CUTLASS-Cute 初步(6):CUDA GEMM 计算优化、Multi-Stage 与软流水(Software Pipelining)
整个GEMM可用如下公式表示:
\[C[i, j] = \sum_{k=0}^{nK-1} A[i, k] \times B[k, j]\]| 层级 | 说明 |
|---|---|
| Thread Block | Tile 每个 CUDA 线程块(thread block)负责计算输出矩阵 C 的一个子块(tile) |
| Warp Tile | 在线程块内部,每个 warp(32个线程)负责计算 thread block tile 的一个子区域 |
| Thread Tile | 在 warp 内部,每个线程负责计算 warp tile 的一个更小的子区域 |
1. GEMM 计算步骤–分层 GEMM 结构
依照硬件架构层次划分(也即 CUDA 编程模型),GEMM 计算可以分为多个层次:Thread Block Tile -> Warp Tile -> Thread Tile。即将一个大矩阵的算术运算,依次分解,直到最小的线程级别,一个线程计算一小部分的 tile。
数据搬运过程分为几步:GMEM -> Shared Memory -> Register File -> CUDA Core。如下图所示:
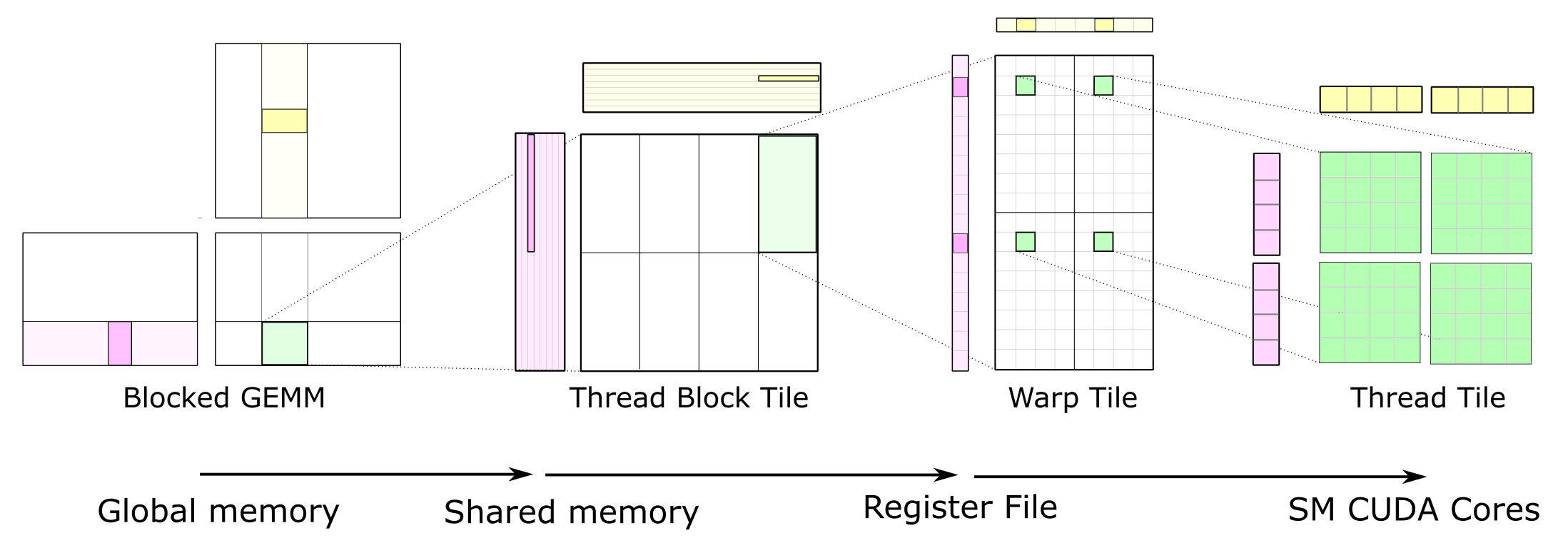
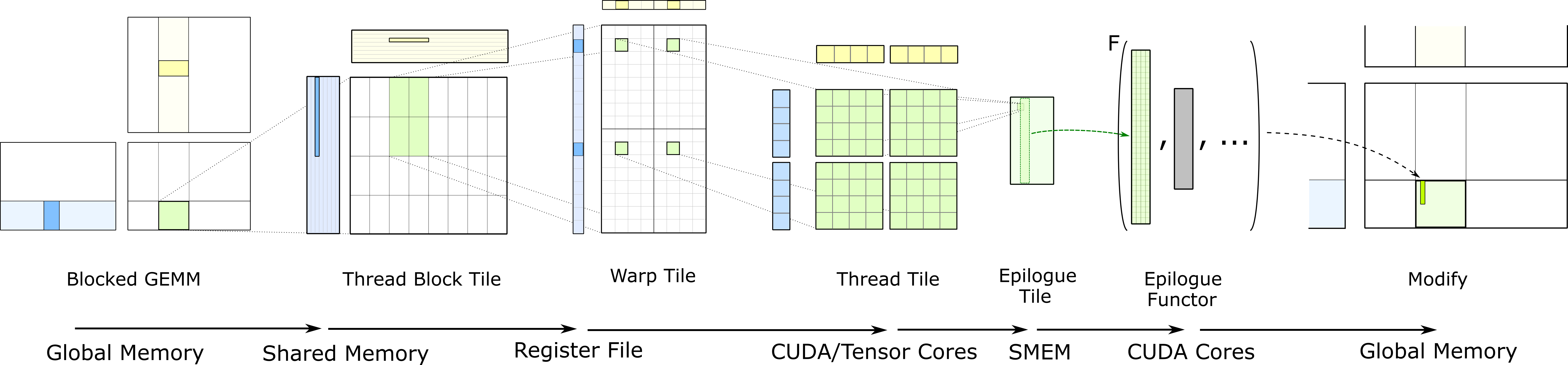
完整的 GEMM 分层结构把数据从较慢的存储器搬运到较快的存储器,并在许多算术运算中对其进行重复利用,以提高计算强度。
2. Thread Block Tile
每个 Thread Block 负责计算输出矩阵 C 的一个 Tile(即几个分块)。对于几个矩阵计算C += A * B,每个 Thread Block 需要反复从输入矩阵中加载一个个的 Tile 并计算一个累加的矩阵乘积。如下图所示:
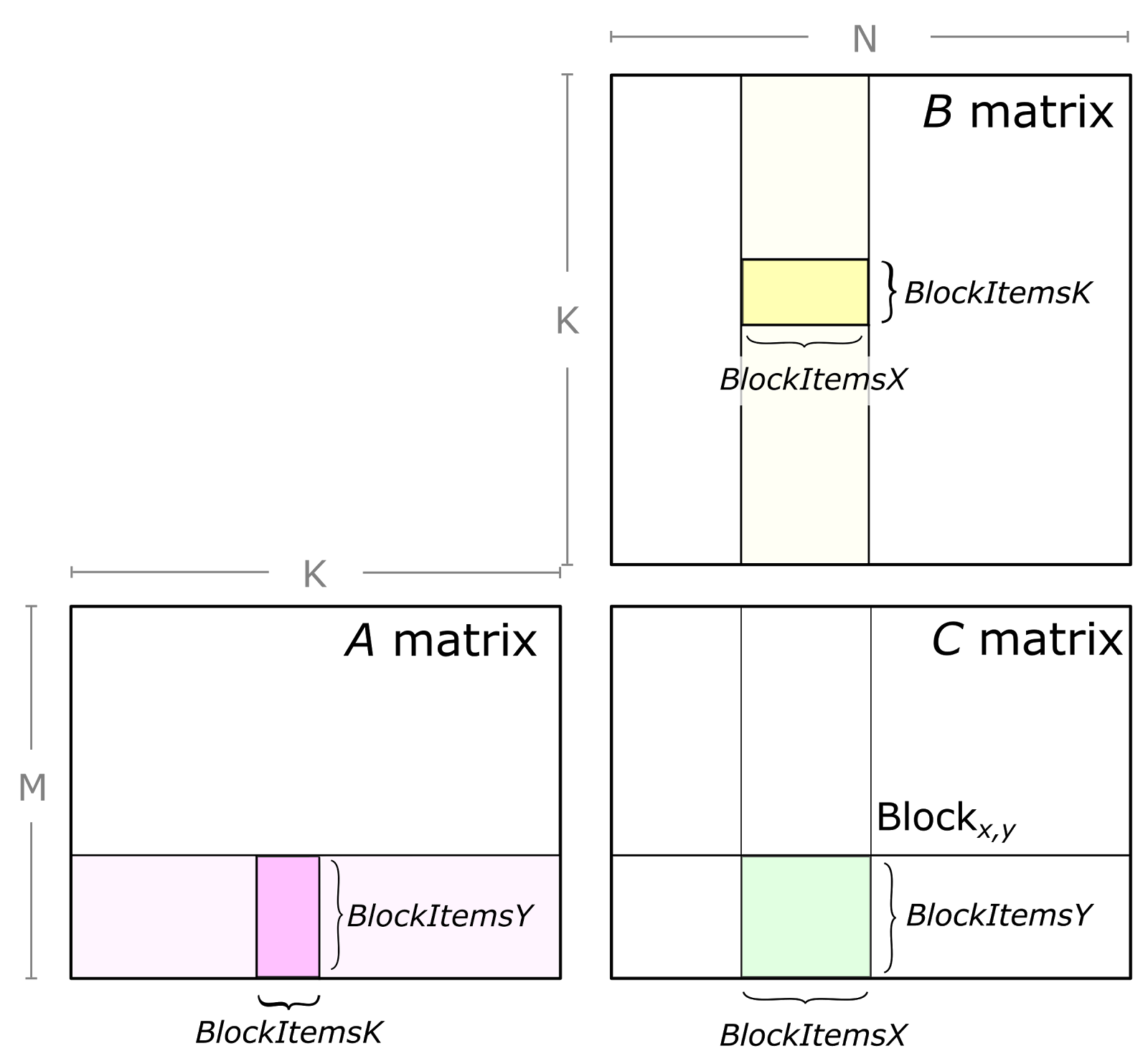
把一个 GEMM 问题分解为由单个线程块执行的计算。绿色所示的 C 的子矩阵,是由 A 的一个 tile 与 B 的一个子矩阵做矩阵乘积得到的。为此,沿 K 维(已被切分成多个 tile)循环,并把每个 tile 的矩阵乘积结果累加起来完成计算。
在逻辑上,Thread Block Tile 又被分为若干个 Warp Tile,每个 Warp Tile 由一个 Warp 负责计算。
线程块的输出 tile按空间被划分给各个 warp(如下图所示)。我们把用于存放这个输出 tile 的存储称为累加器(accumulators),因为它保存的是累加起来的矩阵乘积结果。每进行一次算术运算就会更新一次累加器,因此它必须驻留在 SM 中最快的存储器里:寄存器文件。
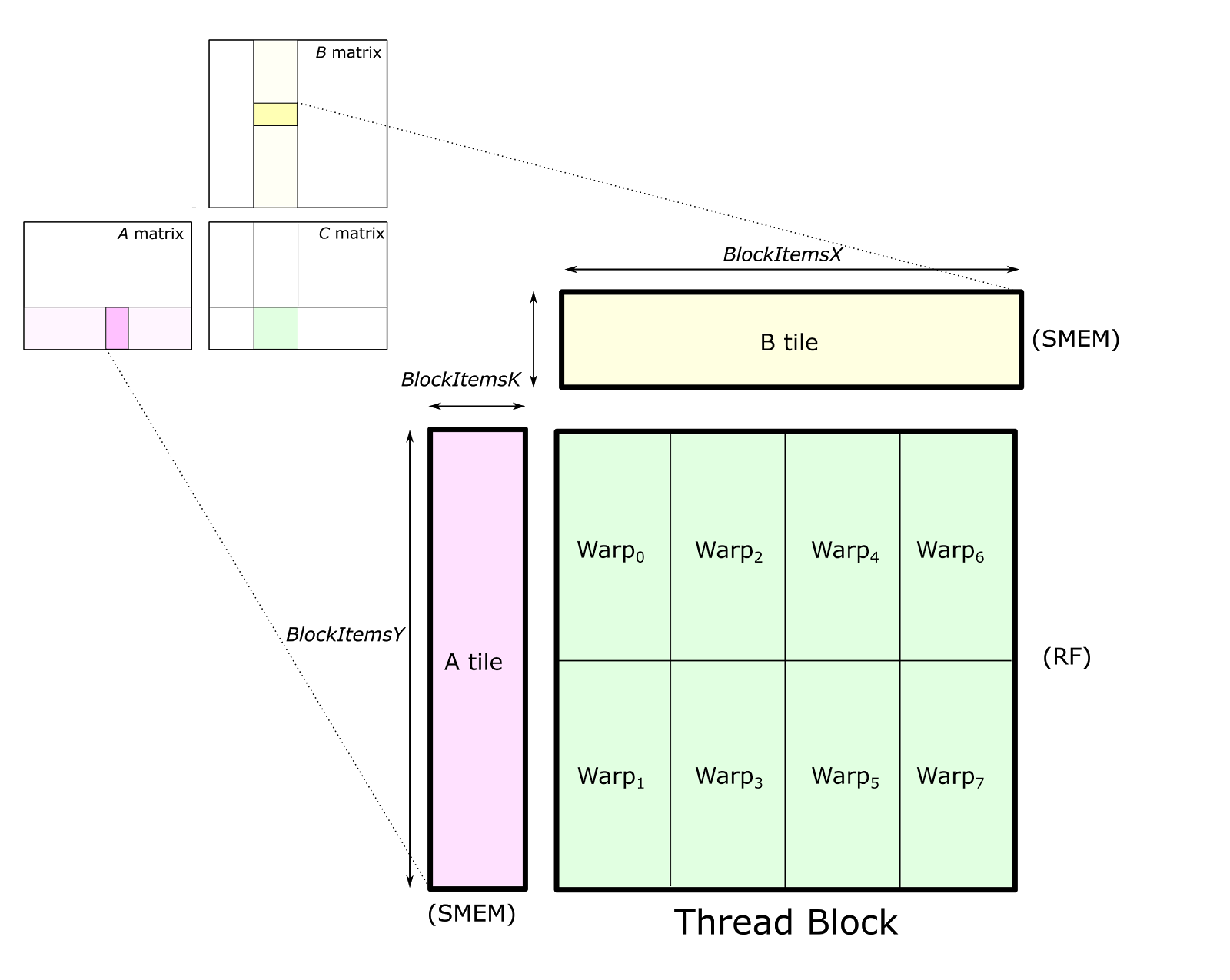
线程块的结构把 C 的一个 tile 划分给多个 warp,每个 warp 负责存储一个互不重叠的二维子块。每个 warp 都将其累加器元素存放在寄存器中。矩阵 A 和 B 的 tile 则存放在共享内存中,线程块内所有 warp 都可访问。
3. Warp Tile
当数据已存入共享内存后,每个 warp 通过在其线程块 tile 的 K 维上迭代、从共享内存中加载子矩阵(或称 fragment),并计算累加的外积。如下图所示:
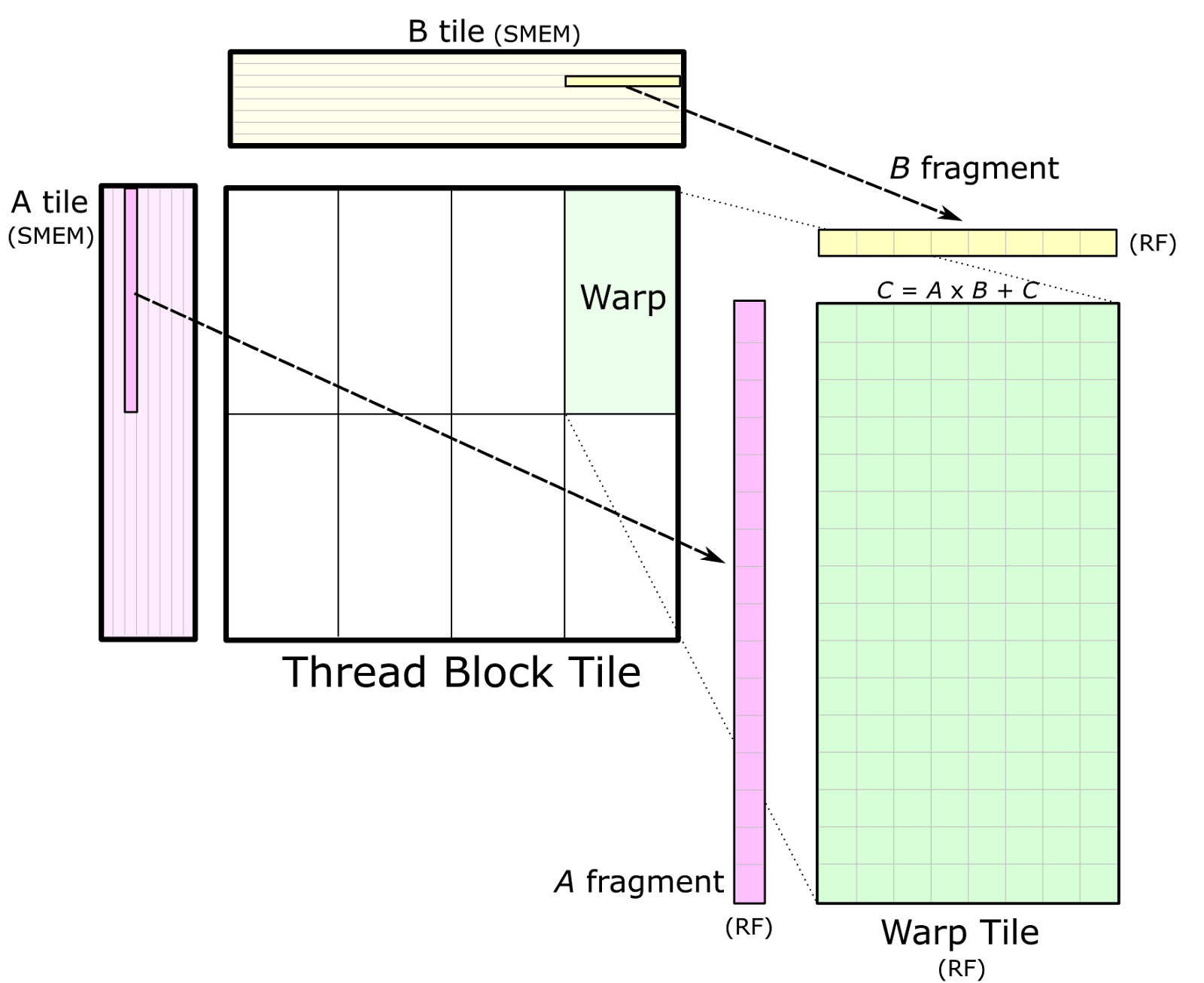
单个 warp 通过在循环中把 A 和 B 的片段(fragments)从各自对应的共享内存(SMEM)tile 加载到寄存器(RF),并计算外积,从而形成累加的矩阵乘积。
上图也展示了多个 warp 之间如何从共享内存进行数据共享:同一线程块行(row)中的 warp 会加载相同的 A 片段;同一线程块列(column)中的 warp 会加载相同的 B 片段。
4. Thread Tile
CUDA 编程模型是以线程块和单个线程来定义的。因此,warp 的结构需要映射到各个线程实际执行的操作上。由于线程之间不能互相访问寄存器,我们必须选取一种组织方式,使得保存在寄存器中的值能够被同一线程执行的多条算术指令反复复用。由此,在单个线程内部形成了一个二维分块(2D tiled)的结构,如下图的细节所示。每个线程向 CUDA 核心发出一串彼此独立的算术指令,并计算一个累加的外积。
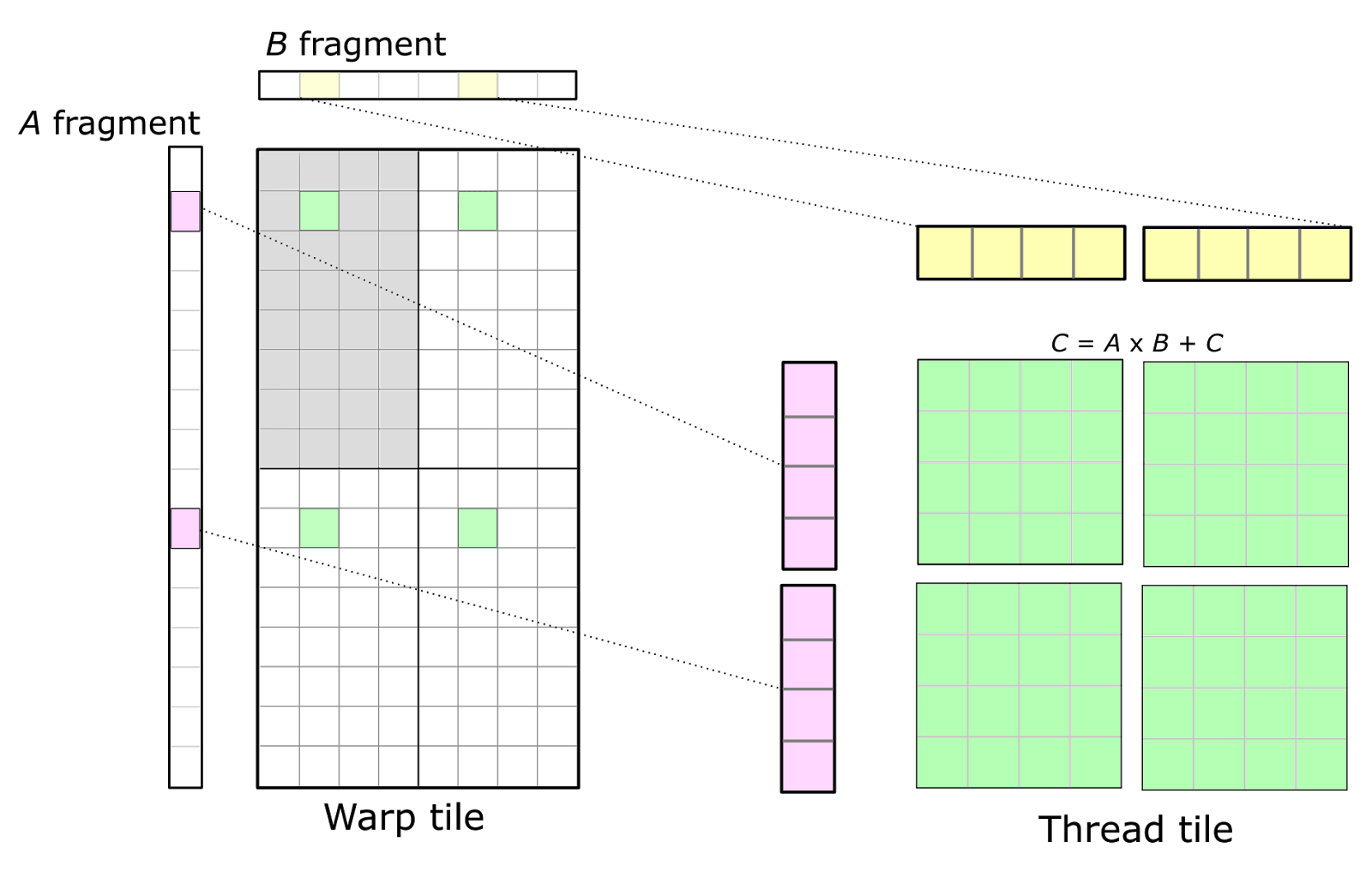
单个线程(右)通过对寄存器中保存的 A 的片段(fragment)与 B 的片段(fragment)做外积,来参与 warp 级的矩阵乘法(左)。用绿色标示的 warp 累加器被分配给该 warp 内的各个线程,通常组织成一组二维小 tile。
在上图中,warp 的左上象限以灰色标示。那 32 个小格分别对应一个 warp 内的 32 条线程。这种安排会使同一行中的多条线程各自去取 A 片段中的相同元素,而同一列中的多条线程各自去取 B 片段中的相同元素。
为最大化计算强度,可以复制这一基础结构来构成完整的 warp 级累加器 tile,从而得到一个由 8×1 与 1×8 片段做外积得到的 8×8 的整体“线程 tile”。这在图中用绿色显示的四个累加器 tile予以说明。
5. Multi-Stage 与占用率(Occupancy)
Tiled GEMM会大量使用RF来存放A fragment/B fragment以及C accumulator,同时也需要分配较大的SMEM。对片上存储的相对高需求会限制占用率(occupancy),也就是单个SM上能并发运行的线程块数量上限。因此,GEMM的实现通常在每个SM中能容纳的warp与线程块数量远少于典型的GPU计算工作负载。
GEMM为了把C子块常驻寄存器、A/B子块常驻共享内存,会吃掉大量片上资源导致占用率下降,用多开更多线程块来掩盖延迟(overlap,latency hiding)的常规手段不再有效。于是改为在同一线程块内重叠多个阶段:边算当前K-tile,边预取下一个K-tile,尽量让计算单元与带宽都忙起来。
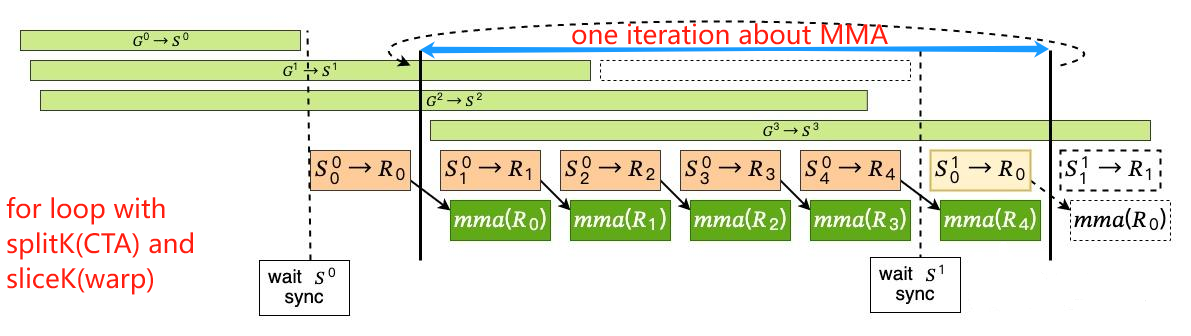
在 CUTLASS 的 GEMM 主循环中交错执行的三条并发指令流。黑色箭头表示数据依赖关系(
Math依赖S -> R)。当内存系统在从全局内存加载数据、且 SM 正在为下一轮线程 tile 加载片段时,线程通过为当前 tile 执行算术指令来让 SM 持续忙碌。
在实践中,CUDA程序员通过在源码中交错编写各阶段的CUDA语句,来实现这些管线阶段之间的指令级并发,并依赖 CUDA 编译器在生成的机器码里安排合适的指令调度。广泛使用#pragma unroll与编译期常量可以让编译器完全展开循环并把数组元素映射到寄存器,这两点对实现可调优且高效的内核至关重要。
可隐藏的实际时延量,取决于 线程块 / warp / 线程 三级tile的大小,以及SM内活动数学功能单元(FMA/WMMA 等)的吞吐。更大的tile通常带来更多数据复用与时延隐藏机会。
5.1. Ampere 架构下的 Multi-Stage
在Hopper架构中(sm90),可以基于warp-specialization对寄存器进行warp-specific分配,在此基础上在warp之间创建生产-消费模型(流水线),即Multi-Stage。
在Ampere中,没有Hopper上的这些高级特性,只能将生产-消费结构的编码逻辑在同一线程之内实现,并使用cp.async实现latency-hiding。
另外,由于使用软流水,导致A/B需要在原有基础上进一步分块,进而需要增加一级循环,共需要两层循环:一层用于loop-over BK,另外一层用于循环(CPY, CPY_M, CPY_K)中的CPY_K。
5.2. Ampere 架构 Multi-Stage 编程中 A/B 的分块
作为对比,使用单一TiledCopy进行分块搬运前,将tensor A分块为(BM, BK),并使用ThrCopy获取其(CPY, CPY_M, CPY_K, k),并使用loop-over BK沿着K方向逐次搬运并计算。流程代码如下:
Tensor sA = make_tensor(make_smem_ptr(smemA), make_shape(Int<BM>{}, Int<BK>{}), make_stride(Int<1>{}, Int<BM>{}));
Tensor sB = make_tensor(make_smem_ptr(smemB), make_shape(Int<BN>{}, Int<BK>{}), make_stride(Int<1>{}, Int<BN>{}));
auto thr_copy_A = tiled_copy_A.get_thread_slice(tid);
Tensor tAgA = thr_copy_A.partition_S(gA); // 源:全局内存 (CPY, CPY_M, CPY_K, k)
Tensor tAsA = thr_copy_A.partition_D(sA); // 目标:共享内存 (CPY, CPY_M, CPY_K)
auto thr_copy_B = tiled_copy_B.get_thread_slice(tid);
Tensor tBgB = thr_copy_B.partition_S(gB); // 源:全局内存
Tensor tBsB = thr_copy_B.partition_D(sB); // 目标:共享内存
const int num_tile_k = K / BK;
for (int k = 0; k < num_tile_k; k++) {
copy(tiled_copy_A, tAgA(_, _, _, k), tAsA);
copy(tiled_copy_B, tBgB(_, _, _, k), tBsB);
}
在Multi-Stage架构+软流水架构下,由于需要分离数据搬运与数据计算,导致在使用Multi-Stage进行GMEM => SMEM搬运过程,以及SMEM => REG搬运过程中,有两点不同。
首先,在GMEM => SMEM搬运过程中,需要为SMEM创建nStage个缓存,即缓存是以前的nStage倍。代码如下:
// 配置代码
constexpr auto smem_shape_A = cute::make_shape(bM, bK, bP); // (bM, bK, bP)
constexpr auto smem_shape_B = cute::make_shape(bN, bK, bP); // (bN, bK, bP)
constexpr auto smem_layout_A = cute::tile_to_shape(smem_atom_layout_A_swizzled, smem_shape_A);
constexpr auto smem_layout_B = cute::tile_to_shape(smem_atom_layout_B_swizzled, smem_shape_B);
// kernel
// partition gmem -> smem via gmem tiled copy
auto gmem_thr_tiled_copy_A{gmem_tiled_copy_A.get_slice(threadIdx.x)};
auto gmem_tAgA = gmem_thr_tiled_copy_A.partition_S(gmem_block_tensor_A); // (CPY, CPY_M, CPY_K, k)
auto gmem_tAsA = gmem_thr_tiled_copy_A.partition_D(smem_tensor_A); // (CPY, CPY_M, CPY_K, bP)
auto gmem_thr_tiled_copy_B{gmem_tiled_copy_B.get_slice(threadIdx.x)};
auto gmem_tAgB = gmem_thr_tiled_copy_B.partition_S(gmem_block_tensor_B); // (CPY, CPY_N, CPY_K, k)
auto gmem_tAsB = gmem_thr_tiled_copy_B.partition_D(smem_tensor_B); // (CPY, CPY_N, CPY_K, bP)
可以看到,最终线程的gmem fragment跟以前一样,但是smem fragment layout多出一个轴bP。
其次,在使用软流水优化SMEM => REG搬运的过程中,以A为例,每次搬运的数据由(CPY, CPY_M, CPY_K)改为(CPY, CPY_M),同样出于分离数据搬运/数据计算的需要;同时,计算量也由(MMA, MMA_M, MMA_K)改为(MMA, MMA_M),即取原来的一个k'-slice。
5.3. Ampere 架构实现 Multi-Stage 的流程
在启动Multi-Stage的主循环之前,需要先对GMEM => SMEM进行预取操作一次。代码实现如下:
// prologue: 预填充 SMEM [0, PIPELINE-2], 共(PIPELINE-1)个 tile 到 smem。
// 保证主循环有 pipeline slot 进行预加载,并保证 pipeline slot 不溢出,
// 另外还需要 wait 能保证最新发出的 copy 仍在飞
for (auto pipeline_idx = 0; pipeline_idx < (NUM_SMEM_PIPELINE - 1); ++pipeline_idx) {
cute::copy(gmem_tiled_copy_A,
gmem_tAgA(cute::_, cute::_, cute::_, tile_idx_next), //
gmem_tAsA(cute::_, cute::_, cute::_, pipeline_idx));
cute::copy(gmem_tiled_copy_B,
gmem_tAgB(cute::_, cute::_, cute::_, tile_idx_next), //
gmem_tAsB(cute::_, cute::_, cute::_, pipeline_idx));
cute::cp_async_fence();
--num_tiles_remain;
if (num_tiles_remain > 0) { ++tile_idx_next; }
}
cute::cp_async_wait<NUM_SMEM_PIPELINE - 2>();
__syncthreads();
// prefetch first k' slice from SMEM => REG
// ......
prologue 总结:
cp_async_fence()表示创建一个commit groups,这里一个commit groups包含一次A fragment的GMEM=>SMEM操作,以及一次B fragment的GMEM=>SMEM操作。cp_async_wait<N>()表示等待直到有N个commit groups在飞(in flight)。语句cute::cp_async_wait<NUM_SMEM_PIPELINE - 2>()表示等待最先一批A fragment/B fragment完成。- 首次预取循环代码中
pipeline_idx < (NUM_SMEM_PIPELINE - 1)之所以循环次数取为NUM_SMEM_PIPELINE - 1,是因为如果预取所有的SMEM buffer,将导致主循环中再也写不了预取代码,即代码的逻辑结构需要。另外,如果取为NUM_SMEM_PIPELINE - 2,将导致cp_async_wait变为cute::cp_async_wait<NUM_SMEM_PIPELINE - 3>(),即当NUM_SMEM_PIPELINE为3的时候,需要等待所有拷贝操作完成,即Multi-Stage失效,无法并行数据搬运与数据计算。NUM_SMEM_PIPELINE最小为3。
在prologue预取GMEM => SMEM之后且预取SMEM => REG之前,可以进行一些其他初始化工作,比如创建TiledMMA、初始化C fragment累加器,应该可以略微压缩一些时间。
如下为Multi-Stage主循环的总结。
在初次进入主循环的时候,loop-over BK的第一个分块已经在SMEM中就绪,剩余的NUM_SMEM_PIPELINE-2批数据在飞。要模拟实现数据搬运与数据计算的分离,就要保证每个循环中,发起的数据搬运领先数据计算一个位置,loop-over BK与k'循环都需要按照这个时序。在主循环中,需要继续安排这几个逻辑:
- 在内层
k'循环的开始位置(k'==0),issue一次GMEM=>SMEM异步搬运,即保持流水逻辑(生产端); - 在内层
k'循环的结束位置(k'==NUM_MMA_K_LOOP-1),等待k+1位置的fragment准备好,即到第k+1个循环的时候需要的计算数据。
由于是异步搬运,所以需要两个指针分别标示:
-
GMEM=>SMEM操作时smem(k+1 fragment)的位置:smem_pipeline_g2s_idx(对应生产端数据); -
SMEM=>REG操作时smem(k fragment)的位置:smem_pipeline_s2r_idx(对应消费端数据); - 生产端
fragment的位置始终领先消费端fragment一个位置。
另外,在prologue之后,生产端的位置已经到了NUM_SMEM_PIPELINE-1,即在主循环中,从该位置开始issue下一个fragment。
int smem_pipeline_s2r_idx = 0; // 指示当前 SMEM -> REG pipeline index
int smem_pipeline_g2s_idx = (NUM_SMEM_PIPELINE - 1); // 指示当前 GMEM -> SMEM pipeline index
主循环代码如下:
while (num_tiles_remain > -(NUM_SMEM_PIPELINE - 1)) { // loop-over K
for (int mma_idx_k = 0; mma_idx_k < NUM_MMA_K_LOOP; ++mma_idx_k) { // loop-over BK within the tile
// 计算下一个 tile 之前,wait 等待确保下一个 tile 已经 GMEM -> SMEM 完成
// 且 current_pipeline 指向下一个 tile 的数据
if (mma_idx_k == (NUM_MMA_K_LOOP - 1)) {
smem_tCsA_current_pipeline = smem_tCsA(cute::_, cute::_, cute::_, smem_pipeline_s2r_idx); // (CPY, CPY_M, CPY_K)
smem_tCsB_current_pipeline = smem_tCsB(cute::_, cute::_, cute::_, smem_pipeline_s2r_idx); // (CPY, CPY_N, CPY_K)
// 等待 SMEM -> REG 的 prefetch 完成,保证最新的 SMEM slot 在飞
cute::cp_async_wait<NUM_SMEM_PIPELINE - 2>();
__syncthreads();
}
// 加载下一个 MMA_K 的数据到 REG
// ......
// perform prefetch next tile GMEM -> SMEM before this tile's MMA
if (mma_idx_k == 0) {
cute::copy(gmem_tiled_copy_A,
gmem_tAgA(cute::_, cute::_, cute::_, tile_idx_next), // (CPY, CPY_M, CPY_K)
gmem_tAsA(cute::_, cute::_, cute::_, smem_pipeline_g2s_idx));
cute::copy(gmem_tiled_copy_B,
gmem_tAgB(cute::_, cute::_, cute::_, tile_idx_next), // (CPY, CPY_N, CPY_K)
gmem_tAsB(cute::_, cute::_, cute::_, smem_pipeline_g2s_idx));
cute::cp_async_fence();
num_tiles_remain--;
if (num_tiles_remain > 0) { ++tile_idx_next; }
smem_pipeline_g2s_idx = smem_pipeline_s2r_idx;
smem_pipeline_s2r_idx = (smem_pipeline_s2r_idx + 1) % NUM_SMEM_PIPELINE;
}
// perform MMA on the current MMA_K
// ......
}
}
5.3.1. 一些实现细节分析
TODO:最后阶段存在一些dummy copy。
6. 软流水(Software Pipelining)
在Ampere架构中,在GEMM kernel的最内层循环中,执行SMEM =>REG的搬运指令,以及FMA指令。可以通过类似Multi-Stage的方式,先后issue两条指令,达到掩盖(overlap)部分数据搬运指令的延时。
6.1. 软流水(Software Pipelining)的原理
指令能否并行执行,取决于一些因素,比如:能否分配到硬件资源、执行单元是否可用、数据是否存在依赖(REG/SMEM)等等。如果指令没有资源可用,则不会被issue(另外,资源分配以及issue,都是以warp为单位的)。
SMEM => REG指令由LSU(Load/Store Unit)处理。当一个warp需要执行SMEM => REG时,如果SM可以分配出32个LSU资源,并且REG/SMEM也是可用的,则此时可以立即执行,否则就需要等待、或者查找其他可用的warp并执行可以执行的指令。
执行单元LSU与Tensor Core/CUDA Core相互独立,他们之间存在的依赖就是REG/SMEM的读写依赖。使用double buffer,每次预取k+1位置的tile,并且计算第k位置的tile,可以实现软流水,从而掩盖部分SMEM => REG数据搬运的延时。

有关硬件资源的调度,见另外一篇博客”NVIDIA GPU 架构:SP、SM 与 LSU 工作原理详解”。
6.2. 软流水的代码示例
SMEM => REG使用数据预取,解除了共享内存访问(R/W)的依赖,可以节省一次 __syncthreads()。原始的GEMM主循环示意代码如下:
for k:
copy(GMEM[k] → SMEM) ← 写 SMEM
__syncthreads() ← 1 等待所有线程写完 SMEM,才能安全读(read after write)
gemm(SMEM, REG) ← 读 SMEM
__syncthreads() ← 2 等待所有线程读完 SMEM,才能下一轮覆写(write after read)
使用双缓冲后,循环示意代码如下:
prologue: copy(GMEM[0] → smem[0])
__syncthreads()
for k:
copy(GMEM[k+1] → smem[(k+1)%2]) ← 写 smem[1-cur]
gemm(smem[k%2], REG) ← 读 smem[cur]
__syncthreads() ← 1 只剩1次
7. Multi-Stage 中 buffer 深度的计算
RTX 3060算力如下:
- GMEM 带宽:360 GB/s
- Tensor Core 峰值性能(FP16):12.74 TFLOPS
记CTA处理的分块的大小为$BM \times BN \times BK$,峰值带宽为$P_m$,算力为$P_c$:
- 每个分块的计算量为:$2 \times BM \times BK \times BN$,需要的时间为:$T_c = \frac{2 \times BM \times BK \times BN}{P_c}$。
- 每次分块需要搬运的数据量为$2 \times (BM \times BK + BK \times BN)$,需要的时间为:$T_m = \frac{2 \times (BM \times BK + BK \times BN)}{P_m}$。
得到访存比为:
\[\text{ratio} = \frac{T_c}{T_m} = \frac{BM \times BN \times BK / P_c}{(BM \times BK + BK \times BN) / P_m} = \frac{BM \times BN \times BK}{BM \times BK + BK \times BN} \times \frac{P_m}{P_c} = \frac{BM \times BN}{BM + BN} \times \frac{P_m}{P_c}\]峰值算力/峰值带宽为:
\[\frac{P_c}{P_m} = \frac{12.74 \text{ TFLOPS}}{360 \text{ GB/s}} \approx 35.4 \text{ FLOP/byte}\]以$BM=BN=128$为例,得到:
\[\text{ratio} = \frac{128 \times 128}{128 + 128} \times \frac{1}{35.4} \approx 18.3 \text{ FLOP/byte}\]这个计算得到的访存比,其含义是访存的时间,是计算时间的18.3倍。因此,理想情况下,
Multi-Stage的buffer深度应该大于18.3,才能完全掩盖访存的延时。
7.1. Multi-Stage 为什么可以提高性能

以理论的计算/访存比=3为例,没有pipeline的时候,有2/3的空隙未被填满,即算力只有理论值的1/3;当开辟两个pipeline的时候,还有1/3的空隙未被填满;当开辟三个pipeline的时候,可以使得计算填满空隙,消除data harzard导致的stall,达到理论峰值算力。
从图示看,增加pipeline似乎是提高了内存带宽。实际情况是,由于L2的存在,使得有些SM可以从L2中直接获取数据,即不用每个SMEM每次都从GMEM中获取数据,消除了GMEM的访问时间。
A. 资料
- Hierarchical GEMM Structure
- Efficient GEMM in CUDA
- CUTLASS Tutorial: Efficient GEMM kernel designs with Pipelining:参考章节:Appendix: Pipelining for an Ampere GEMM
- 长文介绍矩阵乘法——从自己手搓到CUTLASS实现:待阅读,动图介绍GEMM的分层结构和数据流。
- 浅析GEMM优化multistage数怎么算:郑思泽(北京大学 计算机系统结构博士)的知乎文章
A.1. 工具
- Revezone APP:画板工具
Enjoy Reading This Article?
Here are some more articles you might like to read next: