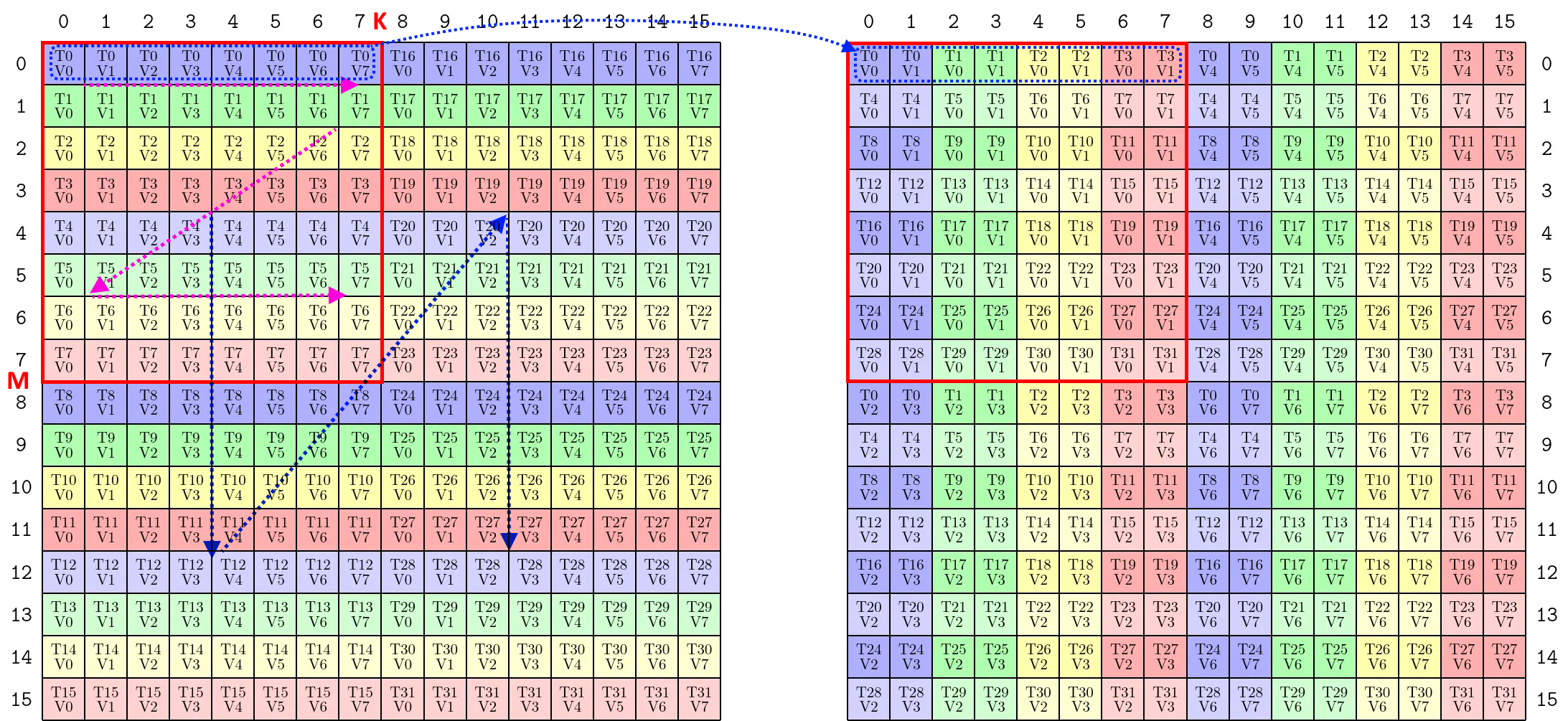
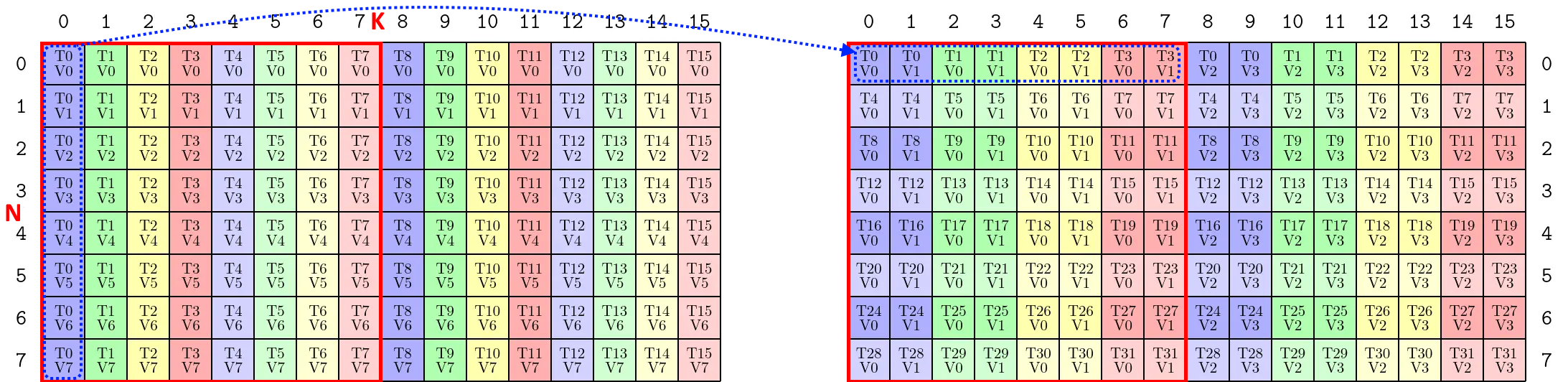
- 从上述代码,以及打印的
Inverse TV-Layout中,不能看出ldmatrix与ldmatrix.trans的区别,仅作为参考。相关文章:https://zhuanlan.zhihu.com/p/1906775725278737888。- 测试代码:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/study_tests/test_tiled_copy.cu。
MMA指令提供了几种形式,不同的指令参数,对A、B在SMEM中的布局要求如下:

以cute::SM80_16x8x16_F16F16F16F16_TN为例,要求A的形式为:(M, K) row-major(即对应到BLAS命名约定的T),B的形式为(N, K) row-major(即(K, N) column-major,对应到BLAS命名约定的N)。
在如下的完整代码示例中,使用的存储形式为A:(M, K) column-major,B:(N, K) column-major,即在我们的GEMM实现中,使用的是MN-major的存储形式。此时,需要使用ldmatrix.trans指令来加载A、B到寄存器中,即在SMEM => REG的过程中,对A、B都需要进行转置加载。
- 总结:ldmatrix.trans用于矩阵
A/B以列主序存储在共享内存时,硬件在加载过程中完成转置,使寄存器中的布局直接匹配mma.sync对A/B操作数的期望格式。- 如上参考自Mao Lei博客:CuTe ldmatrix
2. ldmatrix 指令的 Bank Conflict 分析以及 Swizzle
2.1. 一个简单的 ldmatrix Bank Conflict 示例分析
测试代码:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/test_ldmatrix/test_ldmatrix.cu,参考自https://zhuanlan.zhihu.com/p/697228676。
__global__ void ldmatrixBankConflicts() {
// tile ((2,2), (8,8))
constexpr int TILE_SIZE = 4 * 8 * 8;
__shared__ half aTile[TILE_SIZE];
const int tidx = threadIdx.x + blockDim.x * threadIdx.y;
/*
按ldmatrix.x4.m8n8的访问顺序,
tile(16, 16)拆分成4个(8, 8)子块,子块顺序为:
0 1
2 3
子块内内为行优先访问,stride为16。
*/
const int sub_tid = tidx % 8, sub_tile_idx = tidx / 8;
const int row_base = (sub_tile_idx % 2) * 8;
const int col_base = (sub_tile_idx / 2) * 8;
const int tile_offset = (row_base + sub_tid) * 16 + col_base;
// const int aTile_index = tidx % 16 * 16 + tidx / 16 * 8;
printf("tidx: %d, tile_offset: %d, bank_id:%d\n", tidx, tile_offset, tile_offset % 32);
uint32_t regs[4];
uint32_t smem = __cvta_generic_to_shared(aTile + tile_offset);
asm("ldmatrix.sync.aligned.m8n8.x4.shared.b16 { %0, %1, %2, %3 }, [ %4 ];\n"
: "=r"(regs[0]), "=r"(regs[1]), "=r"(regs[2]), "=r"(regs[3])
: "r"(smem));
}
int main(void) {
const uint3 block = {32, 1, 1};
const uint3 grid = {1, 1, 1};
ldmatrixBankConflicts<<<grid, block>>>();
cudaDeviceReset();
return 0;
}
按照ldmatrix.x4.m8n8的访问顺序,每个子块的layout为(8,8):(16,1),导致一个ldmatrix.x1指令加载的8行,会出现一个4-way bank conflict(即需要分成两个transaction)。
ldmatrix.x4.m8n8指令分成四个phase,每个phase出现一个4-way bank conflict,最终导致每个ldmatrix.x4.m8n8指令出现四个4-way bank conflict。
以16B为单位,简化成8 bank。具体加载分析如下:
T0 => Bank 0 (8-BF16 = 16B) stride = 16-BF16
T1 => Bank 2 (8-BF16 = 16B) stride = 16-BF16
T2 => Bank 4 (8-BF16 = 16B) stride = 16-BF16
T3 => Bank 6 (8-BF16 = 16B) stride = 16-BF16
T4 => Bank 0 (8-BF16 = 16B) stride = 16-BF16
T5 => Bank 2 (8-BF16 = 16B) stride = 16-BF16
T6 => Bank 4 (8-BF16 = 16B) stride = 16-BF16
T7 => Bank 6 (8-BF16 = 16B) stride = 16-BF16
即:产生了一个4-way bank conflict,且浪费了一半的SMEM带宽。
2.2. 完整的 GMEM->SMEM->REG 拷贝排布分析以及 Bank Conflict 分析
完整代码在第三部分,以下分析基于该代码示例。
定义:A tile: (M=128, K=32) M-major,定义Tread-Value Layout:(16, 8)同样是M-major的。
GMEM => SMEM访问采用uint128_t向量化拷贝。SMEM => REG使用ldmatrix.trans,每个线程提供8-half个元素的地址,单个线程的8-half地址沿着M方向连续,每个phase中,线程给出的地址沿着K方向排布。
GMEM => SMEM访问分析:每个线程拷贝一个uint128_t,按照简化8-bank分析,8个线程组成一个transaction,共128B,这128B地址连续,不会产生 bank conflict。另外,A tile在M方向上分为两次transction,之后从下一个K编号开始新的transaction,不会一次transaction跨越多个K编号。
SMEM => REG访问分析:每个线程提供一个8-half的地址,单个线程的8-half地址沿着M方向连续,每个phase中,线程给出的地址沿着K方向排布(参考上面Inverse TV-Layout中,B(N, K)的布局)。由于stride=128-half,即K方向地址不连续,故会产生4-way bank conflict。
结论:
- 在
GMEM=>SMEM,以及SMEM=>REG的过程中,以每个线程拷贝uint128字长为单位进行的拷贝,每8个线程组成一个transaction,如果这8个线程拷贝的地址连续,则没有bank conflict;如果这8个线程拷贝的地址不连续,则会产生bank conflict。ldmatrix指令中,由于每个线程提供的地址是沿着leading dimension排布的,并且SMEM的fast dimension方向长度大于uint128_t,导致前后线程地址不连续,从而产生bank conflict(即size(smem) == 128B,但是cosize(smem) > 128B)。- 在
GMEM=>SMEM过程中,线程排布沿着fast dimension的方向,能够保证每个transaction的地址连续,从而没有store bank conflict。如果调用kernel时block是二维的,则需要注意一个transaction内的线程是否是沿着fast dimension的方向。另外,如果取的是SMEM的sub-tile,则也需要注意是否会出现size(mem) == 128B,但是cosize(mem) > 128B的情况。
2.3. 使用 Swizzle 解决 ldmatrix bank conflict
以Swizzle K-major 128B为例,定义的GMEM tile、SMEM tile布局如下:
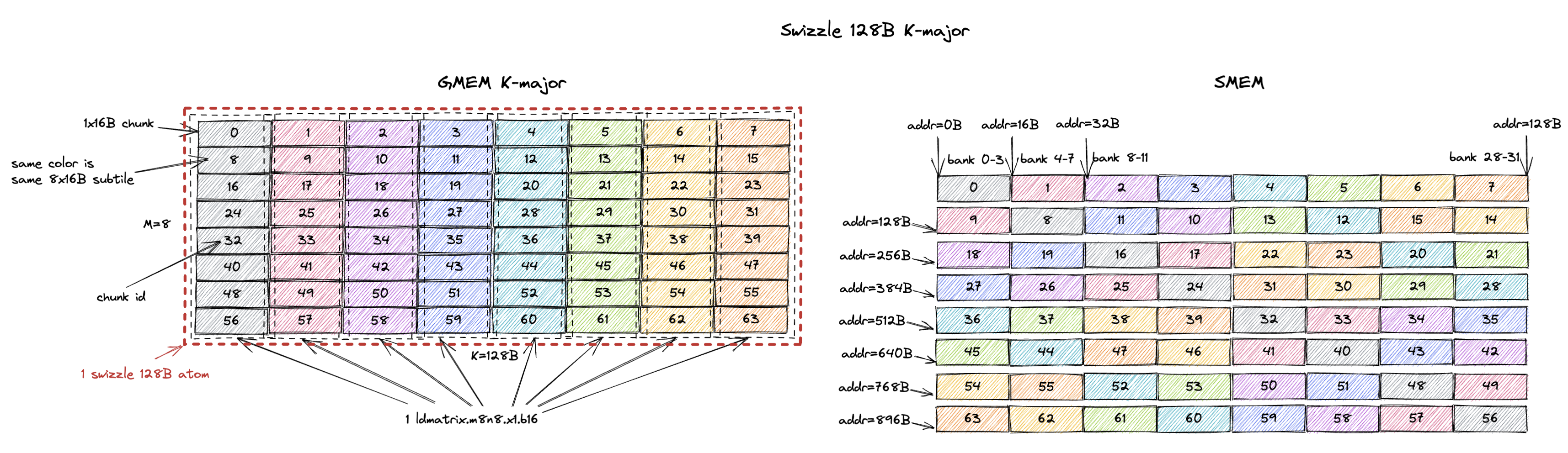
在切分CTA并创建GMEM tile(以及对应的SMEM tile)的时候,在K维度还可以有其他的切分方式,比如Swizzle K-major 64B、Swizzle M-major 32B等。使用128B K-major性能最好:此时连续的128B刚好填满一个L2 Cache Line。
GPU的L2 Cache Line大小为128B,分为4-Sectors,每个Sector为32B。同时,访问GMEM的时候,也是以Sector(32B)为单位,所以GMEM访问小于32B造成GMEM带宽浪费。
如果是列主序的,相关的GMEM tile、SMEM tile见如下图示(Swizzle MN-major 128B):
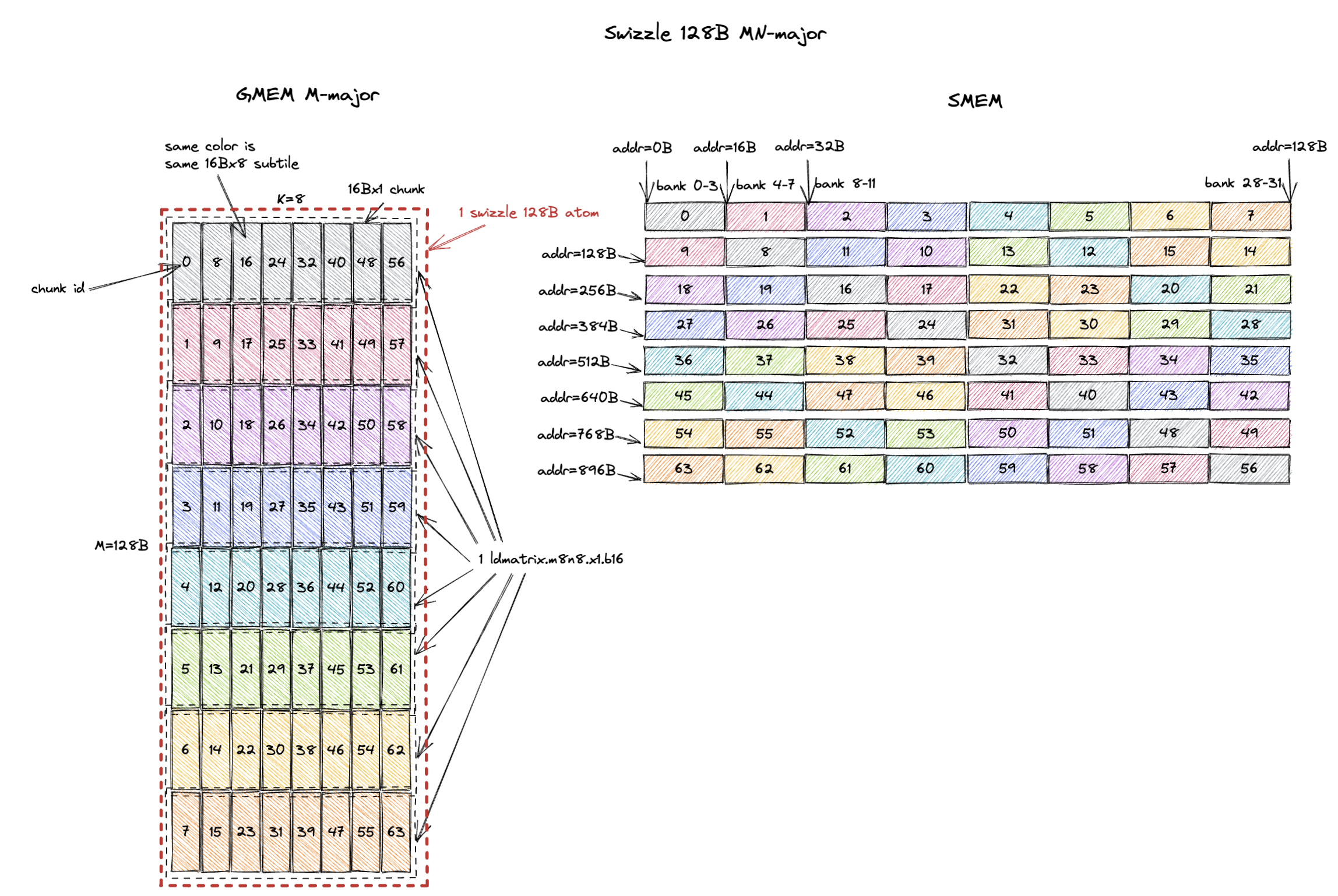
3. GMEM -> SMEM -> REG 示例及分析
- 测试代码:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/test_gmem_smem_swizzle/test_async_cp_ldmatrix.cu
- 相关代码:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/test_ldmatrix/test_ldmatrix.cu
namespace {
constexpr int constexpr_log2(int n) { //
return (n <= 1) ? 0 : 1 + constexpr_log2(n / 2);
}
} // namespace
// GMEM -> SMEM (async copy + swizzle) -> REG (ldmatrix)
// 数据流:全局内存 (列主序,M-major) -> 共享内存 (M-major + Swizzle<3,3,4>) -> 寄存器 (ldmatrix.x4.trans)
