CUDA GEMM 计算优化、Multi-Stage 与软流水(Software Pipelining)
整个GEMM可用如下公式表示:
\[C[i, j] = \sum_{k=0}^{nK-1} A[i, k] \times B[k, j]\]| 层级 | 说明 |
|---|---|
| Thread Block | Tile 每个 CUDA 线程块(thread block)负责计算输出矩阵 C 的一个子块(tile) |
| Warp Tile | 在线程块内部,每个 warp(32个线程)负责计算 thread block tile 的一个子区域 |
| Thread Tile | 在 warp 内部,每个线程负责计算 warp tile 的一个更小的子区域 |
1. GEMM 计算步骤–分层 GEMM 结构
依照硬件架构层次划分(也即 CUDA 编程模型),GEMM 计算可以分为多个层次:Thread Block Tile -> Warp Tile -> Thread Tile。即将一个大矩阵的算术运算,依次分解,直到最小的线程级别,一个线程计算一小部分的 tile。
数据搬运过程分为几步:GMEM -> Shared Memory -> Register File -> CUDA Core。如下图所示:
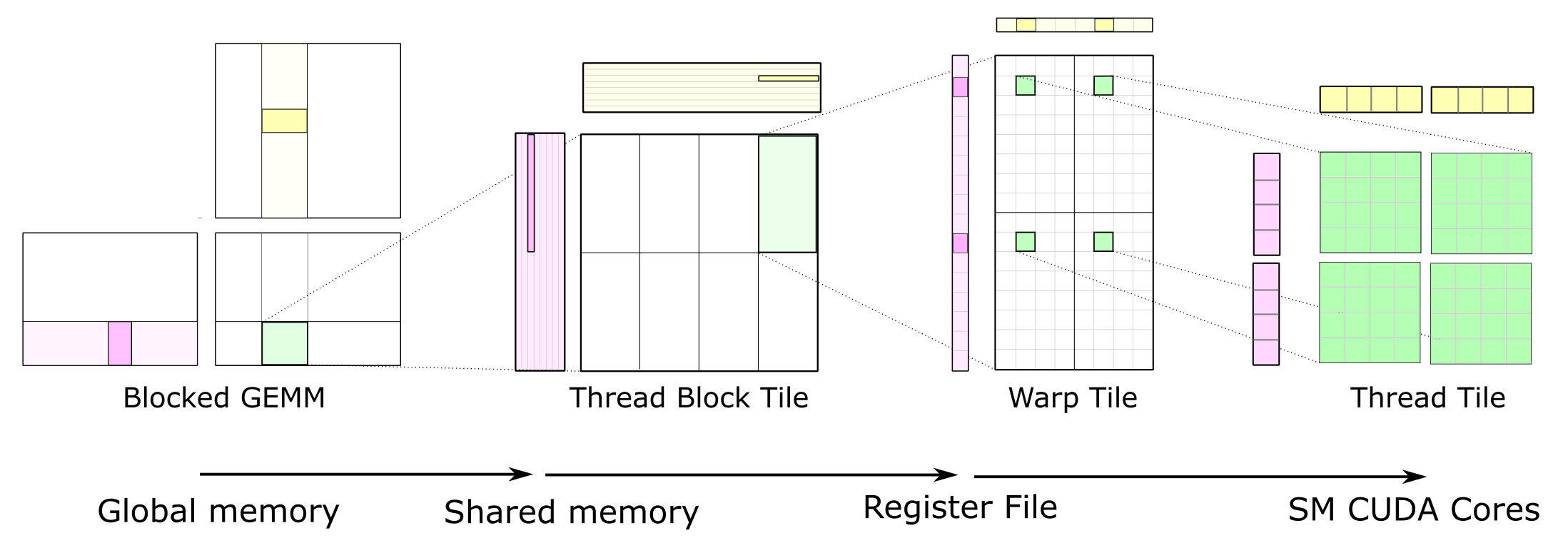
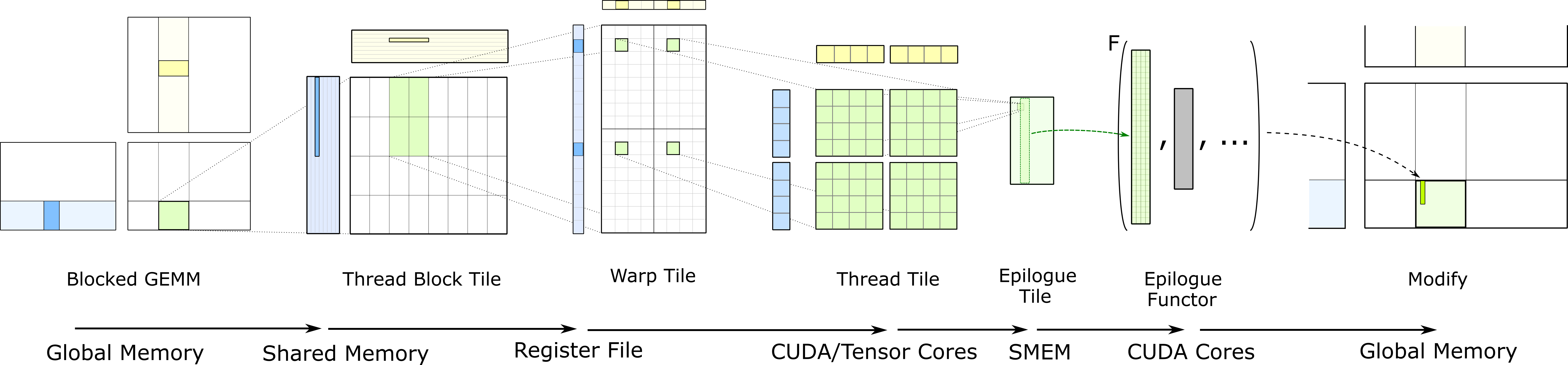
完整的 GEMM 分层结构把数据从较慢的存储器搬运到较快的存储器,并在许多算术运算中对其进行重复利用,以提高计算强度。
2. Thread Block Tile
每个 Thread Block 负责计算输出矩阵 C 的一个 Tile(即几个分块)。对于几个矩阵计算C += A * B,每个 Thread Block 需要反复从输入矩阵中加载一个个的 Tile 并计算一个累加的矩阵乘积。如下图所示:
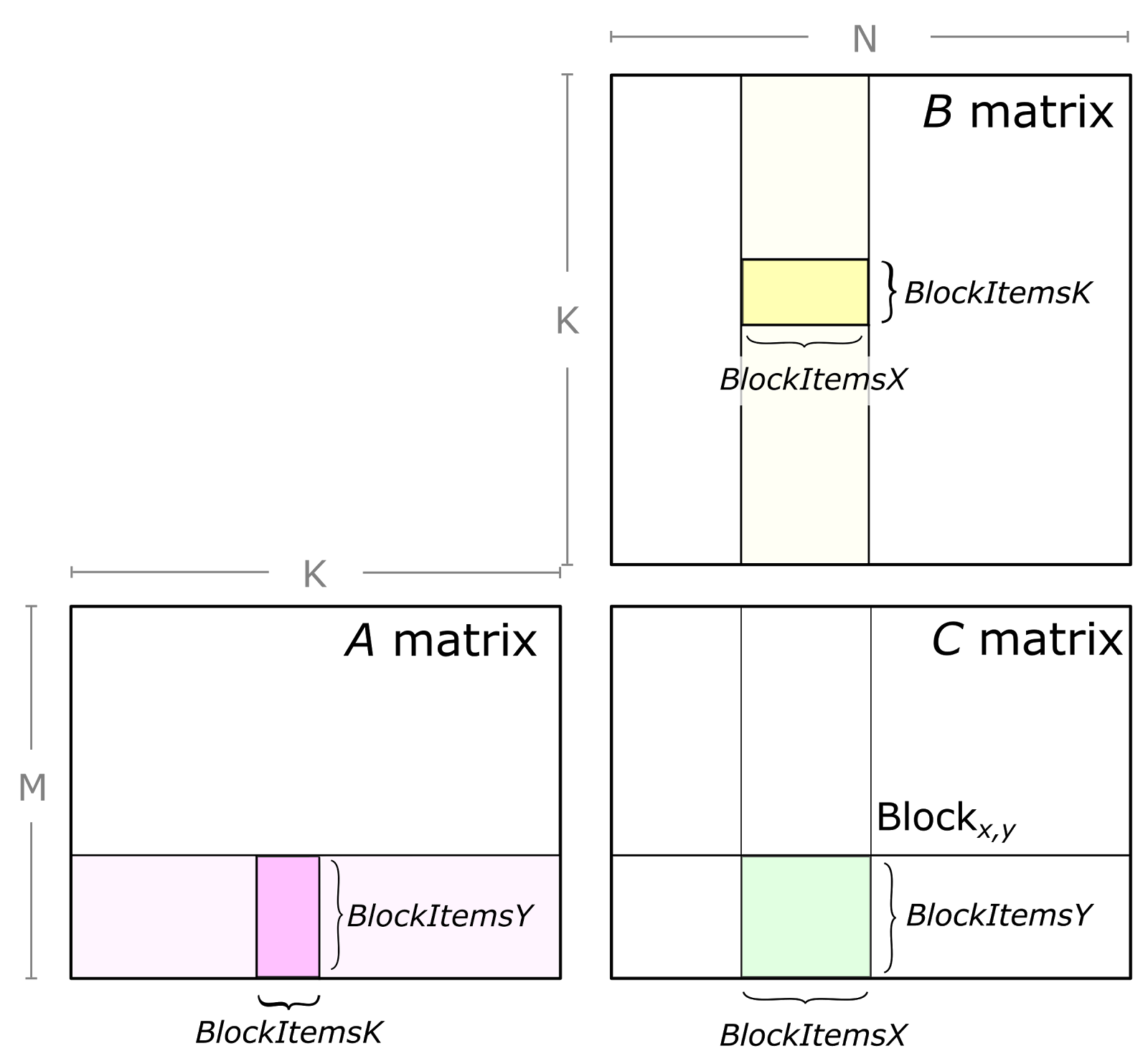
把一个 GEMM 问题分解为由单个线程块执行的计算。绿色所示的 C 的子矩阵,是由 A 的一个 tile 与 B 的一个子矩阵做矩阵乘积得到的。为此,沿 K 维(已被切分成多个 tile)循环,并把每个 tile 的矩阵乘积结果累加起来完成计算。
在逻辑上,Thread Block Tile 又被分为若干个 Warp Tile,每个 Warp Tile 由一个 Warp 负责计算。
线程块的输出 tile按空间被划分给各个 warp(如下图所示)。我们把用于存放这个输出 tile 的存储称为累加器(accumulators),因为它保存的是累加起来的矩阵乘积结果。每进行一次算术运算就会更新一次累加器,因此它必须驻留在 SM 中最快的存储器里:寄存器文件。
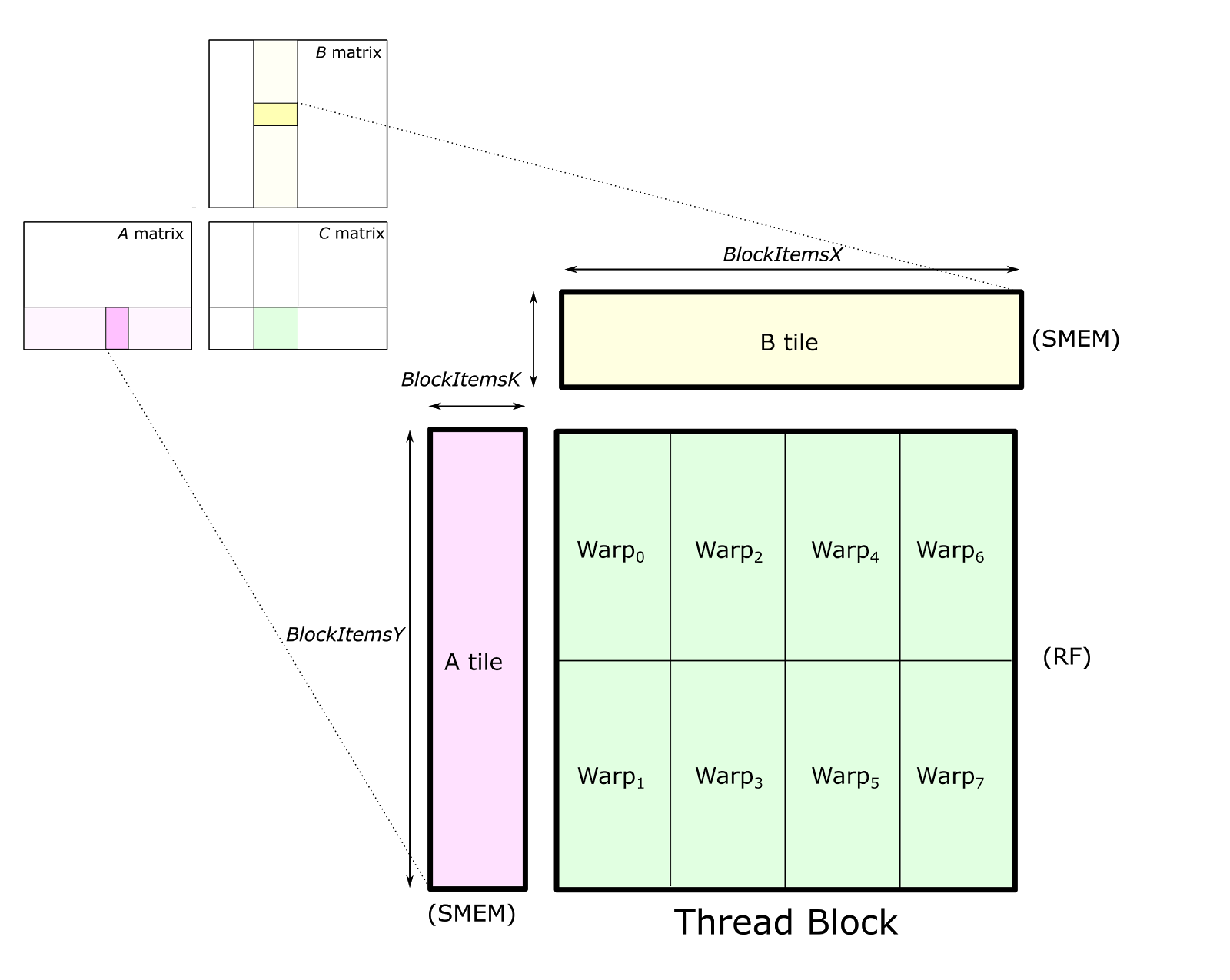
