CUDA入门:Bank Conflict
使用到的测试代码:bank_conflict.cu
1. Bank Conflicts (Shared Memory)
1.1. Bank 划分
针对Shared Memory的访问,CUDA使用bank机制,将shared memory的访问(读/写)映射到不同的bank,以实现并行访问。bank以4字节为单位,共32个bank。这样,一个时钟周期内,可以并行访问32个不同的bank,即访问128字节的数据。映射公式bank index = (address /4) % 32。
每次发起共享内存事务(transation)时,可以从这 32 个 bank 中分别读取一个 32 位数据。以 32 位的字为单位索引,则 bank 以地址的低 5 位进行划分,与高位没有关系。
图示transaction:
1
2
3
4
5
6
7
Thread(在CUDA Core中)
↓
访问Shared Memory
↓
[Bank系统处理] ← Transaction 在这里发生
↓
返回数据到Thread
举例:warp中定义的shared memory如何映射到banks:
1
__shared__ float s[64];
如上变量,其映射如下:

1.2. Bank Conflicts
在一次transaction的时候,如果,当warp中的不同线程访问到同一个bank中的不同地址时,就会产生Bank Conflicts,导致访问串行化:需要分成多次transaction。有N个线程访问同一个bank,称为N-way Bank Conflicts。
所谓
Bank Conflicts,只与transaction有关,即其由Shared Memory访问控制器相关。引用https://forums.developer.nvidia.com/t/how-to-understand-the-bank-conflict-of-shared-mem/260900/2: When you store (or load) more than 4 bytes per thread, which is like saying more than 128 bytes per warp, the GPU does not issue a single transaction. The largest transaction size is 128 bytes. If you request 16 bytes per thread, then warp wide that will be a total of 512 bytes per request (warp-wide). The GPU will break that up into 4 transactions (in that case: T0-T7 make up a transaction, T8-T15 are a transaction, and so on), each of which is 128 bytes wide. The determination of bank conflicts is made per transaction, not per request or per warp or per instruction.
如下情况,会产生Bank Conflicts:
- 一次
transaction中,warp中的多个线程,访问同一个bank中的不同地址; - 一次
transaction中,warp中的多个线程,访问shared memory的下一个128字节,被映射到同一个bank。此时也是属于上一种情况:同一个bank中的不同地址。
如下情况,Bank Conflicts不会产生:
warp中的线程,访问地址唯一对应到bank簇的每个bank,不论是顺序,还是错位;warp中的多个线程,访问同一个bank中的相同地址–使用boardcast分发相同地址数据到多个线程;warp中的线程,单个线程一次访问多个bank,但其他线程不访问这些bank。此时,生成多次transaction。
2. Bank Conflicts 示例
如下示例,产生32路Bank Conflicts:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
const int num_iters = 10000; // 全局常量
__global__ void all_conflicts() {
__shared__ float s[32][32];
[[maybe_unused]] int warp_id = threadIdx.y;
int lane_id = threadIdx.x; // thread 在 warp 中的 id
float *ptr = &s[lane_id][0];
int addr = (int)(uintptr_t)ptr & 0xFFFF;
[[maybe_unused]] float r1; // 声明输出变量
for (int j = 0; j < num_iters; j++) { // num_iters 定义为 100'000
asm volatile("ld.volatile.shared.f32 %0, [%1];" : "=f"(r1) : "r"(addr));
}
}
// launched withall_conflicts<<<1, dim3(32, 8)>>>();
// Gride size: 1(即只有一个Block)
// Block size: dim3(32, 8)(即有8个warp,每个warp 32个线程)

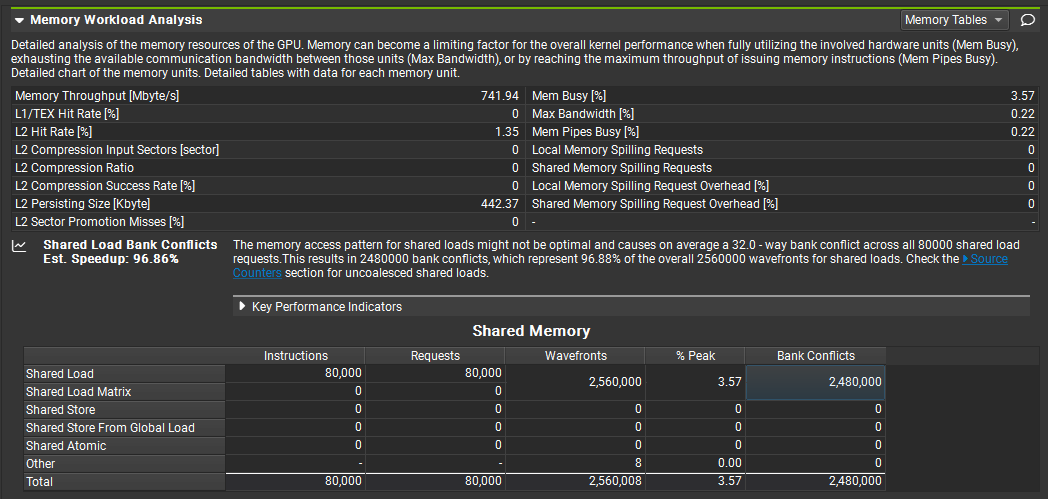
由于是 32-way Bank Conflicts,则每个 warp 产生的 bank conflicts 次数是 10000 * 31,所有 warp 总共是 8 * 10000 * 31 = 2,480,000 次。与 Nsight Compute 测量结果吻合。
2.1. conflict free 代码参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
__global__ void conflict_free_kernel() {
__shared__ float s[8][32];
int warp_id = threadIdx.y;
int lane_id = threadIdx.x;
float *ptr = &s[warp_id][lane_id];
int addr = (int)(uintptr_t)ptr & 0xFFFF;
[[maybe_unused]] float r1; // 声明输出变量
for (int j = 0; j < num_iters; j++) {
asm volatile("ld.volatile.shared.f32 %0, [%1];" : "=f"(r1) : "r"(addr));
}
}
// conflict_free_kernel<<<1, dim3(32, 8)>>>();
// Gride size: 1(即只有一个Block)
// Block size: dim3(32, 8)(即有8个warp,每个warp 32个线程)
3. 矢量读写指令
使用矢量指令ld.shared.v4可以读取4个连续的32位数据。如下代码,一个线程读取s[4*i], s[4*i+1], s[4*i+2], s[4*i+3](分为四个transaction)。会产生四路Bank Conflicts:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
__global__ void vectorized_loads() {
__shared__ float sh[8][128];
int warp_id = threadIdx.y;
int lane_id = threadIdx.x;
float4* ptr = reinterpret_cast<float4*>(&sh[warp_id][lane_id * 4]);
int addr = (int)ptr & 0xFFFF;
float4 r;
for (int j = 0; j < num_iters; j++) {
asm volatile ("ld.volatile.shared.v4.f32 {%0,%1,%2,%3}, [%4];"
: "=f"(r.x), "=f"(r.y), "=f"(r.z), "=f"(r.w)
: "r"(addr));
}
}

上图只给出了一半的线程访问情况。编号(
Lane)为0的线程与编号为8的线程,访问的shared memory中的数据映射到了同一个bank 0;同时,编号为16,以及24,同样映射到了bank 0。 不过,由于其每个线程一次访问4个32位数据,其平均访问时间折算下来,与32位加载相当。
要想避免Bank Conflicts,可以错开(interleave)冲突的线程访问的顺序,比如:
- 线程0:s[0] -> s[1] -> s[2] -> s[3]
- 线程8:s[33] -> s[34] -> s[35] -> s[32]
3. 避免 Bank Conflicts 的方法
3.1. Padding
warp内多个线程访问同一bank会引发冲突,导致串行化访问。 通过在二维共享内存数组的列数上 +1 padding,可打破映射冲突:从第二行开始,Shared Memory中的数据到bank的映射偏移一个bank,且每行累积。示意图:

示例代码:
1
2
3
4
5
6
7
__shared__ float sData[BLOCKSIZE][BLOCKSIZE + 1]; // +1 避免bank冲突
int x = threadIdx.x;
int y = threadIdx.y;
sData[x][y] = matrix[y * col + x];
__syncthreads();
matrixTest[y * col + x] = sData[x][y];
当warp中的线程步长间距为128字节(32个32位数据)时,适用于padding,例如:
| 场景 | 冲突原因 | Padding方案 |
|---|---|---|
| 列访问 | 行步长=32*4 | 列+1 |
| 步长访问 | 步长是32*k | 改变数组维度 |
| 结构体数组 | 字段偏移相同 | 结构体+padding |
| 斜向访问 | 特定步长产生周期 | 适当增加维度 |
3.2. Swizzle
Swizzle是通过重新排列线程访问顺序,来避免Bank Conflicts。假设有32×32的二维数组,原本按列访问产生冲突:
1
2
3
4
// 原始访问(产生冲突)
int x = threadIdx.x;
int y = threadIdx.y;
float val = s[x][y]; // 同列线程映射到同一bank
使用Swizzle变换:
1
2
3
4
5
6
// Swizzle:对线程索引进行XOR操作
int x = threadIdx.x;
int y = threadIdx.y;
int swizzled_x = x ^ (y % 32); // 用XOR改变x坐标
float val = s[swizzled_x][y]; // 现在不同线程映射到不同bank
内存布局对比:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
原始内存:
[0,0] [1,0] [2,0] ... [31,0] <- 映射到bank 0,1,2...31
[0,1] [1,1] [2,1] ... [31,1] <- 映射到bank 0,1,2...31(重复)
...
Swizzle后的访问顺序:
线程[0,0]访问 s[0^0][0] = s[0,0]
线程[1,0]访问 s[1^0][0] = s[1,0]
线程[2,0]访问 s[2^0][0] = s[2,0]
...
线程[0,1]访问 s[0^1][1] = s[1,1] <- 同列不同线程,映射不同bank
线程[1,1]访问 s[1^1][1] = s[0,1]
...
内存物理位置不变,但访问顺序改变了
常见Swizzle操作:
1
2
3
4
5
6
7
8
// 方法1:XOR swizzle(最常用)
int swizzled = x ^ (y & (WARP_SIZE - 1));
// 方法2:位移swizzle
int swizzled = (x + y) % 32;
// 方法3:混合操作
int swizzled = (x + (y >> 4)) % 32;
Swizzle更多资料:
- CUTLASS CuTe GEMM细节分析(三)——Swizzle<B, M, S>模板参数的取值
- issue – how to understand “block swizzling”:Swizzle可以提升L2 cache命中率
- issue – Swizzling the shared memory