template <typename T, typename AStride, typename ASmemLayout, typename GmemTiledCopyA, typename SmemTiledCopyA, typename TiledMMA>
__global__ void kernel_load(T const* ptrA,
int M,
int K,
AStride strideA,
ASmemLayout smem_layout_A,
GmemTiledCopyA gmem_tiled_copy_A,
SmemTiledCopyA smem_tiled_copy_A,
TiledMMA tiled_mma) {
// 完整 GMEM 张量:shape=(M,K), stride=(1,M),列主序(M-major)
// A[m, k] 的地址偏移 = m*1 + k*M,M 方向连续,K 方向跨步 M(每列间隔 M*sizeof(T) 字节)
auto gmem_tensor_A = cute::make_tensor(cute::make_gmem_ptr(ptrA), cute::make_shape(M, K), strideA); // (M,K):(1,M)
// 共享内存张量:shape=(bM=128, bK=32),M-major(M stride=1 连续存储)
// 叠加 Swizzle<3,3,4> 后各行的列偏移被 XOR 打乱,用于消除 ldmatrix bank conflict
__shared__ T smem_A[cute::cosize_v<ASmemLayout>];
auto tensor_smem_A = cute::make_tensor(cute::make_smem_ptr(smem_A), smem_layout_A); // (bM=128, bK=32)
// Block tile:每个 CTA 负责 GMEM 中一块 (bM=128, bK=32) 的数据
// grid = (M/128, K/32),blockIdx.x -> M 方向,blockIdx.y -> K 方向
auto gmem_block_tensor_A = cute::local_tile(gmem_tensor_A,
cute::make_shape(cute::size<0>(smem_layout_A), cute::size<1>(smem_layout_A)),
cute::make_coord(blockIdx.x, blockIdx.y)); // (bM=128, bK=32)
// ---- Stage 1: GMEM -> SMEM via cp.async ----
// 线程布局 (16M, 8K),stride=(1,16),M-major(连续 thread ID 沿 M 方向排列)
// 每线程每次 cp.async 加载 128bit=8 个 half,沿 M 方向连续读取
// 同一 K 列:16 线程 × 16B = 256B = 2 条 128B cache line,GMEM coalescing 100%
// gmem_tAgA:当前线程负责的 GMEM 源分块,shape=(CPY=8, CPY_M, CPY_K)
// gmem_tAsA:写入 SMEM 的目标分块(地址已按 swizzle XOR 重映射),shape 同上
auto gmem_thr_copy_A = gmem_tiled_copy_A.get_slice(threadIdx.x);
auto gmem_tAgA = gmem_thr_copy_A.partition_S(gmem_block_tensor_A); // (CPY=8, CPY_M, CPY_K)
auto gmem_tAsA = gmem_thr_copy_A.partition_D(tensor_smem_A); // (CPY=8, CPY_M, CPY_K)
cute::copy(gmem_tiled_copy_A, gmem_tAgA, gmem_tAsA);
cute::cp_async_fence();
cute::cp_async_wait<0>();
__syncthreads();
// ---- Stage 2: SMEM -> REG via ldmatrix ----
// SM75_U16x8_LDSM_T:ldmatrix.sync.aligned.x4.trans(转置加载)
// 一次加载 4 个 8×8 half 矩阵 tiles = 64 字节,供 SM80_16x8x16 的 A operand 使用
// Swizzle 保证同一 warp 内 32 线程访问 SMEM 时落在不同 bank,消除 bank conflict
auto thr_mma = tiled_mma.get_slice(threadIdx.x);
auto mma_tCrA = thr_mma.partition_fragment_A(tensor_smem_A); // (MMA=(2,2), MMA_M, MMA_K)
auto smem_thr_copy_A = smem_tiled_copy_A.get_slice(threadIdx.x);
auto smem_tCsA = smem_thr_copy_A.partition_S(tensor_smem_A); // (CPY, CPY_M, CPY_K) SMEM 侧
auto smem_tCrA_view = smem_thr_copy_A.retile_D(mma_tCrA); // (CPY, CPY_M, CPY_K) REG 侧,与 mma_tCrA 共享存储
cute::copy(smem_tiled_copy_A, smem_tCsA, smem_tCrA_view);
}
void test_gmem_smem_ldmatrix() {
using T = cute::half_t;
using VectorType = cute::uint128_t;
using CopyOp = cute::SM80_CP_ASYNC_CACHEALWAYS<VectorType>;
constexpr int M = 4096, K = 4096;
thrust::random::default_random_engine rng(42);
thrust::random::uniform_real_distribution<float> dist(-1.0f, 1.0f);
thrust::host_vector<T> h_A(M * K);
thrust::generate(h_A.begin(), h_A.end(), [&]() { return T(__half(dist(rng))); });
thrust::device_vector<T> d_A_vec(h_A);
T* d_A = thrust::raw_pointer_cast(d_A_vec.data());
// GMEM 列主序(M-major):stride=(1, M),A[m,k] = ptrA + m + k*M
// M 方向 stride=1(连续),K 方向每列间隔 M*sizeof(T) 字节(非连续)
auto const strideA = cute::make_stride(cute::Int<1>{}, M);
// CTA tile 大小:bM=128(M 方向),bK=32(K 方向)
// grid = (M/128, K/32) = (32, 128) 个 CTA
constexpr auto bM = cute::Int<128>{};
constexpr auto bK = cute::Int<32>{};
// Swizzle<3,3,4>:对逻辑行号的 bit[6:4] XOR 到列地址的 bit[6:4],
// 保证同 warp 内 32 线程的 ldmatrix 访问落在 32 个不同的 SMEM bank
constexpr auto MBase_A = constexpr_log2(sizeof(cute::uint128_t) / sizeof(T)); // 3
constexpr auto BBits_A = constexpr_log2(32 * 4 / sizeof(T)) - MBase_A; // 3
constexpr auto SShift_A = constexpr_log2(bM) - MBase_A; // 4
constexpr auto swizzle_A = cute::Swizzle<BBits_A, MBase_A, SShift_A>{}; // Swizzle<3,3,4>
// smem_atom_layout_A:基础原子 layout,shape=(128M, 8K),stride=(1,128),M-major
// 一列 8 个 uint128_t = 128 个 half,正好是 ldmatrix.x4 一个 phase 的加载量
// smem_atom_layout_A_swizzled:叠加 Swizzle,不改变 shape,只重映射地址
// smem_layout_A:tile_to_shape 将 K 扩展到 bK=32(沿 K 方向 tiling 4 次),shape=(128M, 32K)
constexpr auto smem_atom_layout_A = cute::make_layout(cute::make_shape(bM, cute::Int<8>{})); // (128,8):(1,128)
constexpr auto smem_atom_layout_A_swizzled = cute::composition(swizzle_A, smem_atom_layout_A);
constexpr auto smem_layout_A = cute::tile_to_shape(smem_atom_layout_A_swizzled, cute::make_shape(bM, bK)); // (128,32), M-major
// ---- GMEM -> SMEM tiled copy ----
// thread_layout_A:128 线程映射到 tile (bM=128, bK=32) 的方式
// shape=(16M, 8K),stride=(1,16),M-major(连续 thread ID 沿 M 方向增长)
// thread t: M_pos = t%16,K_pos = t/16
// 与 GMEM M-major 对齐:相邻线程访问相邻地址 → 完美 coalescing
constexpr auto thread_shape_A = cute::make_shape(cute::Int<16>{}, cute::Int<8>{}); // (16M, 8K)
constexpr auto thread_stride_A = cute::make_stride(cute::Int<1>{}, cute::size<0>(thread_shape_A)); // (1, 16),M-major
constexpr auto thread_layout_A = cute::make_layout(thread_shape_A, thread_stride_A);
// vector_layout_A:每次 cp.async 加载的向量形状
// uint128_t = 16 字节 = 8 个 half → shape=(8M, 1K),沿 M 方向连续加载
// 16 线程 × 8 元素 = 128 half/列,恰好覆盖 bM=128
// 同一 K 列:16 线程 × 16B = 256B = 2 条 128B cache line,L2 利用率 100%
constexpr auto NUM_ELEMENTS_A = sizeof(VectorType) / sizeof(T); // 8 fp16 per uint128_t
constexpr auto vector_shape_A = cute::make_shape(cute::Int<NUM_ELEMENTS_A>{}, cute::Int<1>{}); // (8M, 1K)
constexpr auto vector_stride_A = cute::make_stride(cute::Int<1>{}, cute::size<0>(vector_shape_A));
constexpr auto vector_layout_A = cute::make_layout(vector_shape_A, vector_stride_A);
// gmem_tiled_copy_A:SM80_CP_ASYNC_CACHEALWAYS,128bit 粒度异步拷贝
// 整个 tile (128×32) = 8192 half = 16KB,128 线程 × 8 元素/次 × 4 轮 = 4096 元素/轮
constexpr auto gmem_tiled_copy_A = cute::make_tiled_copy(cute::Copy_Atom<CopyOp, T>{}, thread_layout_A, vector_layout_A);
// ---- TiledMMA:SM80_16x8x16,mma_layout=(2M,2N,1K),mma_tile=(32M,32N,16K) ----
// MMA atom SM80_16x8x16:单次 mma.sync.aligned.m16n8k16,A operand shape=(16M, 16K)
// mma_layout (2,2,1):warp 内沿 (M,N,K) 排列 2×2×1 个 atom,扩大计算覆盖范围
// mma_tile (32,32,16):在 mma_layout 基础上再 tiling,最终每 warp 覆盖 (32M,32N,16K)
// 总线程数 = 32(warp) × MMA_LAYOUT_M × MMA_LAYOUT_N × MMA_LAYOUT_K = 32×2×2×1 = 128
using MMATraits = cute::MMA_Traits<cute::SM80_16x8x16_F16F16F16F16_TN>;
using MMAAtomShape = MMATraits::Shape_MNK; // (16M, 8N, 16K)
constexpr auto mma_atom = cute::MMA_Atom<MMATraits>{};
constexpr auto mma_atom_shape = MMAAtomShape{};
constexpr int MMA_LAYOUT_M = 2, MMA_LAYOUT_N = 2, MMA_LAYOUT_K = 1; // CTA内 warp 排布
constexpr int NUM_MMA_TILE_M = 1, NUM_MMA_TILE_N = 2, NUM_MMA_TILE_K = 1;
constexpr auto MMA_TILE_M = cute::get<0>(mma_atom_shape) * NUM_MMA_TILE_M * MMA_LAYOUT_M; // 16*1*2=32
constexpr auto MMA_TILE_N = cute::get<1>(mma_atom_shape) * NUM_MMA_TILE_N * MMA_LAYOUT_N; // 8*2*2=32
constexpr auto MMA_TILE_K = cute::get<2>(mma_atom_shape) * NUM_MMA_TILE_K * MMA_LAYOUT_K; // 16*1*1=16
constexpr auto mma_layout =
cute::make_layout(cute::make_shape(cute::Int<MMA_LAYOUT_M>{}, cute::Int<MMA_LAYOUT_N>{}, cute::Int<MMA_LAYOUT_K>{}));
constexpr auto mma_tile = cute::make_tile(cute::Int<MMA_TILE_M>{}, cute::Int<MMA_TILE_N>{}, cute::Int<MMA_TILE_K>{});
constexpr auto tiled_mma = cute::make_tiled_mma(mma_atom, mma_layout, mma_tile); // 128 threads total
// ---- SMEM -> REG tiled copy via ldmatrix ----
// SM75_U16x8_LDSM_T:ldmatrix.sync.aligned.x4.trans(转置加载)
// 一次加载 4 个 8×8 half 矩阵片段 = 64 字节,供 SM80_16x8x16 的 A operand 使用
// make_tiled_copy_A 根据 tiled_mma 自动推导与 MMA atom A operand 匹配的分片方案
using Copy_Atom_A = cute::Copy_Atom<cute::SM75_U16x8_LDSM_T, T>;
constexpr auto smem_tiled_copy_A = cute::make_tiled_copy_A(Copy_Atom_A{}, tiled_mma);
// block=128 线程(4 warp),grid=(M/bM, K/bK)=(32, 128)
dim3 block(cute::size(tiled_mma)); // 128 threads
dim3 grid(M / bM, K / bK);
kernel_load<<<grid, block>>>(d_A, M, K, strideA, smem_layout_A, gmem_tiled_copy_A, smem_tiled_copy_A, tiled_mma);
if (cudaError_t err = cudaDeviceSynchronize(); err != cudaSuccess) {
std::cout << "CUDA error: " << cudaGetErrorString(err) << std::endl;
}
}
3.1. GEMM 分块考虑
GMEM分块为(bM=128, bK=32),M-major,每个CTA负责一个分块。线程布局为(16M, 8K),M-major,一个线程负责加载一个128-bit=8 half的向量,线程沿M方向连续访问,M方向16个线程,16 * 8 = 128 half = 256B,填满两条L2 cache line(使用cp.async将数据从GMEM加载到SMEM)。
3.2. Swizzle 设计分析
Swizzle设计。按照uint128_t = 16B = 8 half简化为8-Bank,得到Swizzle<BBits=3, MBase=3, SShift=?>,即交换模式有$2^{B}=2^{3}=8$个(uint128_t),覆盖长度$2^{B+M}=2^{3+3}=64$个half。如果取SShift=3,则整个交换周期覆盖的长度为$2^{B+M+S}=2^{3+3+3}=512$个half。
由于ldmatrix一个phase需要8列,又bM=128,可以取atom_shape=(128, 8)。
此时取SShift=4,则整个交换周期覆盖的长度为$2^{B+M+S}=2^{3+3+4}=1024=128 \times 8$个half,即覆盖整个atom_shape。在本例中,bM=128,所以取SShift=4,保证交换周期覆盖整个bM维度。
该Swizzle可以保证ldmatrix的一个phase在K方向上8个uint128_t读取不冲突,也可以保证GMEM -> SMEM不冲突(16个线程从GMEM的M方向上取连续的128 half,其中每个线程取1 uint128_t = 8 half),并存到经过Swizzle之后的SMEM中(GMEM(m, k) => SMEM(m, k'))。
ldmatrix一个phase拷贝,线程排布是K方向上连续,GMEM -> SMEM的线程排布是M方向上连续,Swizzle设计保证了两者都不冲突。
3.3. GMEM -> SMEM 线程划分结果计算
CTA的tile大小为(128M, 32K),Thread-Value布局为((16M, 8K), (8M, 1K)),每个线程在M方向上拷贝uint128_t=8 half,即(8M, 1K)中的8M。Tiler大小为(128, 8)。
TiledCopy
Tiler_MN: (_128,_8)
TiledLayout_TV: (_128,_8):(_8,_1)
Copy_Atom
ThrID: _1:_0
ValLayoutSrc: (_1,_8):(_0,_1)
ValLayoutDst: (_1,_8):(_0,_1)
ValLayoutRef: (_1,_8):(_0,_1)
ValueType: 16b
打印信息给出了两个信息,Tiler大小,线程布局。这个TiledCopy覆盖范围为(128M, 8K)。线程布局为一个线程负责拷贝连续的8 half,且线程在M方向上连续。
Inverse TV-Layout展示如下:

从上图看到S与D的线程访问模式一样(即layout一样),这是因为根据Copy_Traits定义:
template <class S, class D>
struct Copy_Traits<SM80_CP_ASYNC_CACHEALWAYS<S,D>>
{
using SrcLayout = Layout<Shape<_1, Int<sizeof_bits<S>::value>>>; // S = uint128_t → 128 bits
using DstLayout = Layout<Shape<_1, Int<sizeof_bits<D>::value>>>; // D = uint128_t → 128 bits
};
// using CopyOp = cute::SM80_CP_ASYNC_CACHEALWAYS<VectorType>;
如注释行给出的实例参数,S与D的CopyOperation一样,所有布局也一样。
测试代码链接:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/study_tests/test_tiled_copy.cu。
另外,如果将vector_layout_A改为(16,1):(1,16),得到:
TiledCopy
Tiler_MN: (_256,_8)
TiledLayout_TV: (_128,_16):(_16,_1)
Copy_Atom
ThrID: _1:_0
ValLayoutSrc: (_1,_8):(_0,_1)
ValLayoutDst: (_1,_8):(_0,_1)
ValLayoutRef: (_1,_8):(_0,_1)
ValueType: 16b
3.4. tiled mma 及 smem tiled copy
MMAOperation使用SM80_16x8x16_F16F16F16F16_TN,覆盖MNK=(16, 8, 16),并且在MNK分别扩展为(2-layout, 2-layout * 2-tile, 1-layout)。即:
- 对矩阵A,在
M方向上线程扩展为2倍,占用线程32*2=64个,覆盖(32M, 16K),每个线程负责A中$32 \times 16 \div 64 = 8 half$。 - 对矩阵B,在
N方向上线程扩展为2倍,占用线程32*2=64个。另外N方向上Atom重复2次,可以覆盖(2*16N, 16K),每个线程负责B中$16 \times 16 \div 64 = 4 half$。其中,占用线程T0~T31、T64~T95。
配置的TiledMMA,其Inverse TV-Layout如下图所示:

由于MMA指令对数据在RF中的布局有特定格式要求,在创建SMEM TiledCopy,以及划分线程SMEM -> REG拷贝操作时,都需要使用到TiledMMA的布局。比如针对A tile:
using Copy_Atom_A = cute::Copy_Atom<cute::SM75_U16x8_LDSM_T, T>;
constexpr auto smem_tiled_copy_A = cute::make_tiled_copy_A(Copy_Atom_A{}, tiled_mma);
auto thr_mma = tiled_mma.get_slice(threadIdx.x);
auto mma_tCrA = thr_mma.partition_fragment_A(tensor_smem_A); // (MMA=(2,2), MMA_M, MMA_K)
auto smem_thr_copy_A = smem_tiled_copy_A.get_slice(threadIdx.x);
auto smem_tCsA = smem_thr_copy_A.partition_S(tensor_smem_A); // (CPY, CPY_M, CPY_K) SMEM 侧
auto smem_tCrA_view = smem_thr_copy_A.retile_D(mma_tCrA); // (CPY, CPY_M, CPY_K) REG 侧,与 mma_tCrA 共享存储
cute::copy(smem_tiled_copy_A, smem_tCsA, smem_tCrA_view);
ThreadCopy负责线程执行MMA需要的REGs。另一方面由于源layout与目的layout不同,所以需要retile_D,将目的layout(RF layout)调整为与源layout(SMEM layout)一致。打印的layout信息如下:
smem_tCsA (src):
smem_ptr[16b](0xffffa6000000) o ((_8,_1),(_2,_2),_2):((_1,_0),(32,_64),_2048)
mma_tCrA (dst):
ptr[16b](0xffffa4fffc60) o ((_2,_2,_2),_4,_2):((_1,_2,_4),_8,_32)
smem_tCrA_view (dst view):
ptr[16b](0xffffa4fffc60) o ((_8,_1),_4,_2):((_1,_0),_8,_32)
3.5. 有关Inverse TV-Layout图示的说明
上面Inverse TV-Layout的图示中A只有64个线程,实际上CTA中128个线程都有从SMEM中加载数据,只不过可以分为两个64线程group,这两个group从SMEM上加载的位置相同,即SMEM被加载了两次,但是加载到不同的thread group的寄存器中,图示不能体现出来。
tiled_mma infomation:
TiledMMA
ThrLayoutVMNK: (_32,_2,_2,_1):(_1,_32,_64,_0)
PermutationMNK: (_32,_32,_16)
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_16,_8,_16)
LayoutA_TV: ((_4,_8),(_2,_2,_2)):((_32,_1),(_16,_8,_128))
LayoutB_TV: ((_4,_8),(_2,_2)):((_16,_1),(_8,_64))
LayoutC_TV: ((_4,_8),(_2,_2)):((_32,_1),(_16,_8))
smem_tiled_copy_A infomation:
TiledCopy
Tiler_MN: (_32,_16)
TiledLayout_TV: ((_4,_8,_2,_2),((_2,_2,_2),(_1,_1))):((_64,_1,_16,_0),((_32,_8,_256),(_0,_0)))
Copy_Atom
ThrID: _32:_1
ValLayoutSrc: (_32,_8):(_8,_1)
ValLayoutDst: ((_4,_8),(_1,_2,_4)):((_16,_1),(_1,_8,_64))
ValLayoutRef: ((_4,_8),(_1,_2,_4)):((_16,_1),(_1,_8,_64))
ValueType: 16b
以ThrLayoutVMNK为例,$t=V \times 1 + M \times 32 + N \times 64 + K \times 0$。这个128线程完整映射表:
| 线程 ID 范围 | V | M | N | K |
|---|---|---|---|---|
| 0 .. 31 | 0-31 | 0 | 0 | 0 |
| 32 .. 63 | 0-31 | 1 | 0 | 0 |
| 64 .. 95 | 0-31 | 0 | 1 | 0 |
| 96 .. 127 | 0-31 | 1 | 1 | 0 |
由于mma指令时按照warp执行的,实际执行时,128个线程被拆分为4个warp执行,每个warp执行计算得到相应的C(M', N')。得到如下执行分配关系:
| 计算 | 发起线程 | 需要 A 数据 | 需要 B 数据 |
|---|---|---|---|
| C[M, N0] = A × B[:,N0] | threads 0-31, 32-63 (N-group 0) | ✓ 在自己 REG 里 | N0 片段 |
| C[M, N1] = A × B[:,N1] | threads 64-95, 96-127 (N-group 1) | ✓ 在自己 REG 里 | N1 片段 |
对矩阵A,N=0与N=1时,分别从同一个SMEM加载两次A tile,但是分别加载到不同的线程组(64线程)的寄存器中了。针对B tile的加载也是同理。
| Operand | 冗余维度 | 加载次数 | 原因 |
|---|---|---|---|
| A | N | ×2 | N=0 组和 N=1 组各 load 一次相同 SMEM A |
| B | M | ×2 | M=0 组和 M=1 组各 load 一次相同 SMEM B |
4. 辅助用测试代码列表
- GMEM -> SMEM,ldmatrix & mma,Swizzle完整流程测试代码:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/test_gmem_smem_swizzle/test_async_cp_ldmatrix.cu
- GMEM -> SMEM 的Swizzle配置测试代码:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/test_gmem_smem_swizzle/test_gemm_smem_swizzle.cu
- ldmatrix与ldmatrix.trans对比测试(以及打印latex):https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/study_tests/test_tiled_copy.cu
- mma打印信息以及latex:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/study_tests/test_mma.cu
- 另一个测试ldmatrix加载不同大小SMEM tile时bank conflict情况分析:https://github.com/HPC02/cuda_perf/blob/master/src/study_codes/test_ldmatrix/test_ldmatrix.cu
A. 参考资料
- Tensor Core MMA Swizzle Layout:杨轶凡博客
- cute 之 Swizzle:知乎reed文章中,ldmatrix 相关内容
- tensorcore中ldmatrix指令的优势是什么?
- Graphene: An IR for Optimized Tensor Computations on GPUs
- Graphene: An IR for Optimized Tensor Computations on GPUs:来自 papaercache 的中文翻译
- CuTe ldmatrix:毛磊博客
- ldmatrix与swizzle(笔记)
- 实用 Swizzle 教程(一)
- cute代码仓库 – gemm_config for sm80
A.1. GTC 资料
- CUDA Techniques to MaximizeCompute and Instruction Throughput
- A Generalized Micro-kernel Abstraction for GPU Linear Algebra
- CuTe– CUDA Tensors
- Speaking Tensor Cores with CUTLASS 2024
A.2. 相关工具
- Excalidraw:白板工具,提供VSCode插件
Enjoy Reading This Article?
Here are some more articles you might like to read next: