使用 CuTe 实现一个 naive GEMM(未完成)
使用 CuTe 实现一个 naive GEMM(未完成)
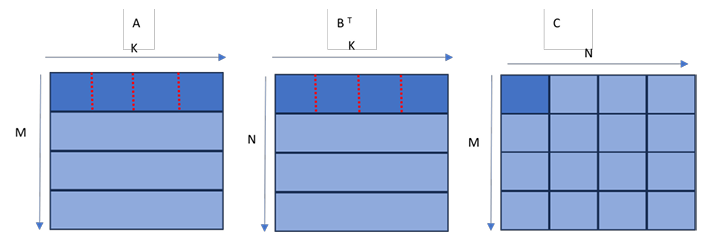
1. 总体思路
按照两部划分的方法:Thread Block – tile,Thread – sub-tile。即矩阵划分为按照两个维度划分为tile的形式,每个tile由一个 Thread Block 负责计算。每个 Thread Block 内的线程继续划分 tile 为 sub-tile,每个线程负责计算一个 sub-tile。
给定矩阵,且每个矩阵均为列主序:
\[C(M, N) = A(M, K) * B(K, N)^T\]列主序:如矩阵 A,第一列 M 个数据在内存中是连续存储的,之后为第二列 M 个数据,依次类推。 矩阵 B 转置之后,其尺寸为 (N, K),且仍然为列主序存储。
给定如下的矩阵尺寸,以及 tile 大小划分:
- M、N、K:矩阵的维度。M =1024,N=1024,K=1024*8。
- BM、BN、BK:划分后的 tile 大小。 BM=64,BN=64,BK=16。
- TM、TN:每个线程负责计算的 sub-tile 大小。 TM=8,TN=8。
- 使用 Cute 建立 A、B、C 的 tile(即第一级分块)的 slice 视图:指定当前 Block Thread(也叫 CTA)需要处理的 tile 的 shape,以及 stride。
- 给 A、B 的 tile 分配 shared memory,并建立共享内存的视图(shape + stride)。
- 建立线程的累加器视图(shape + stride),并分配寄存器内存。用于累加每个线程计算的 sub-tile 结果。
- Thread Block 需要将数据从全局内存加载到 shared memory 中,所以需要创建一个如何从全局内存 tile 复制数据到 shared memory tile 的规则,使用 layout 表示。并最终给每个线程分配一个复制区域,以 Tensor 表示,且全局内存分配一个 Tensor,Shared Memory 分配一个 Tensor。
资料
本文由作者按照 CC BY 4.0 进行授权