线程块的结构把 C 的一个 tile 划分给多个 warp,每个 warp 负责存储一个互不重叠的二维子块。每个 warp 都将其累加器元素存放在寄存器中。矩阵 A 和 B 的 tile 则存放在共享内存中,线程块内所有 warp 都可访问。
3. Warp Tile
当数据已存入共享内存后,每个 warp 通过在其线程块 tile 的 K 维上迭代、从共享内存中加载子矩阵(或称 fragment),并计算累加的外积。如下图所示:
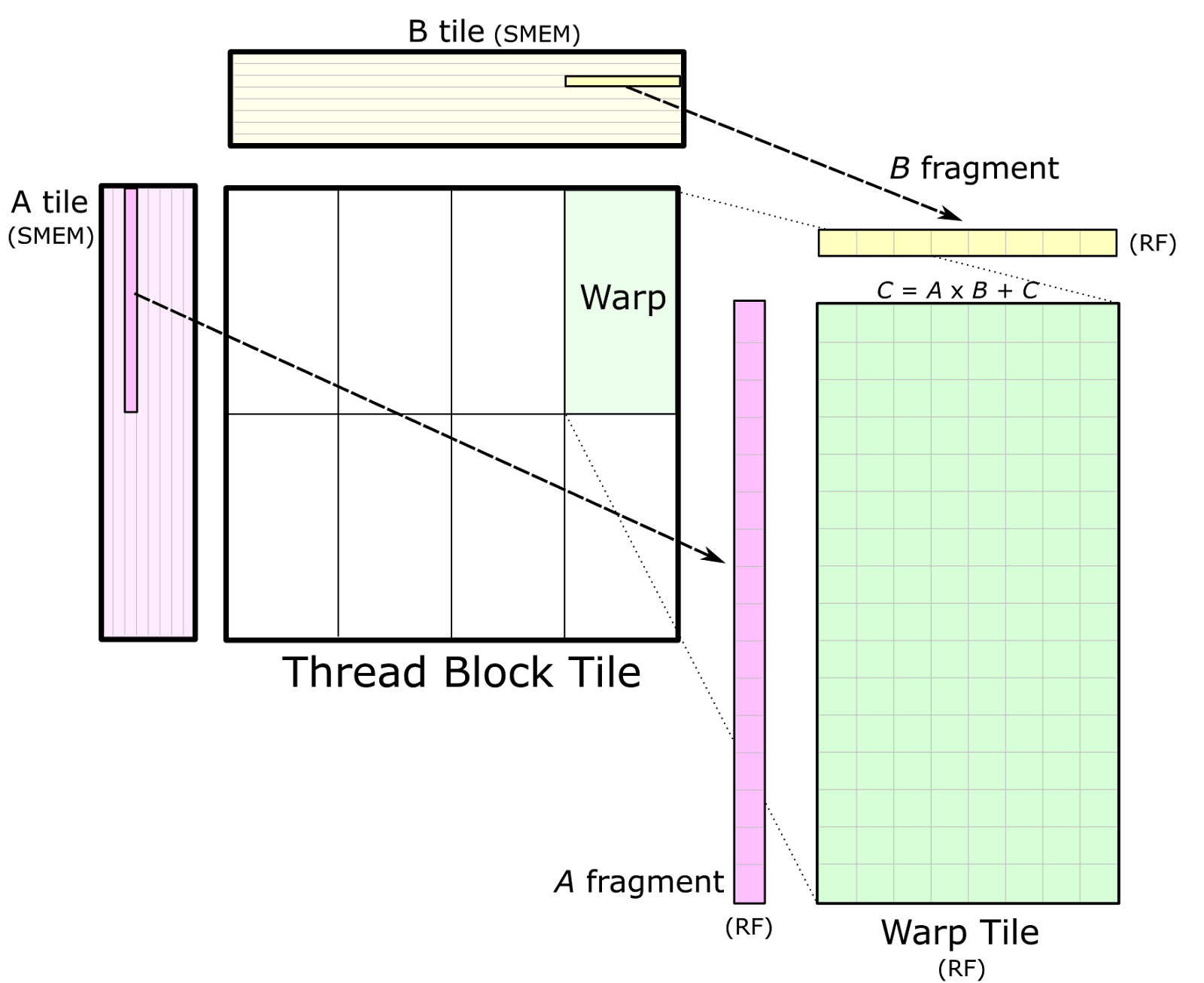
单个 warp 通过在循环中把 A 和 B 的片段(fragments)从各自对应的共享内存(SMEM)tile 加载到寄存器(RF),并计算外积,从而形成累加的矩阵乘积。
上图也展示了多个 warp 之间如何从共享内存进行数据共享:同一线程块行(row)中的 warp 会加载相同的 A 片段;同一线程块列(column)中的 warp 会加载相同的 B 片段。
4. Thread Tile
CUDA 编程模型是以线程块和单个线程来定义的。因此,warp 的结构需要映射到各个线程实际执行的操作上。由于线程之间不能互相访问寄存器,我们必须选取一种组织方式,使得保存在寄存器中的值能够被同一线程执行的多条算术指令反复复用。由此,在单个线程内部形成了一个二维分块(2D tiled)的结构,如下图的细节所示。每个线程向 CUDA 核心发出一串彼此独立的算术指令,并计算一个累加的外积。
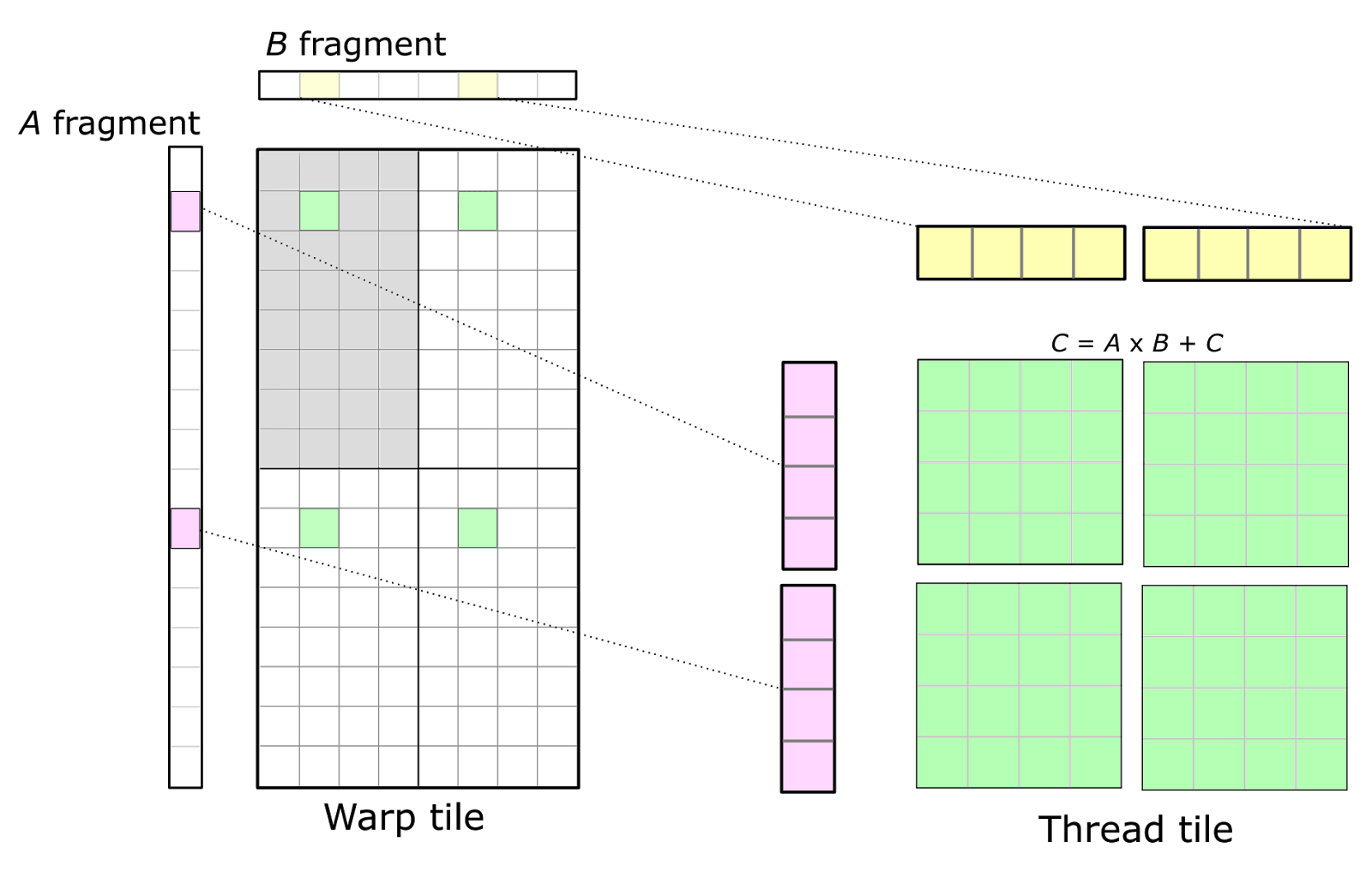
单个线程(右)通过对寄存器中保存的 A 的片段(fragment)与 B 的片段(fragment)做外积,来参与 warp 级的矩阵乘法(左)。用绿色标示的 warp 累加器被分配给该 warp 内的各个线程,通常组织成一组二维小 tile。
在上图中,warp 的左上象限以灰色标示。那 32 个小格分别对应一个 warp 内的 32 条线程。这种安排会使同一行中的多条线程各自去取 A 片段中的相同元素,而同一列中的多条线程各自去取 B 片段中的相同元素。
为最大化计算强度,可以复制这一基础结构来构成完整的 warp 级累加器 tile,从而得到一个由 8×1 与 1×8 片段做外积得到的 8×8 的整体“线程 tile”。这在图中用绿色显示的四个累加器 tile予以说明。
5. Multi-Stage 与占用率(Occupancy)
分块(tiled)的矩阵乘法会大量使用寄存器文件来存放 A/B 的片段与 C 的累加子块,同时也需要分配较大的共享内存。对片上存储的相对高需求会限制占用率(occupancy),也就是单个 SM 上能并发运行的线程块数量上限。因此,GEMM 的实现通常在每个 SM 中能容纳的 warp 与线程块数量远少于典型的 GPU 计算工作负载。
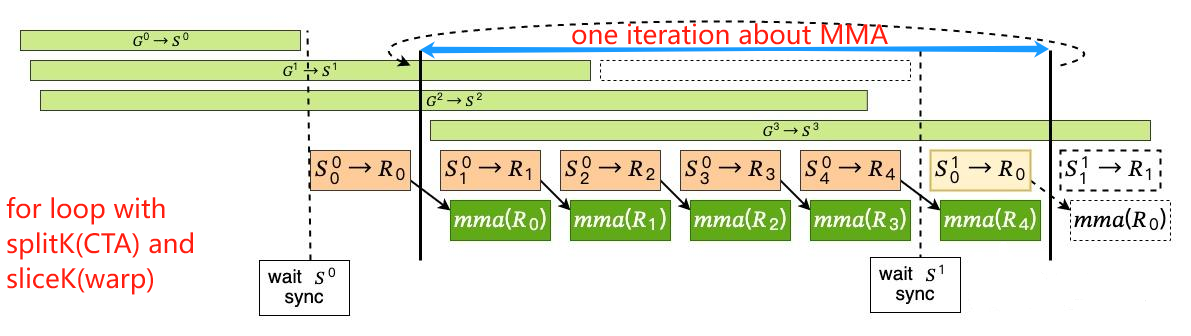
在 CUTLASS 的 GEMM 主循环中交错执行的三条并发指令流。黑色箭头表示数据依赖关系(
Math依赖S -> R)。当内存系统在从全局内存加载数据、且 SM 正在为下一轮线程 tile 加载片段时,线程通过为当前 tile 执行算术指令来让 SM 持续忙碌。
GEMM为了把C子块常驻寄存器、A/B子块常驻共享内存,会吃掉大量片上资源导致占用率下降,用多开更多线程块来掩蔽延迟的常规手段不再有效。于是改为在同一线程块内重叠多个阶段:边算当前K-tile,边预取下一个K-tile,尽量让计算单元与带宽都忙起来。
在实践中,CUDA 程序员通过在源码中交错编写各阶段的 CUDA 语句,来实现这些管线阶段之间的指令级并发,并依赖 CUDA 编译器在生成的机器码里安排合适的指令调度。广泛使用 #pragma unroll 与编译期常量可以让编译器完全展开循环并把数组元素映射到寄存器,这两点对实现可调优且高效的内核至关重要。
可隐藏的实际时延量,取决于 线程块 / warp / 线程 三级tile的大小,以及SM内活动数学功能单元(FMA/WMMA 等)的吞吐。更大的tile通常带来更多数据复用与时延隐藏机会。
6. 软流水(Software Pipelining)与双缓存
在Ampere架构中,在GEMM kernel的最内层循环中,执行SMEM =>REG的搬运指令,以及FMA指令。可以通过类似Multi-Stage的方式,先后issue两条指令,达到掩盖(overlap)部分数据搬运指令的延时。
6.1. 软流水(Software Pipelining)的原理
指令能否并行执行,取决于一些因素,比如:能否分配到硬件资源、执行单元是否可用、数据是否存在依赖(REG/SMEM)等等。如果指令没有资源可用,则不会被issue(另外,资源分配以及issue,都是以warp为单位的)。
SMEM => REG指令由LSU(Load/Store Unit)处理。当一个warp需要执行SMEM => REG时,如果SM可以分配出32个LSU资源,并且REG/SMEM也是可用的,则此时可以立即执行,否则就需要等待、或者查找其他可用的warp并执行可以执行的指令。
执行单元LSU与Tensor Core/CUDA Core相互独立,他们之间存在的依赖就是REG/SMEM的读写依赖。使用double buffer,每次预取k+1位置的tile,并且计算第k位置的tile,可以实现软流水,从而掩盖部分SMEM => REG数据搬运的延时。

有关硬件资源的调度,见另外一篇博客”NVIDIA GPU 架构:SP、SM 与 LSU 工作原理详解”。
6.2. 软流水的代码示例
使用数据预取,解除了共享内存访问(R/W)的依赖,可以节省一次 __syncthreads()。原始的 GEMM 主循环如下:
for k:
copy(GMEM[k] → SMEM) ← 写 SMEM
__syncthreads() ← 1 等待所有线程写完 SMEM,才能安全读(read after write)
gemm(SMEM, REG) ← 读 SMEM
__syncthreads() ← 2 等待所有线程读完 SMEM,才能下一轮覆写(write after read)
使用双缓冲后,子循环如下:
prologue: copy(GMEM[0] → smem[0])
__syncthreads()
for k:
copy(GMEM[k+1] → smem[(k+1)%2]) ← 写 smem[1-cur]
gemm(smem[k%2], REG) ← 读 smem[cur]
__syncthreads() ← 1 只剩1次
资料
- Hierarchical GEMM Structure
- Efficient GEMM in CUDA
- CUTLASS Tutorial: Efficient GEMM kernel designs with Pipelining:参考章节:Appendix: Pipelining for an Ampere GEMM
- 长文介绍矩阵乘法——从自己手搓到CUTLASS实现:待阅读,动图介绍GEMM的分层结构和数据流。
Enjoy Reading This Article?
Here are some more articles you might like to read next: