perf性能分析(7) -- Top-down 分析方法
现代性能分析,使用针对pipeline的分析办法(取代CPU cycles分析)。这源于现代CPU架构的复杂性。
现代CPU处理指令架构,分为前端 Front-end,后端 Back-end两部分。阻碍指令执行的因素,从硬件看,源于前端或后端的Stall。
1. CPU 流水线
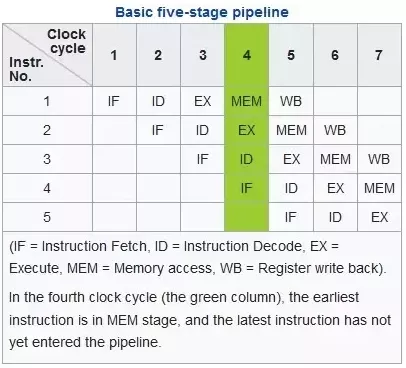
Intel CPU流水线一般分为5级。其中解码(ID),意思是将指令操作分解为多个uOp(即拆分为多个更低级的硬件操作),如ADD eax, [mem1],可以拆分成两个微指令:从内存读取数据,再执行ADD操作。
2. CPU 架构及流水线的执行过程
执行过程:前端执行完IF -> ID之后,然后在一个名为allocation的过程中,uOps被输送到后端。后端监控uOp的操作数(data operand)何时可用,并在可用的执行单元中执行uOps。 当uOp执行完成之后,称之为执行完成(retirement),且uOp的结果被写会寄存器或者内存。
大多数uOps都会完全通过流水线并退出,但有些投机指令uOps可能会在退出前被取消–如预测错误的分支。
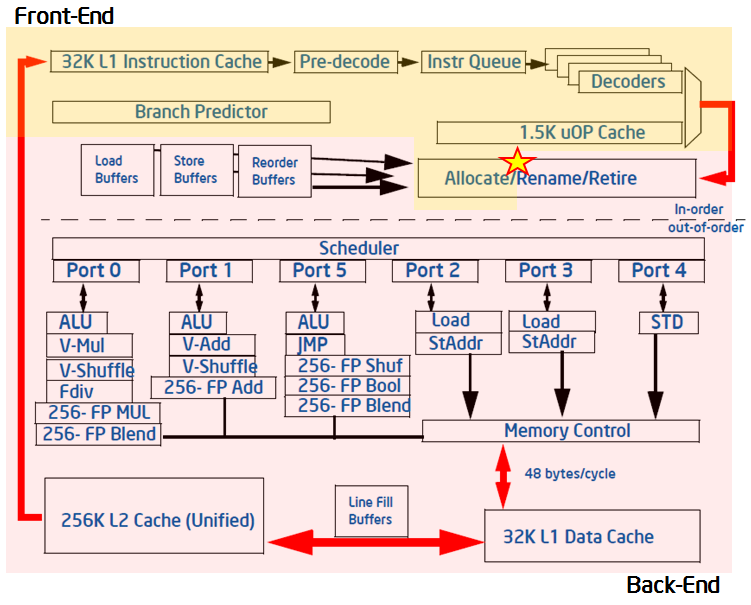
在处理器架构中,有一个抽象概念:pipeline slot,即执行端口。在Intel处理器中,一个core一般有四个执行端口,即每个cycle最多可以执行四个uOps。VTune在allocation阶段,可以测量pipeline slot的利用率(星号标注的地方)。
3. Top-down 分析方法
从性能分析的角度看,一条微指令在流水线中的性能指标可以分为:
- 退出(
Retiring) –Micro Sequencer(微指令调度器)可能会成为瓶颈,例如调度浮点指令。 - 分支预测错误(
Bad Speculation) – 分支预测错误,或者memory ordering violation(多核多线程共享数据情形),导致Machine Clears(清除流水线)。 - 前端瓶颈(
Front-End Bottleneck) - 后端瓶颈(
Back-End Bottleneck)
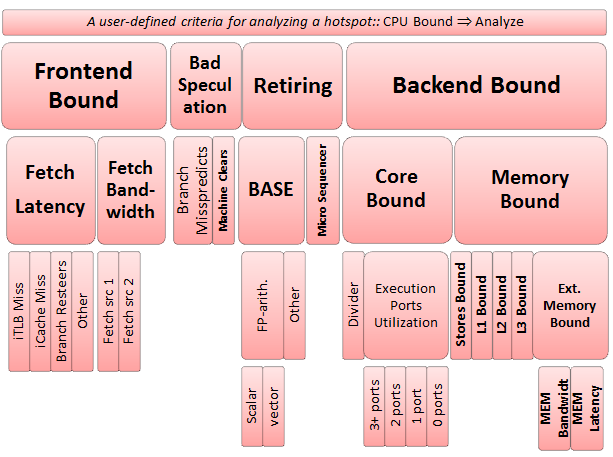
顶级分类分析步骤:
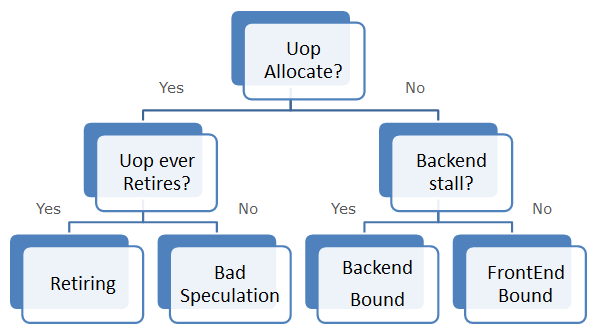
3.1 Frontend Bound – 前端瓶颈
前端主要职责为读取指令,解码之后,发送给后端。遇到分支指令,需要经过预测器预测下一个指令的地址,这意味着会出现由于分支预测错误导致的ICache Miss而引起前端阻塞。
3.2 Back-End Bound – 后端瓶颈
后端主要职责为执行指令,包括ALU、FPU、Memory等。后端瓶颈分为:
Core BoundMemory Bound
如D Cache Miss,浮点除法器过载,指令依赖、数据依赖等。
4. 一些优化手段
4.1 Frontend
- 减少代码的
footprint,如-fomit-frame-pointer - 调整代码布局:如是用
-fprofile-generate -fprofile-use - 调整代码布局:如用
__attribute__((hot)) - 分支预测优化:如
loop unrolling,特别是小的循环,如小于64次循环 - 分支预测优化:是用
if代替三目运算符;避免if-elses结构,switch-case排序
4.2 Back-End
- 减少
function call,如inline - 多线程避免
false-sharing,使用内存对齐 - gcc优化:如
__builtin_expect
4.3 示例
1
2
3
4
5
6
7
8
9
#define likely(x) __builtin_expect(!!(x), 1) //gcc内置函数, 帮助编译器分支优化
#define unlikely(x) __builtin_expect(!!(x), 0)
if(likely(condition)) {
// 这里的代码执行的概率比较高
}
if(unlikely(condition)) {
// 这里的代码执行的概率比较高
}
1
2
3
4
5
6
7
8
#define CACHE_LINE __attribute__((aligned(64)))
struct S1 {
int r1;
int r2;
int r3;
S1(): r1(1),r2(2),r3(3){}
} CACHE_LINE;
5. Hazard 介绍
5.1 StructuralHazards – 结构性冲突
结构性冲突本质是CPU中硬件资源的竞争,比如流水线中,前后指令之间都需要经过译码器,访问内存,形成对译码器的争用。
5.2 DataHazards – 数据依赖
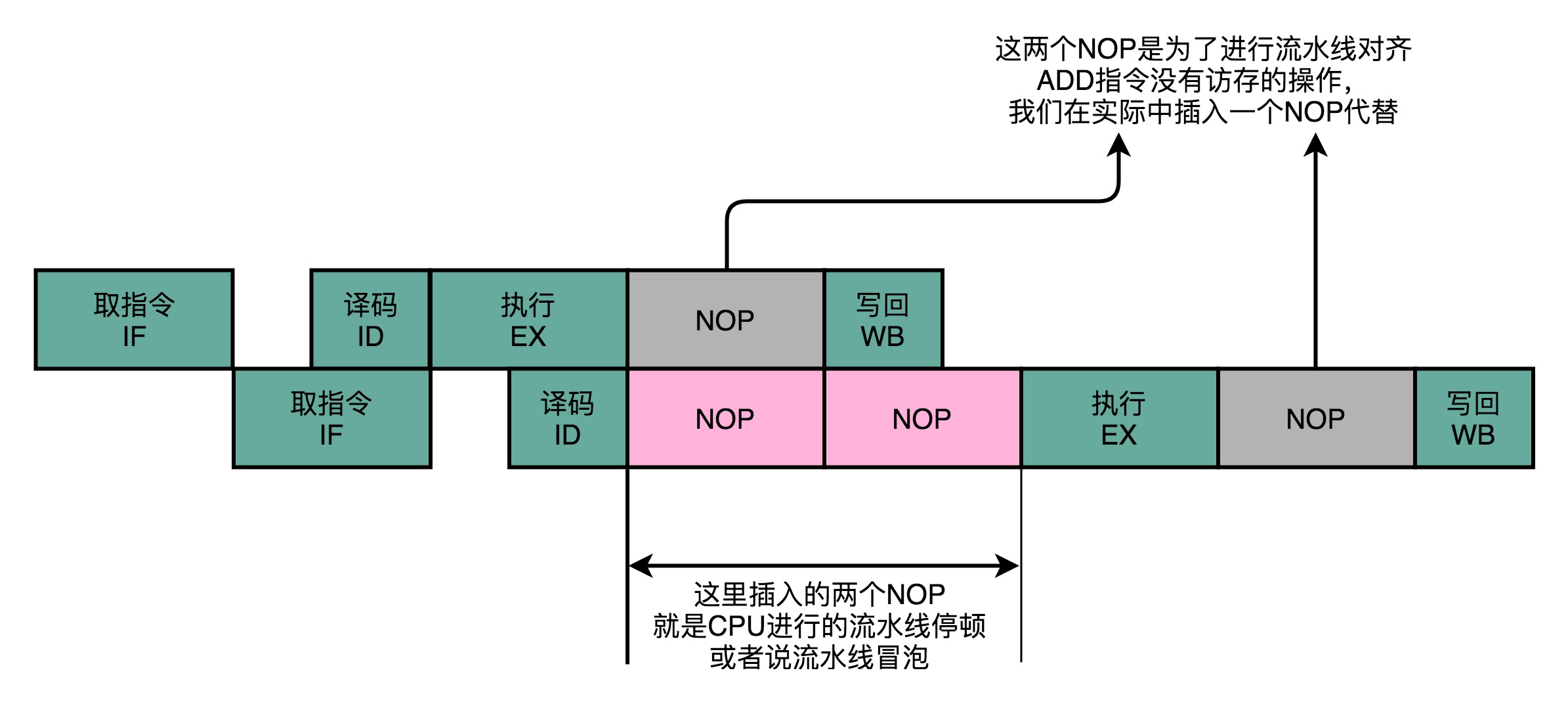
五级流水线:取指IF -> 解码ID -> 执行EX -> 内存访问MEM -> 写回WB。
Data Hazard是指后一条指令的操作数,依赖于前一条指令的结果。操作数依赖分为三种关系:
- 先写后读(
Write-after-Read) –Data Denpendency - 先读后写(
Read-after-Write) –Anti-Dependency - 写后写(
Write-after-Write) –Output Dependency
CPU处理Data Hazard办法有两种:
- 插入
NOP指令,流水线停顿(Pipeline Stall),或者叫流水线冒泡(Pipeline Bubbling)。 Operand Forwarding– 操作数转发。
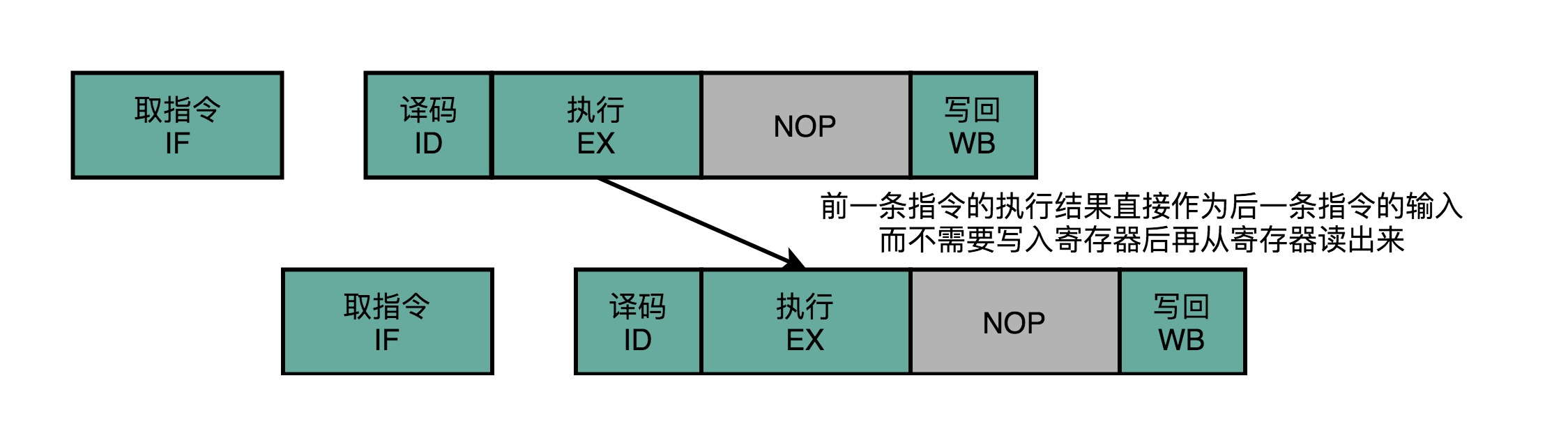
Operand Forwarding:在第一条指令的执行阶段完成之后,直接将结果数据传输给到下一条指令的 ALU。然后,下一条指令不需要再插入两个 NOP 阶段,就可以继续正常走到执行阶段。这样的解决方案,我们就叫作操作数前推(Operand Forwarding),或者操作数旁路(Operand Bypassing)。其实更合适的名字应该叫操作数转发。这里的 Forward,其实就是我们写 Email 时的“转发”(Forward)的意思。
5.3 ControlHazards – 控制依赖
主要使用分支预测。
5.4 流水线 – 乱序执行
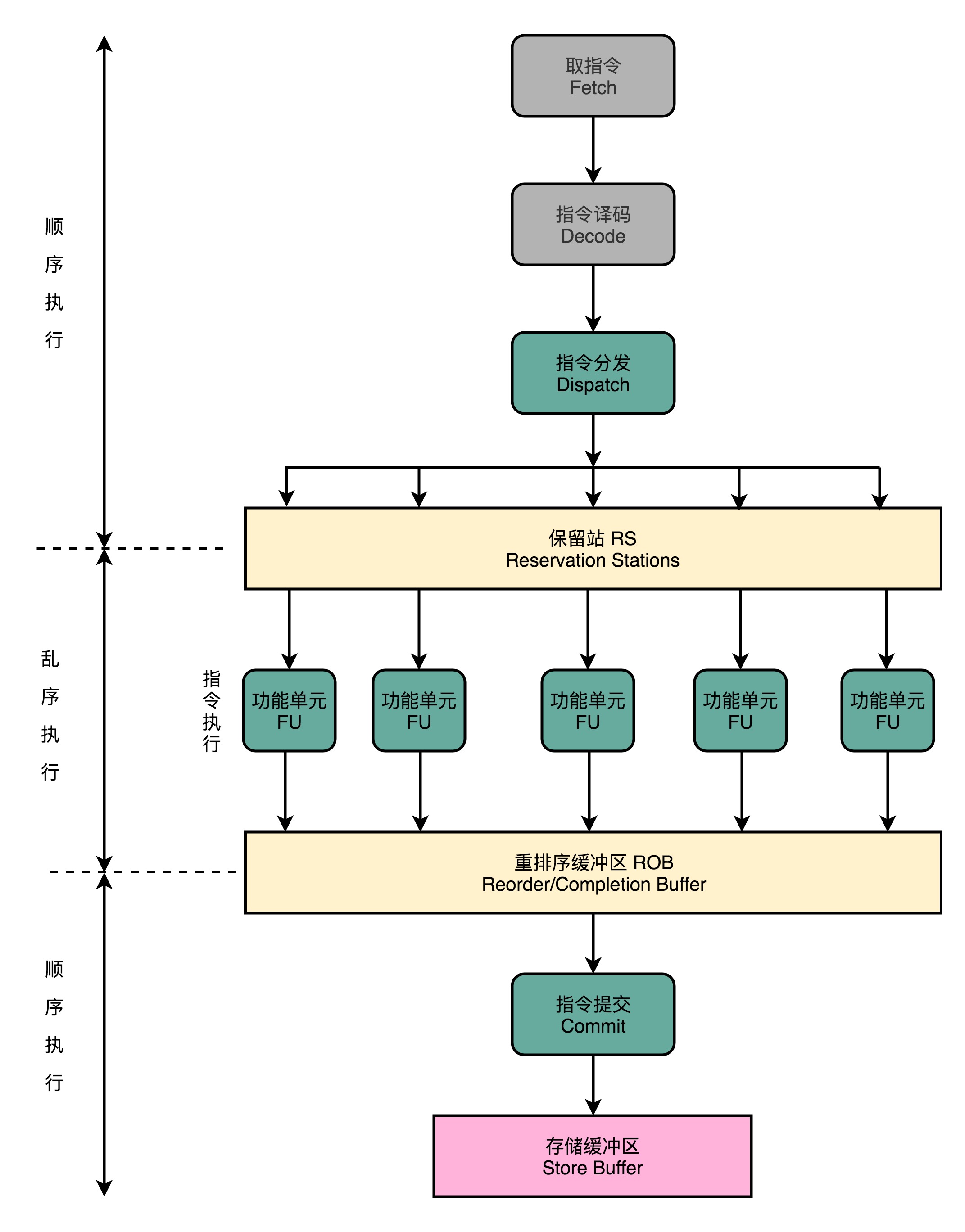
更详细资料:cnblogs – 计算机组成原理——原理篇 处理器(中)
资料
- 自顶向下的微架构分析方法
- Top-down Microarchitecture Analysis Method
- pdf – A Top-Down Method for Performance Analysis and Counters Architecture
- cnblogs –C/C++ 性能优化背后的方法论:TMAM
- 调优指南: Xeon E5 v3
- pdf – intel lectures: Intel_VTune_Amplifier-jackson