perf性能分析(2) -- Intel VTune 配置与使用(2)
perf性能分析(2) -- Intel VTune 配置与使用(2)
测试代码:test_tbb_perf_vtune_profiler
注意:编译选项需要添加”-g”,以便于VTune Profiler可以显示源码信息。
1. 测试原始来源
VTune Profiler 进行性能分析:使用VTune Profiler测试TBB overhead。
2. 资料
Intel TBBAPI 使用教程:Intel® oneAPI Threading Building Blocks- Too long TBB’s shedule time when using parallel_deterministic_reduce
3. 测试过程及优化
3.1 reduce
- 针对一些比如遍历求和操作,他们之间没有顺序要求,可以改用并行的
reduce。前提是数据的构造代价小,如稀疏矩阵拷贝代价就比较大。 - 计算的先后顺序有关的,比如针对浮点的乘加操作,先后顺序变化影响计算精度,此时使用
parallel_deterministic_reduce。官方解释是:合并顺序是预先定义好的,确保每次调用deterministic_reduce的结果相同。
3.2 几个不同的优化方式
Intel TBB 动态划分任务,以及把任务提交给线程执行,都需要消耗时间。优化包括:
- 调整
grain size减少调度的开销。 - 使用静态划分
static_partitioner减少调度开销。
3.2.1 调整 grain size
通过设置grain size,可以大致设定 TBB 每个任务要处理的数据量,即划分粒度:
1
tbb::blocked_range<double*>(v, v + n, 1000)
设置grain size之前,显示的热点 call stack 如下图(100次循环):
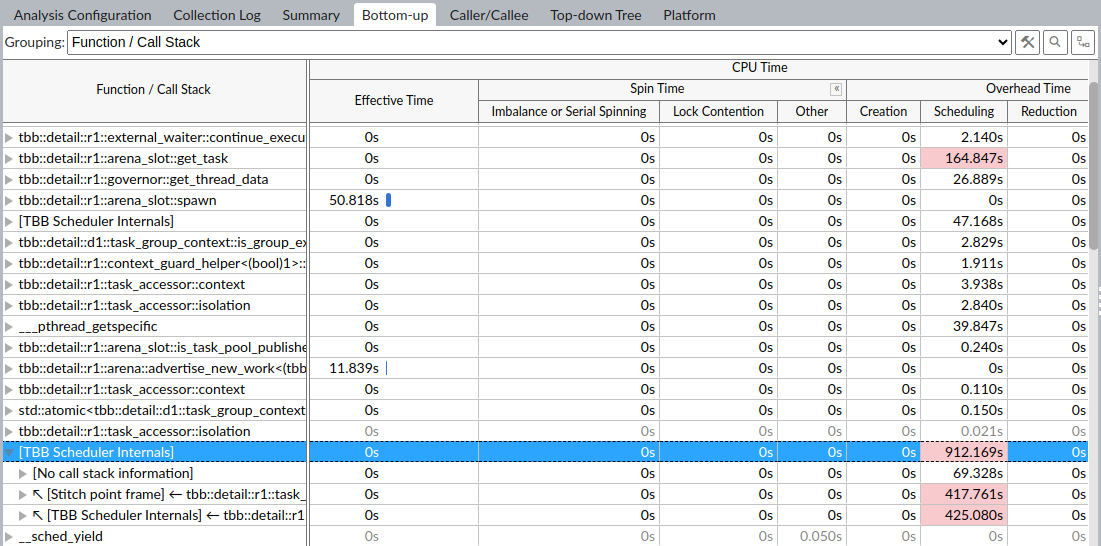
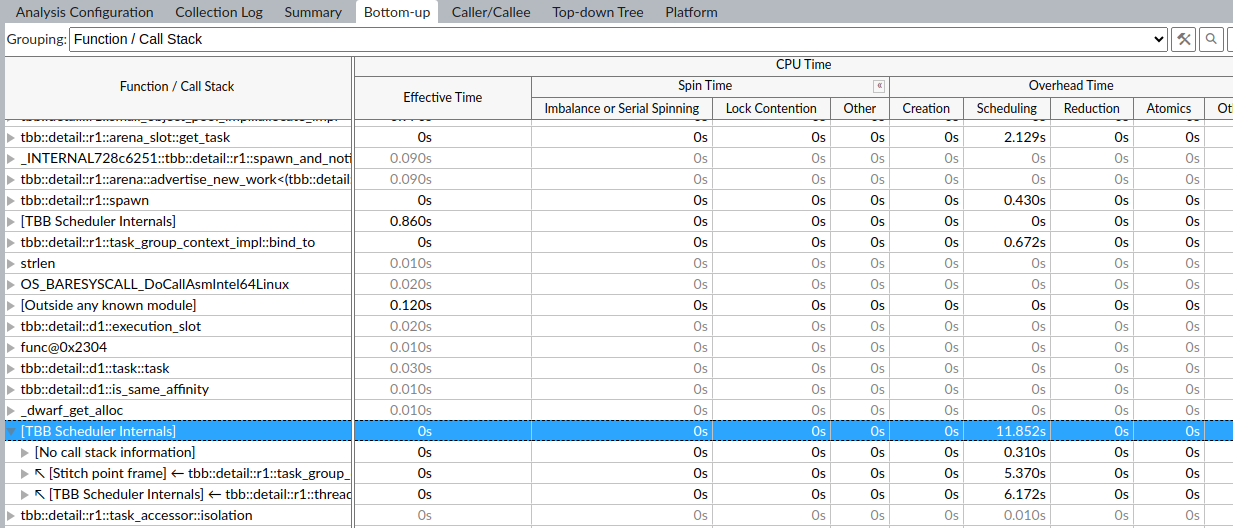
设置grain size等于10000,Intel TBB 内部调度时间明显减少(10000次循环):
3.2.2 使用静态划分static_partitioner
通过设置使用static_partitioner,即预先划分好任务,减少调度开销,具有与blocked_range类似的效果,但其控制的方式不同。
static_partitioner适用于任务均衡的计算场景。
1
2
3
4
5
6
7
8
9
tbb::task_arena ta(8);
double sum = ta.execute([&]() {
return tbb::parallel_deterministic_reduce(
tbb::blocked_range<double*>(v, v + n), 0.0,
[](const tbb::blocked_range<double*>& r, double value) -> double { return std::accumulate(r.begin(), r.end(), value); },
std::plus<double>(), tbb::static_partitioner{});
});
return sum;
本文由作者按照 CC BY 4.0 进行授权