CUDA 架构及对应的计算能力CC
1 计算能力 5.x
1.1 体系架构
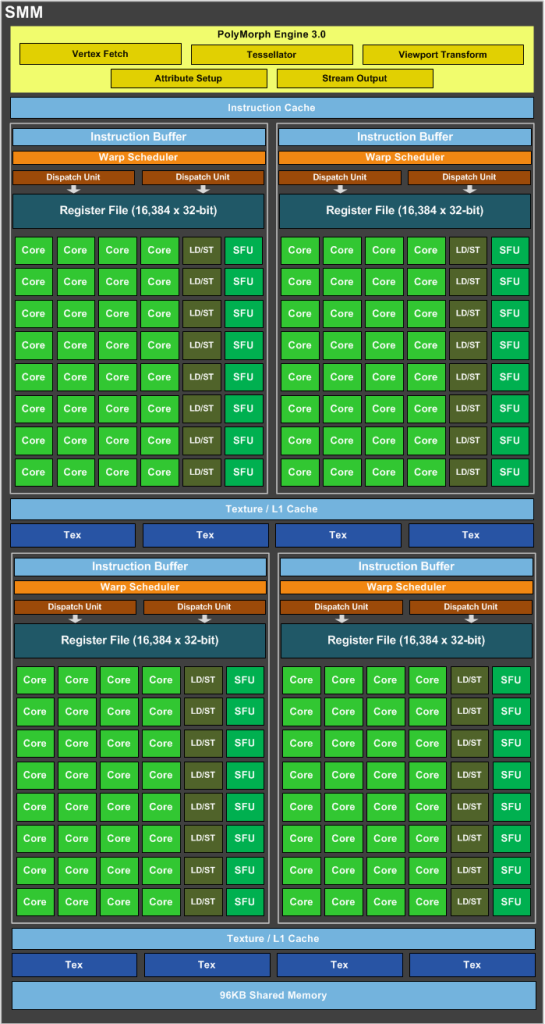
计算能力 5.x 的 GPU 设备使用 Maxwell 架构(2014),下图展示了该架构下的流多处理器(SM)的结构示意图(以 GeForce GTX 980 为例)。
https://developer.nvidia.com/blog/maxwell-most-advanced-cuda-gpu-ever-made/
在 Maxwell 架构下,一个 SM 中包括:
- 128 个用于算术运算的 CUDA Core(相比于 Kepler 架构的 192 个有所缩减,但是峰值利用效率从 66.7\% 提升到了几乎 100\%);
- 32 个用于单精度浮点运算的特殊函数单元;
- 4 个 warp 调度器;
- 由所有功能单元共享的常量内存的缓存,可加快从驻留在设备内存中的常量内存空间的读取速度;
- 24 KB 的纹理/L1 缓存,用于缓存来自全局内存的读取;
- 64 KB(计算能力 5.0)或 96 KB(计算能力 5.2)的共享内存。
还有一个由所有 SM 共享的 L2 缓存(设备级别的,不属于单个 SM),用于缓存对本地或全局内存的访问,包括临时寄存器溢出。应用程序可以通过检查设备属性 l2CacheSize 来查询 L2 缓存大小。
值得注意的是,在 Maxwell 架构中,Texture Cache 和普通全局内存数据的缓存(L1)合并成了 Unified Cache,大小为 24 KB,用户通过 const __restrict__ 修饰指针,或者使用 __ldg() 函数读取全局内存数据,就可以直接利用 Unified Cache,大部分情况下不需要手工写纹理提取的代码,就可以达到纹理内存的加速效果。
1.2 全局内存
Maxwell 架构下,对于全局内存访问的缓存通常在 L2 缓存中,但这也不是绝对的。如果编译器检测到某些数据在 Kernel 的整个执行过程中内是只读的,那么它会自行优化使用 __ldg() 函数来读取这些数据,将全局内存的数据缓存在 Unified Cache 中,当然用户也可以显式使用 __ldg() 函数完成这一行为。除此之外,编译器对数据是否满足只读条件的检测并不是绝对的,用户可以使用 const __restrict__ 修饰指针从而增加编译器检测到只读条件的概率。
对于计算能力 5.0 的设备,如果数据在 Kernel 的整个生命周期内不是只读的,那么该数据不能缓存 Unified Cache 中;而对于计算能力为 5.2 的设备,默认情况下全局内存的数据不会缓存在 Unified Cache 中,但可以使用以下机制启用缓存:
- 使用带有适当修饰符的内联汇编执行读取,参考 PTX 参考手册;
- 使用
-Xptxas -dlcm=ca编译标志进行编译,在这种情况下,所有读取都被缓存,除了使用带有禁用缓存的修饰符的内联汇编执行的读取场景; - 使用
-Xptxas -fscm=ca编译标志进行编译,在这种情况下,所有读取都被缓存,包括使用内联汇编执行的读取,无论使用何种修饰符。
在计算能力 5.2 的设备上使用上面列出的三种机制之一启用缓存时,除非 Kernel 启动的时候 block 内消耗了太多的 SM 寄存器资源,否则将会把所有 Kernel 中全局内存的读取缓存到 Unified Cache 中。
1.3 共享内存
共享内存在物理上被划分为连续的 32 个 bank,这些 bank 宽度相同且能被同时访问,Maxwell 架构中 bank 宽度为 32bit,bank 带宽为每个时钟周期 32bit。
如果来自一个 warp 的多个线程访问到共享内存中相同 32bit 内的某个 byte 时,不会产生 bank conflict,读取操作会在一次广播中完成,如果是写入操作,则每个地址仅会被其中一个线程写入,具体是哪个线程未定义;而如果访问的是同一个 bank 的不同 32bit 的地址,则会产生 bank conflict。我们可以把共享内存的 32 个 bank 想象为由很多层组成,每个 bank 每层有 32bit,假设同一 warp 内的不同线程访问到某个 bank 的同一层的数据,此时不会发生 bank conflict,但如果同一 warp 内的不同线程访问到某个 bank 的不同层的数据,此时将产生 bank conflict。
2 计算能力 6.x
2.1 体系架构
计算能力 6.x 的 GPU 设备使用 Pascal 架构(2016),Pascal 架构和 Maxwell 架构实际上并无的本质区别,可以认为是对 Maxwell 架构的修补版本,而且这代 GPU 的发布正好迎来了 AI 和深度学习的浪潮。下图展示了该架构下的流多处理器(SM)的结构示意图(以 GeForce GTX 1080 为例)。
在 Pascal 架构下,一个 SM 中包括:
- 64(计算能力 6.0)或 128(计算能力 6.1 和 6.2)个用于算术运算的 CUDA Core;
- 16(计算能力 6.0)或 32(计算能力 6.1 和 6.2)个用于单精度浮点运算的特殊函数单元;
- 2(计算能力 6.0)或 4(计算能力 6.1 和 6.2)个 warp 调度器;
- 由所有功能单元共享的常量内存的缓存,可加快从驻留在设备内存中的常量内存空间的读取速度;
- 24 KB(计算能力 6.0 和 6.2)或 48 KB(计算能力 6.1)的纹理/L1 缓存,用于缓存来自全局内存的读取;
- 64 KB(计算能力 6.0 和 6.2)或 96 KB(计算能力 6.1)的共享内存。
还有一个由所有 SM 共享的 L2 缓存(设备级别的,不属于单个 SM),用于缓存对本地或全局内存的访问,包括临时寄存器溢出。应用程序可以通过检查设备属性 l2CacheSize 来查询 L2 缓存大小。
在 Pascal 架构中,纹理缓存和 L1 缓存依然保留了 Maxwell 架构下的组织形式,两者合并成了 Unified Cache,从硬件层面上支持了纹理提取和表面提取的各种寻址模式和数据过滤策略。
2.2 全局内存
Pascal 架构下全局内存的行为方式与 Maxwell 架构相同。
2.3 共享内存
Pascal 架构下共享内存的行为方式与 Maxwell 架构相同。
3 计算能力 7.x
3.1 体系架构
计算能力 7.x 的 GPU 设备可以分成两种不同架构,即计算能力 7.0 的 Volta 架构、计算能力 7.5 的 Turing 架构,这两个架构某种程度上的可以看成同一种架构,相当于 Maxwell 架构中的计算能力 5.0 和 5.2 的关系,而不是看成 Turing(7.5)是 Volta(7.0)的下一代全新架构。只是在 Turing 架构中新引入了支持整数和浮点的并发执行能力以及 Tensor Core 的增强,除此之外并无本质区别。
其中,基于 Volta 架构的 GPU 产品主要是 Tesla 和 Jetson 系列,下图展示了该架构下的流多处理器(SM)的结构示意图(以 Tesla GV100 为例)。而基于 Turing 架构的 GPU 产品主要是 Tesla、Quadro、和 GeForce 系列,其流多处理器(SM)的结构与 Volta 架构基本一致,不再展示 SM 示意图,有兴趣的读者可自行查阅产品白皮书。
在 Volta 和 Turing 架构下,一个 SM 中包括:
- 64 个用于单精度浮点算术运算的 FP32 Core;
- 32 个用于双精度浮点算术运算的 FP64 Core;
- 64 个用于整数算术运算的 INT32 Core;
- 8 个用于深度学习矩阵运算的混合精度 Tensor Core;
- 16 个用于单精度浮点运算的特殊函数单元;
- 4 个 warp 调度器;
- 由所有功能单元共享的常量内存的缓存,可加快从驻留在设备内存中的常量内存空间的读取速度;
- 一个统一的 128 KB(Volta 架构)或 96 KB(Turing 架构)的 纹理/L1 缓存/共享内存。
在 Volta 和 Turing 架构中,L1 缓存、纹理缓存和共享内存三者在物理上被统一成了一个有 128 KB 或 96 KB 的数据缓存,用户可以使用 CUDA Runtime API 来指定其中共享内存所占的容量大小。
3.2 独立线程调度
Volta 架构在 warp 内的线程之间引入了独立线程调度(Independent Thread Scheduling),此功能引入了之前不可用的 warp 内同步模式,并简化了移植 CPU 代码时的代码更改。然而,如果用户对之前架构的 warp 同步模式进行了假设(即隐含地假设同一 warp 中的线程在每个指令上都是同步的代码),那么独立线程调度机制也可能导致 warp 内实际参与执行代码的线程集合与预期的线程集合截然不同。
对于使用到 warp 内置函数(如 __shfl*、__any、__all、__ballot)的应用程序,开发人员有必要将这些函数替换为具有 *_sync 后缀的新函数。新的 warp 内置函数新增了线程掩码参数,明确定义哪些通道(warp 内的线程)参与 warp 内置函数运算。关于 warp 内置函数的详细信息,请参阅【CUDA编程】束内表决函数(Warp Vote Function)和【CUDA编程】束内洗牌函数(Warp Shuffle Functions)。
由于这些 warp 内置函数是从 CUDA 9.0 开始引入的,所以为了提高代码兼容性,建议通过如下预处理器宏有条件地执行代码:
1
2
3
#if defined(CUDART_VERSION) && CUDART_VERSION >= 9000
// *_sync intrinsic
#endif
要注意的是,这些内置函数可用于所有架构,而不仅仅是 Volta 或 Turing 架构,并且在大多数情况下,单个代码库就足以满足所有架构的需求。但是对于 Pascal 和更早的架构,mask 中的所有线程在聚合时必须执行相同的 warp 内置函数,并且 mask 中所有值的并集必须等于 warp 内置函数的掩码。以下代码模式在 Volta 架构上合法,但在 Pascal 或更早的架构上不合法。
1
2
3
4
5
6
7
8
9
if (tid % warpSize < 16) {
...
float swapped = __shfl_xor_sync(0xffffffff, val, 16);
...
} else {
...
float swapped = __shfl_xor_sync(0xffffffff, val, 16);
...
}
对于 Pascal 或更早的架构的正确写法应该是在 __shfl_xor_sync 中分别传入 0x0000ffff、0xffff0000 作为 mask,这样才能保证实际活动线程与 mask 一致。
在 Volta 架构下,旧版本 __ballot(1) 函数的替代品是 __activemask() 函数,用来返回活动状态的线程掩码。要注意的是,即使在单个代码路径中,warp 中的线程也可能发散,也就是说 warp 发散并不仅限于代码路径这种显式发散的场景,也可能隐式地出现发散。因此,__activemask() 和 __ballot(1) 可能只返回当前代码路径上的活动线程子集。比如以下代码示例:
1
2
3
4
5
6
7
8
9
// Sets bit in output[] to 1 if the correspond element in data[i]
// is greater than ‘threshold’, using 32 threads in a warp.
for(int i=warpLane; i<dataLen; i+=warpSize) {
unsigned active = __activemask();
unsigned bitPack = __ballot_sync(active, data[i] > threshold);
if (warpLane == 0)
output[i/32] = bitPack;
}
上面代码本来在 Pascal 或更早的架构是 warp 聚合的代码,但从 Volta 架构后就不保证聚合了。比如:当 dataLen 不是 warpSize 的整数倍时会有隐式的 warp 发散。但是 __activemask() 只针对当前活动的线程,并不一定包括所有要经过这个地方的 lane,就是说 Volta 架构后 CUDA 不保证 warp 只在循环条件下发散,如果有其他原因导致发散,那可能计算出的结果就会和预期不同。比如说有 mask 为 0xffff0000 的 16 个线程要执行 __activemask(),Pascal 或更早的架构会对这 16 个线程统一返回 active = 0xffff0000。但从 Volta 架构后,可能这 16 个线程是分两组过去的,可能前 8 个线程得到 active = 0xff000000,后 8 个线程得到 active = 0x00ff0000。官方文档中给出的一个正确写法如下:
1
2
3
4
5
6
7
8
for(int i=warpLane; i-warpLane<dataLen; i+=warpSize) {
unsigned active = __ballot_sync(0xFFFFFFFF, i < dataLen);
if (i < dataLen) {
unsigned bitPack = __ballot_sync(active, data[i] > threshold);
if (warpLane == 0)
output[i/32] = bitPack;
}
}
新的代码中使用了非发散的循环条件和束内表决函数 __ballot_sync() 安全地表决出当前代码路径下的满足 i < dataLen 线程的掩码。
Volta 架构引入了 warp 内同步函数 __syncwarp(),应用程序中针对全局内存和共享内存的读写操作,如果假设了某个操作对同一 warp 中的其他线程可见,那么必须在相应的读写操作之间插入同步指令 __syncwarp(),显式地让 warp 内的线程都到达该屏障点。如果没有显式使用 __syncwarp() 进行同步,那么任何关于 warp 内线程步调一致执行的假设都是不可靠并错误的。下面给出一个 block 内规约场景使用到 warp 内同步函数 __syncwarp() 的代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
__shared__ float s_buff[BLOCK_SIZE];
s_buff[tid] = val;
__syncthreads();
// Inter-warp reduction
for (int i = BLOCK_SIZE / 2; i >= 32; i /= 2) {
if (tid < i) {
s_buff[tid] += s_buff[tid+i];
}
__syncthreads();
}
// Intra-warp reduction
// Butterfly reduction simplifies syncwarp mask
if (tid < 32) {
float temp;
temp = s_buff[tid ^ 16]; __syncwarp();
s_buff[tid] += temp; __syncwarp();
temp = s_buff[tid ^ 8]; __syncwarp();
s_buff[tid] += temp; __syncwarp();
temp = s_buff[tid ^ 4]; __syncwarp();
s_buff[tid] += temp; __syncwarp();
temp = s_buff[tid ^ 2]; __syncwarp();
s_buff[tid] += temp; __syncwarp();
}
if (tid == 0) {
*output = s_buff[0] + s_buff[1];
}
__syncthreads();
尽管 _syncthreads() 一直被认为是同步 block 中的所有线程,但在 Pascal 或更早的架构中只支持在 warp 级别强制同步。因此在某些情况下,只要每个 warp 中至少有一些线程到达屏障,这就会认为 block 所有线程均到达屏障点,这在独立线程调度引入之前是可行的。但从 Volta 架构开始,CUDA 内置的 __syncthreads() 和 PTX 指令 bar.sync(及其派生类)在 block 内每个线程中强制执行,因此在 block 中所有未退出的线程到达之前,屏障不会成功。
3.3 全局内存
Volta 和 Turing 架构下全局内存的行为方式与 Maxwell 架构相同。
3.4 共享内存
前面介绍过,在 Volta 和 Turing 架构中,L1 缓存、纹理缓存和共享内存三者在物理上被统一成了一个数据缓存,其中共享内存容量可以使用 CUDA Runtime API 进行设置。对于 Volta 架构,统一数据缓存大小为 128 KB,共享内存容量可以设置为 0、8、16、32、64 或 96 KB;而对于 Turing 架构,统一数据缓存大小为 96 KB,共享内存容量可以设置为 32 或 64 KB。与 Kepler 架构不同,驱动程序会自动为每个 Kernel 配置共享内存容量以避免共享内存占用瓶颈,从而允许该 Kernel 与已启动的 Kernel 并发执行。在大多数情况下,驱动程序的默认行为会提供最佳性能。
由于驱动程序并不保证能知道 Kernel 的全部共享内存负载,所以有些情况下应用程序显式提供共享内存容量配置会取得更好的性能,比如,对于某些使用很少或不使用共享内存的 Kernel 来说,给其设置更大的共享内存容量,一定程度上可能增加它与其他 Kernel(比如需要使用较多共享内存)的并发程度。
在 Volta 和 Turing 架构中提供了新的 cudaFuncSetAttribute() API,使得用户可以自定义一个首选的共享内存容量(即在统一数据缓存中的划分比例),注意这个 API 是 per-Kernel 级的。与 Kepler 架构引入的传统 cudaFuncSetCacheConfig() API 相比,cudaFuncSetAttribute() 放宽了启动时对首选共享容量的要求,也就是说,旧版 API 将共享内存容量视为内核启动的硬性要求,导致不同共享内存容量配置的 Kernel 会先执行一个 Kernel,完成后重设共享内存容量,然后再执行下一个 Kernel。而使用新的 API 时,用户指定的划分比例只是一个提示,驱动程序可能根据实际情况选择与此不同的配置以获取最佳性能。下面给出使用 cudaFuncSetAttribute() API 的代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// Device code
__global__ void MyKernel(...)
{
__shared__ float buffer[BLOCK_DIM];
...
}
// Host code
int carveout = 50; // prefer shared memory capacity 50% of maximum
// Named Carveout Values:
// carveout = cudaSharedmemCarveoutDefault; // (-1)
// carveout = cudaSharedmemCarveoutMaxL1; // (0)
// carveout = cudaSharedmemCarveoutMaxShared; // (100)
cudaFuncSetAttribute(MyKernel, cudaFuncAttributePreferredSharedMemoryCarveout, carveout);
MyKernel <<<gridDim, BLOCK_DIM>>>(...);
上面的代码中把 MyKernel 的首选共享内存容量占比设定为 50\%,注释中还提供了几个其他的参考枚举值。如果选择的整数百分比不能完全映射到支持的容量(比如 Volta 架构的设备支持 0、8、16、32、64 或 96 KB 的共享容量),则自动使用下一个更大的容量。例如,在上面的示例中,最大容量 96 KB 的 50\% 是 48 KB,这不是受支持的共享内存容量,因此,实际会向上舍入为 64 KB。
在 Volta 和 Turing 架构中,允许单个线程块能够寻址全部 96 KB 的共享内存。 为了保证不同架构下代码兼容性,静态共享内存分配仍被限制为 48 KB,如需寻址超过 48 KB 的共享内存,需要使用动态共享内存的方式,并且使用 cudaFuncSetAttribute() API 显式指定,示例代码如下。
1
2
3
4
5
6
7
8
9
10
11
// Device code
__global__ void MyKernel(...)
{
extern __shared__ float buffer[];
...
}
// Host code
int maxbytes = 98304; // 96 KB
cudaFuncSetAttribute(MyKernel, cudaFuncAttributeMaxDynamicSharedMemorySize, maxbytes);
MyKernel <<<gridDim, blockDim, maxbytes>>>(...);
3.5 Tensor Core
与上一代 Pascal 架构相比,Volta 架构引入了 Tensor Core,并在 Turing 架构中进一步增强,以满足神经网络中数以百万计的神经元所需的训练、推理性能。
每个 Tensor Core 执行以下运算:$D = A \times B + C$
其中 $A$、$B$、$C$ 和 $D$ 是 $4\times4$ 矩阵,矩阵 $A$、$B$ 元素类型为 FP16,而累加矩阵 $C$ 和 $D$ 的元素类型可以是 FP16 或 FP32。在实际应用中,Tensor Core 被用来执行更大的 2D 或更高维的矩阵运算,这些大矩阵的乘法运算都是由这些 $4\times4\times4$ 的矩阵运算组成的。
在 CUDA 9 C++ API 中提供了 Warp-Level 矩阵运算 API 用来调动 Tensor Core 进行运算。该 API 支持专门的矩阵加载、矩阵乘法、累加以及矩阵存储操作,以有效地使用 Tensor Core 的性能。除了直接使用 CUDA C++ Warp-Level 矩阵运算 API 以外,cuBLAS 和 cuDNN 等官方库也已经完成底层代码更新以利用 Tensor Core 进行深度学习应用,用户可以直接使用这些官方库,而不必基于 Warp-Level 矩阵运算 API 重新编写代码。
4 计算能力 8.x
4.1 体系架构
计算能力 8.x 的 GPU 设备采用 Ampere 架构,下图展示了该架构下的流多处理器(SM)的结构示意图(以 Tesla GA100 为例)。
- https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/
- https://www.nvidia.com/content/PDF/nvidia-ampere-ga-102-gpu-architecture-whitepaper-v2.pdf
在 Ampere 架构下,一个 SM 中包括:
- 64(计算能力 8.0)或 128(计算能力 8.6、8.7、8.9)个用于单精度浮点算术运算的 FP32 Core;
- 32(计算能力 8.0)或 2(计算能力 8.6、8.7、8.9)个用于双精度浮点算术运算的 FP64 Core;
- 64 个用于整数算术运算的 INT32 Core;
- 4 个混合精度第三代 Tensor Core,支持
fp16、__nv_bfloat16、tf32、sub-byte、fp64等数据类型的矩阵运算(计算能力 8.0、8.6、8.7); - 4 个混合精度第四代 Tensor Core,支持
fp8、fp16、__nv_bfloat16、tf32、sub-byte、fp64等数据类型的矩阵运算(计算能力 8.9); - 16 个用于单精度浮点运算的特殊函数单元;
- 4 个 warp 调度器;
- 由所有功能单元共享的常量内存的缓存,可加快从驻留在设备内存中的常量内存空间的读取速度;
- 一个统一的 192 KB(计算能力 8.0、8.7)或 128 KB(计算能力 8.6、8.9)的 纹理/L1 缓存/共享内存。
同 Volta 和 Turing 架构一样,在 Ampere 架构中 L1 缓存、纹理缓存和共享内存三者在物理上被统一成了一个有 192 KB 或 128 KB 的数据缓存,用户可以使用 CUDA Runtime API 来指定其中共享内存所占的容量大小。
4.2 全局内存
Ampere 架构下全局内存的行为方式与 Maxwell 架构相同。
4.3 共享内存
同 Volta 和 Turing 架构一样,共享内存容量可以使用 CUDA Runtime API 进行设置,只是可设置的共享内存容量值不同。对于计算能力为 8.0、8.7 的设备,统一数据缓存大小为 192 KB,共享内存容量可以设置为 0、8、16、32、64、100、132 或 164 KB;而计算能力为 8.6、8.9 的设备,统一数据缓存大小为 128 KB,共享内存容量可以设置为 0、8、16、32、64 或 100 KB。
计算能力 8.0、8.7 的设备允许单个线程块寻址多达 163 KB 的共享内存,而计算能力 8.6、8.9 的设备允许多达 99 KB 的共享内存。Ampere 架构中每个线程块的最大共享内存量小于每个 SM 上可用的最大共享内存分区,未提供给线程块使用的 1 KB 共享内存将保留给系统使用。超过 48 KB 的共享内存使用,需要使用动态共享内存的方式,并且使用 cudaFuncSetAttribute() API 显式指定。
5 计算能力 9.x
5.1 体系架构
当前最新的 GPU 设备计算能力最高只到 9.0,采用 Hopper 架构,下图展示了该架构下的流多处理器(SM)的结构示意图(以 Tesla GH100 为例)。
在 Hopper 架构下,一个 SM 中包括:
- 128 个用于单精度浮点算术运算的 FP32 Core;
- 64 个用于双精度浮点算术运算的 FP64 Core;
- 64 个用于整数算术运算的 INT32 Core;
- 4 个混合精度第四代 Tensor Core,支持
fp8、fp16、__nv_bfloat16、tf32、INT8、fp64等数据类型的矩阵运算; - 16 个用于单精度浮点运算的特殊函数单元;
- 4 个 warp 调度器;
- 由所有功能单元共享的常量内存的缓存,可加快从驻留在设备内存中的常量内存空间的读取速度;
- 一个统一的 256 KB 的纹理/L1 缓存/共享内存。
在 Hopper 架构中 L1 缓存、纹理缓存和共享内存三者在物理上被统一成了一个有 256 K 的数据缓存,用户可以使用 CUDA Runtime API 来指定其中共享内存所占的容量大小,从 Volta 架构开始,连续 4 个大版本一直保持该形式,只是缓存容量有所变化。
5.2 全局内存
Hopper 架构下全局内存的行为方式与 Maxwell 架构相同。
5.3 共享内存
与 Ampere 架构类似,共享内存容量可以使用 CUDA Runtime API 进行设置,只是可设置的共享内存容量值不同。对于计算能力为 9.0 的设备(如 NVIDIA H100 Tensor Core GPU),统一数据缓存的大小为 256 KB,共享内存容量可以设置为 0、8、16、32、64、100、132、164、196 或 228 KB。
计算能力 9.0 的设备允许单个线程块寻址多达 227 KB 的共享内存,超过 48 KB 的共享内存使用,需要使用动态共享内存的方式,并且使用 cudaFuncSetAttribute() API 显式指定。
5.4 加速专用计算
Hopper 架构还引入了以下特性,用来加速矩阵乘加(MMA)计算:
- MMA 指令的异步执行;
- 应用于跨 warp 大矩阵的 MMA 指令;
- 在 warp 组之间动态重新分配寄存器容量,以支持更大的矩阵;
- 直接从共享内存访问的操作数矩阵
这些功能仅在 CUDA 编译工具链中通过内联 PTX 提供,并已经在 CUDA 官方库的底层代码中更新。建议用户通过 CUDA-X 库(如 cuBLAS、cuDNN 或 cuFFT)利用上述特性。同时也建议用户在编写 Kernel 代码时通过 CUTLASS 库利用这些特性,CUTLASS 是一个基于 CUDA C++ 模板抽象的集合,使得用户可以在 CUDA 内的所有级别和尺度上进行高性能矩阵乘法(GEMM)和相关计算。
资料
- CUDA GPU Compute Capability:不同计算能力CC对应的 GPU 设备列表。
- Matching CUDA arch and CUDA gencode for various NVIDIA architectures:不同GPU及CC对应的 gencode 列表。