OpenCL 平台模型、执行模型
OpenCL 平台模型、执行模型
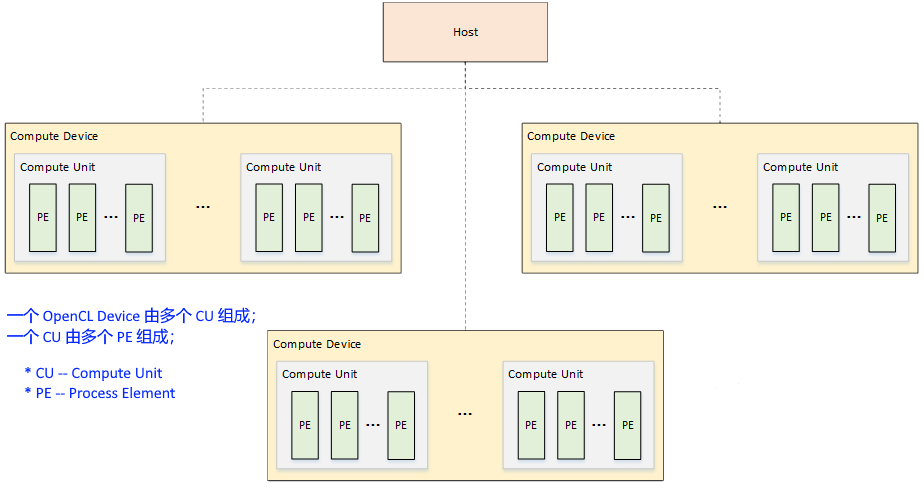
1. 平台模型
关键词:
OpenCL DeviceCU–Compute UnitPE–Processing Element
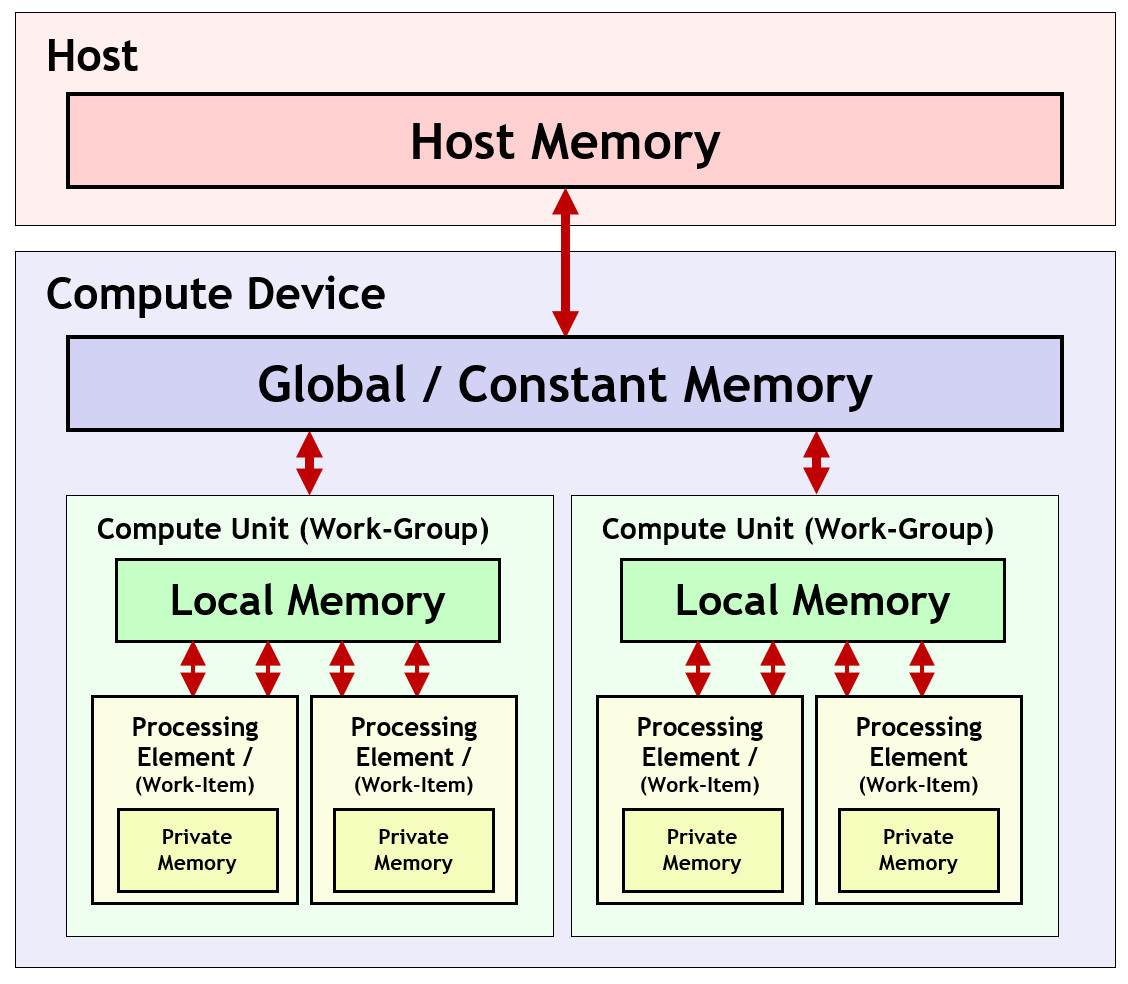
2. 内存模型
3. 执行模型
3.1 Context
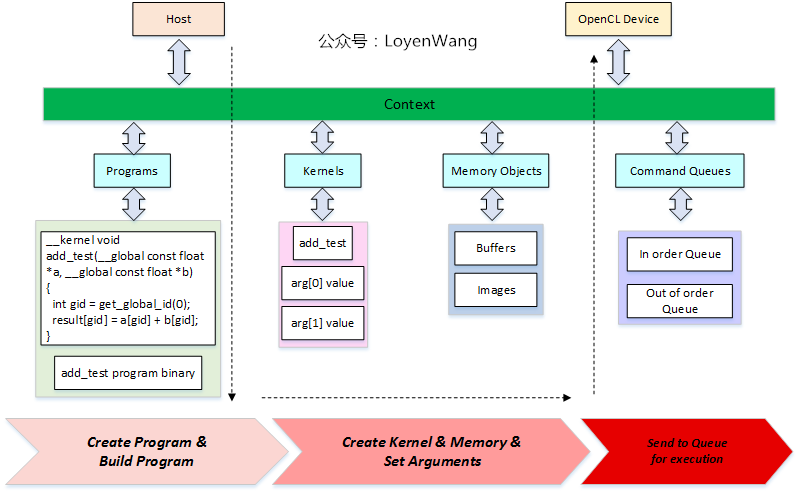
Context 是针对Host端编程而产生的概念,表示设备的执行环境,包含:
Devices:一个或多个OpenCL物理设备;Memory Objects:Host端和/或Device端可见的内存对象;Program Objects: 包含源码及编译后的二进制代码;kernel Objects:Device端执行的函数对象;
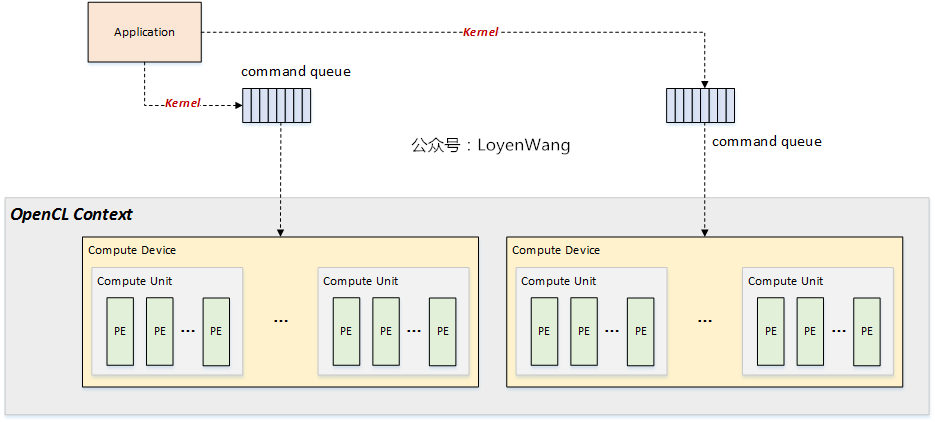
3.1.1 命令队列 Command Queue
一个Command Queue 对应一个Device。一个 Command Queue 中的命令包含如下三种类型:
Kernel相关命令:执行Kernel函数;Memory相关命令:host<–>device数据传输;host<–>devicememory map / unmap;Memory Objects之间数据传输;
- 同步相关命令;
除了主机端往命令队列中添加命令外,在设备端,Kernel执行的时候,也可以往设备端的命令队列中添加命令,比如启动 Child kernel。
如下图中的Ended表示所有该命令中的所有Work Group执行完毕,但可能Child kernel还没有执行完毕,以及更新global memory中的数据。
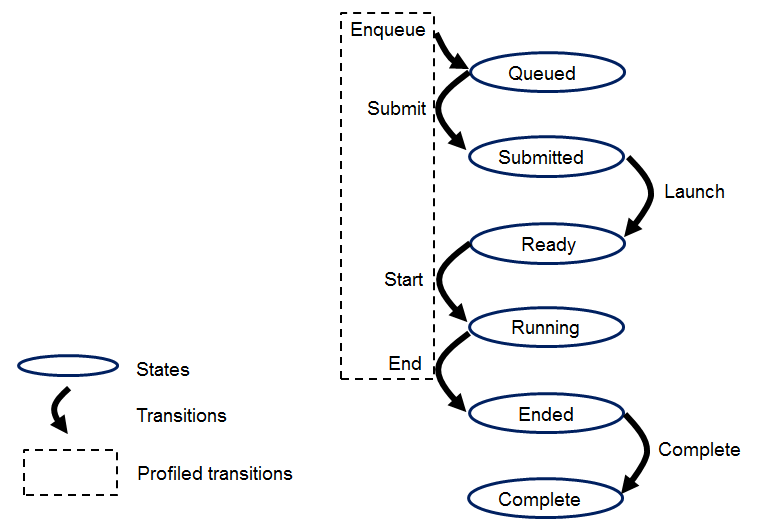
关于每个状态的解释,参考 OpenCL 3.0 Spec – 3.2. Execution Model
Queued:初始状态;Submitted:提交到Device,还没还有放入设备端的work pool– 比如需要的资源没有准备好,或者work pool满;Ready:命令提交到work pool,等待被调度;Running:已经被调度器调度到CU开始执行;Ended:所有work group执行完毕;Complete:Child kernel执行完毕,global memory中的数据更新完毕;
- 个人理解:一个
Command Queue同时存在于主机端,以及设备端 ??
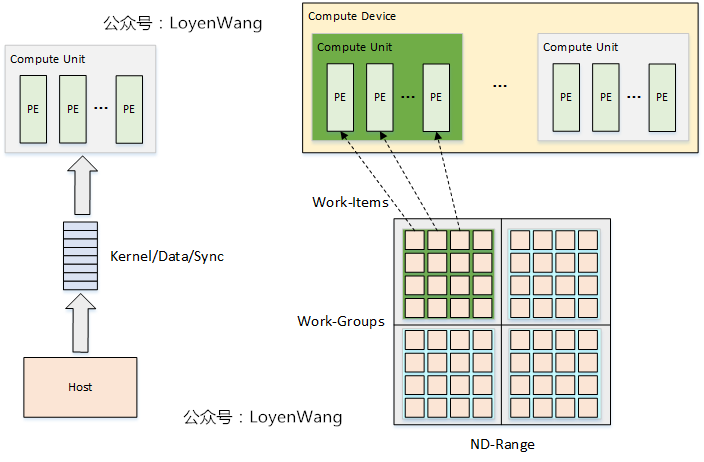
3.2 NDRange – 索引空间
表示一维 / 二维 / 三维索引空间:global index, group index, local index。
OpenCL 软件调度将全局 work items 按 group 为单位,分配给 CU(一个 CU 包含多个 PE)。CU执行完当前 group 后,再调度下一个 group 到 CU 上执行。
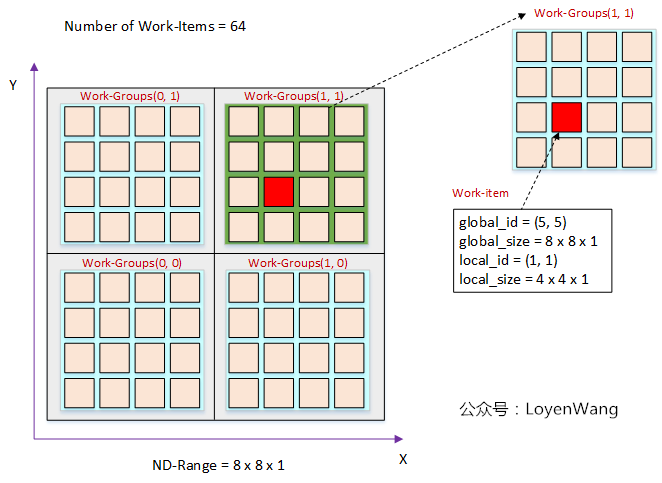
3.3 Work-Item index 关系
划分好 work group size 之后,可以相互换算global index 和 local index,以及 group index。例如matrix大小为 $G_{x}$ x $G_{y}$,将其划分为 $W_{x}$ x $W_{y}$ 个工作组, 每个工作组的大小为 $L_{x}$ x $L_{y}$,则:
根据工作项ID($l_x$, $l_y$)可以计算出全局ID($g_x$, $g_y$):
\[\begin{cases} g_x = w_x * L_{x} + l_x \\ g_y = w_y * L_{y} + l_y \end{cases}\]相反的,根据全局ID,计算出工作项ID,以及工作组ID,只需要分别进行取余、除法运算即可。
4. 编程模型
4.1 编程模型
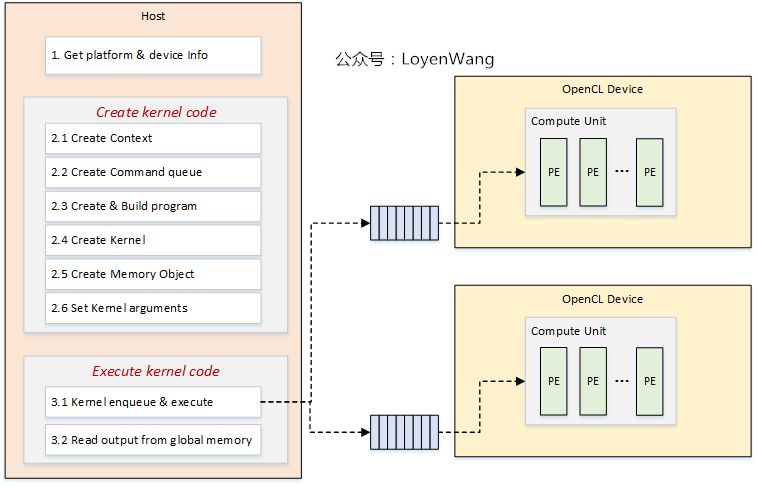
4.2 编程流程
5. 参考资料
6. 附加资料
本文由作者按照 CC BY 4.0 进行授权