整理:内存一致模型
内存一致性模型(Memory Consistency Model)是并发编程中的一个重要概念,它定义了在多线程环境下,内存操作的可见性和顺序性规则。内存一致性模型还涉及到Cache一致性(Cache Coherence)和CPU指令的乱序执行(Out-of-Order Execution)。理解内存一致性模型对于编写正确、高效的并发程序至关重要。
1. CPU Cache 内部结构
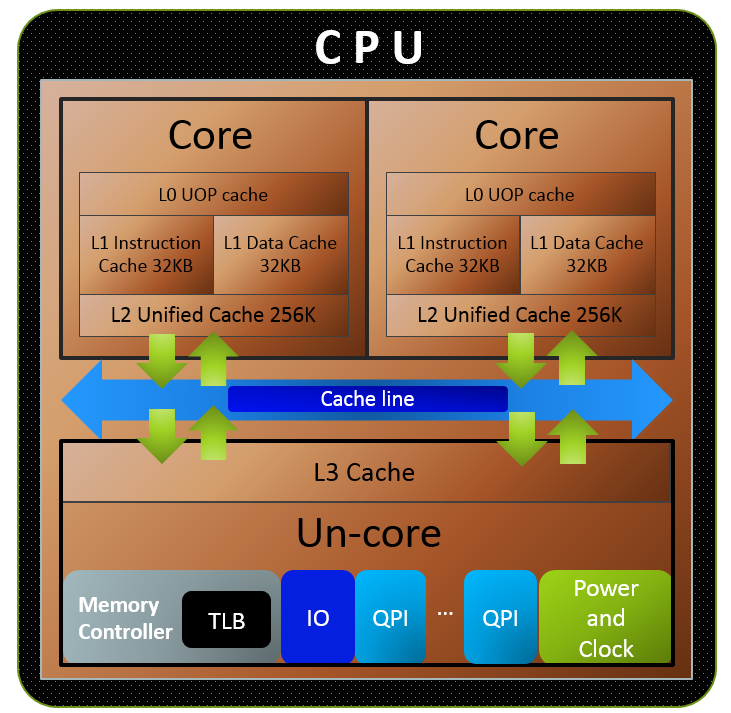
一个core内部结构:
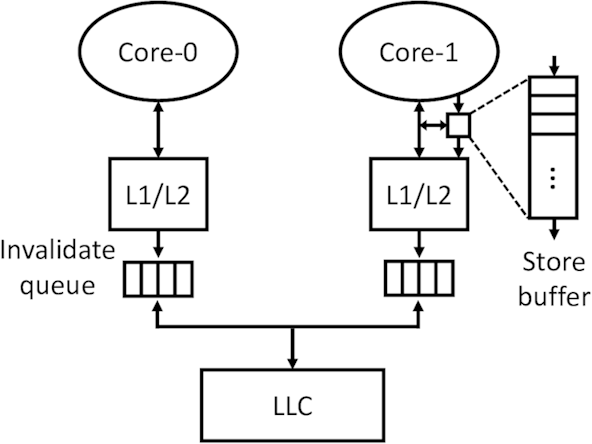
cachestore bufferinvalidate queue
结构如下图所示:
1.1. Cache一致性协议 MESI
MESI是CPU内部多个core同步通讯协议,保证多个core中的cache的数据一致性。MESI这四个字母分别代表了每一个cache line可能处于的四种状态:Modified、Exclusive、Shared 和 Invalid。
通过给cache line设置状态位,以及CPU core(也可能有内存控制器参与)之间的消息同步逻辑,让多个core中的cache数据保持一致性。
在没有store buffer, invalidate queue之前,MESI可以保证不需要memory fence指令也可以保证数据的一致性。
1.2. False sharing
False sharing的原因是两个CPU访问的变量,在内存中的位置,同时落入一个cache line范围内,根据MESI协议,一个CPU写操作,将导致另一个CPU的读写操作之前,需要进行memory及两个CPU的cache line同步操作。通常发生在两个线程操作同一个数据结构体的时候。

#define CACHE_ALIGN_SIZE 64
#define CACHE_ALIGNED __attribute__((aligned(CACHE_ALIGN_SIZE)))
struct aligned_value {
int64_t val;
} CACHE_ALIGNED; // Note: aligning the struct to a cache line size
aligned_value aligned_data[2] CACHE_ALIGNED;
// sizeof(aligned_value) == 128
1.3. 现代CPU上MESI的局限
由于MESI同步协议导致处理器之间同步的代价很高,现代处理器再每个core里面增加两个异步队列: store buffer和invalidate queue来减少CPU的空闲等待。这两个异步队列,导致MESI协议失效。
-
store buffer:CPU将write/store操作数据放入store buffer,cache负责flush操作。 -
invalidate queue:cache收到Invalidate消息,不是马上执行,而是放入invalidate queue,等待CPU空闲时,再执行。
注意:
Store Buffer/Load Buffer在硬件中并不是简单的 FIFO 队列,而是具有调度逻辑的结构(类似 CAM — Content Addressable Memory),支持乱序发射、乱序完成。Intel 官方手册称之为 “Memory Ordering Buffer”,ARM 架构称之为 “Load-Store Queue (LSQ)”。但即使内部结构支持乱序,x86 TSO 模型仍然保证 Store Buffer 按程序顺序提交到 cache(FIFO 语义),这是 x86 强内存模型的关键。
其原因是:针对发起方CPU,其认为自己的store / invalidate操作已经完成,但是由于数据/消息是放在store buffer / invalidate queue中,所以可能还没来得及被其他CPU看到,导致数据不一致。
其中的一个解决办法是:发起方的store buffer被清空,接收方的invalidate queue被处理掉。在此之后,MESI协议可以正常工作。
1.4. 补充:CPU指令流水线
1. Fetch <-- ✅ 顺序取指,从指令缓存中取出下一条指令
2. Decode <-- 顺序解码,分析操作数和目的寄存器
3. Rename <-- 寄存器重命名
4. Dispatch <-- 投递到调度窗口,等待执行条件满足
5. Execute <-- ✅ 乱序执行(由调度器决定),实际在执行单元上运行指令
6. Writeback <-- 写结果到 ROB
7. Commit <-- ✅ 按程序顺序提交(retire),更新寄存器状态或进行内存写入
2. memory barrier
2.1. 概念及理论
- 同步点:针对同一个
原子变量的load操作与store操作,分别构成一个同步点。其概念有三要素:(1):load/store操作,(2):针对同一个原子变量,(3):以及在不同线程中; -
synchronize-with关系,该概念包含两个含义:(1):同一个同步点,(2):读取的值是另一个同步点写入的值; -
happens-before关系;
memory fence定义的是同步点操作,即分别在store一方插入一个write barrier指令,在load一方插入一个read barrier指令。因此,memory barrier需要成对出现,否则达不到同步效果。
所谓同步点只是语义上的概念,实际实现中,
memory barrier指令并不直接作用于某个特定的变量,而是通过屏障指令的执行来保证之前/之后的所有内存操作(针对任何变量)满足特定的顺序和可见性要求。
2.2. 详细解释
由于多核处理器 CPU 之间独立的L1/L2 cache,会出现cache line不一致的问题,为了解决这个问题,有相关协议模型,比如 MESI 协议来保证 cache 数据一致,同时由于 CPU 对 MESI 进行的异步优化,对写和读分别引入了「store buffer」和「invalid queue」,很可能导致后面的指令查不到前面指令的执行结果(各个指令的执行顺序非代码执行顺序),这种现象很多时候被称作「CPU乱序执行」。
为了解决乱序问题(也可以理解为可见性问题,修改完没有及时同步到其他的CPU),又引出了「内存屏障」的概念;内存屏障可以分为三种类型:写屏障,读屏障以及全能屏障(包含了读写屏障),屏障可以简单理解为:在操作数据的时候,往数据插入一条特殊的指令。只要遇到这条指令,那前面的操作都得「完成」。
-
写屏障指令(write barrier, orsfence),等待之前的写操作完成,并把该指令「之前」存在于「store Buffer」中的所有写指令刷入cache。就可以让CPU修改的数据马上暴露给其他CPU(MESI),达到「写操作」可见性的效果。 -
读屏障指令(read barrier, orlfence),会把该指令「之前」存在于「invalid queue」中的所有的指令都处理掉。通过这种方式就可以确保当前CPU的缓存状态是准确的,达到「读操作」一定是读取最新的效果。
由于不同CPU架构的缓存体系不一样、缓存一致性协议不一样、重排序的策略不一样、所提供的内存屏障指令也有差异,所以一些语言c++/java/go/rust 都有实现自己的内存模型, 比如golang大牛Russ Cox写的内存模型系列文章 Memory Models 值得深入了解。
2.3. x86上面的fence实操演示
ARM架构CPU有Store Buffer、Invalidate Queue,是一个松散内存一致性模型。x86架构只有Store Buffer,是一个强内存一致性模型。
在x86架构下,对StoreLoad操作进行重排(乱序)。其余几种保持顺序:StoreStore, LoadLoad, LoadStore,即不需要设置fence指令也可以保持CPU之间的内存一致性。
禁止编译器重排:
X = 1;
asm volatile("" ::: "memory"); // Prevent compiler reordering
r1 = Y;
禁止编译器及CPU重排:
X = 1;
asm volatile("mfence" ::: "memory"); // Prevent compiler and CPU reordering
r1 = Y;
详细知识参考:
- CPU 缓存一致性与内存屏障
- Cache一致性和内存一致性
- Acquire and Release Fences
- 從硬體觀點了解 memory barrier 的實作和效果
- CPU架构和MESI缓存一致性->内存模型一致性->内存屏障和原子操作->内存序->C++内存序
3. C++11 内存一致性模型定义
| 内存序 | 语义 | x86-64 实现 | ARM64 实现 |
|---|---|---|---|
| relaxed | 只保证原子性,不保证顺序 | 普通 MOV | 普通 LDR/STR |
| acquire (load) | Acquire操作之后的读/写不能重排到此操作之前,Acquire操作之后的读操作能看到Release线程的Release操作之前的写入 | 普通 MOV + 编译器屏障 | LDAR |
| release (store) | Release操作之前的读/写不能重排到此操作之后,Release操作之前的写操作对Acquire线程可见 | 普通 MOV + 编译器屏障 | STLR |
| acq_rel (RMW) | 同时具有 acquire 和 release 语义 | LOCK 前缀指令(隐含全屏障) | LDAXR/STLXR |
| seq_cst | 全局唯一顺序一致性,所有线程看到相同的 seq_cst 操作顺序 | store: XCHG 或 MOV+MFENCE; load: MOV | LDAR/STLR (+ 额外屏障) |
- 关键认知:C++ 内存序是语言层面的抽象,其硬件实现因架构而异。
Release/Aquire语义要保证happens-before关系,所以Release同时约束前面的读以及写操作不能重排到Release store之后。Acquire同时约束后面的读以及写操作不能重排到Acquire load之前。
acq_rel则同时添加了 acquire 和 release 语义,适用于 read-modify-write 操作(如 fetch_add、compare_exchange)。相当于:
load(memory_order_acquire);
modify();
store(memory_order_release);
acq_rel 约束本线程中前面的读写操作重排到此操作之前,后面的读写操作重排到此操作之后。且可以看见其他线程在 release 操作之前的写入,另外,其他线程在 acquire 操作之后的读取也能看到本线程Release之前的写入。
seq_cst 提供所有线程的一致性,用于多生产-多消费场景,即多线程、多个atomic变量,保证全局顺序一致性。
- 在
x86 TSO(Total Store Order)模型下,硬件已经保证了LoadLoad、LoadStore、StoreStore顺序,只允许StoreLoad重排。因此acquire和release在x86上不需要任何硬件屏障指令,只需编译器屏障(asm volatile("" ::: "memory"))来阻止编译器重排。 - 在
ARM弱内存模型下,所有四种重排都可能发生,因此需要显式的硬件指令(LDAR/STLR/DMB)。 -
seq_cst在x86上需要额外处理StoreLoad重排:编译器在store端使用XCHG(隐含 LOCK)或MOV + MFENCE,load端使用普通MOV。
参见:https://www.felixcloutier.com/x86/sfence,https://www.felixcloutier.com/x86/lfence,https://www.felixcloutier.com/x86/mfence。
3.1. release/acquire 如何实现局部同步
release/acquire 提供的是成对的、局部的同步关系:当线程 B 的 acquire load 读到线程 A 的 release store 写入的值时,线程 A 在 release store 之前的所有写入,对线程 B 在 acquire load 之后的所有读取都可见。
概念层面:
Thread A (producer): Thread B (consumer):
data = 42; while (!(p = flag.load(acquire)));
str = "Hello"; // 以下读取能看到 Thread A 在 release 之前的所有写入
flag.store(true, release); ──→ assert(data == 42); // ✅ 保证成立
↑ assert(*p == "Hello"); // ✅ 保证成立
|
└── release 保证:之前的写入(data, str)
不会被重排到此 store 之后
示例代码:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr{nullptr};
int data{42};
void producer() {
std::string* p = new std::string("Hello");
data = 42;
ptr.store(p, std::memory_order_release);
}
void consumer() {
std::string* p2;
while (nullptr == (p2 = ptr.load(std::memory_order_acquire)));
assert(*p2 == "Hello"); // never fires
assert(data == 42); // never fires
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
return 0;
}
x86-64 编译器实际生成的汇编(GCC/Clang):
;; release store (x86-64)
;; ptr.store(p, std::memory_order_release); (ptr 是 std::atomic<std::string*>)
mov QWORD PTR ptr[rip], rax ; 普通 MOV 指令!
; x86 TSO 已保证 StoreStore 顺序
; 编译器只需确保不重排(编译器屏障)
;; acquire load (x86-64)
;; std::string* p = ptr.load(std::memory_order_acquire);
mov rax, QWORD PTR ptr[rip] ; 普通 MOV 指令!
; x86 TSO 已保证 LoadLoad、LoadStore 顺序
ARM64 编译器生成的汇编(GCC/Clang):
;; release store (ARM64)
;; ptr.store(p, std::memory_order_release); (ptr 是 std::atomic<std::string*>)
stlr x0, [x1] ; Store-Release 指令(64位指针用 x 寄存器)
; 硬件保证:之前的读写不会重排到此 store 之后
;; acquire load (ARM64)
;; std::string* p = ptr.load(std::memory_order_acquire);
ldar x0, [x1] ; Load-Acquire 指令(64位指针用 x 寄存器)
; 硬件保证:之后的读写不会重排到此 load 之前
从硬件角度理解 release/acquire 的作用:
Release Store 的效果:
┌──────────────────────────────┐
│ 之前的所有 store 已经进入 │
│ Store Buffer(x86: FIFO │
│ 保证顺序提交到 cache) │
├──────────────────────────────┤
│ Release Store 本身 │ ← 保证在之前的 store 之后可见
└──────────────────────────────┘
x86: Store Buffer 是 FIFO,天然保证 StoreStore 顺序
ARM: STLR 指令包含隐式屏障,阻止重排
Acquire Load 的效果:
┌──────────────────────────────┐
│ Acquire Load 本身 │ ← 此时可能触发 cache miss,
│ │ 从其他 CPU 的 cache 获取最新值
├──────────────────────────────┤
│ 之后的 load/store │ ← 保证在 acquire load 之后执行
│ 能看到 release 之前的写入 │
└──────────────────────────────┘
x86: 硬件已保证 LoadLoad/LoadStore 顺序,Invalidate Queue 中的
失效消息在 load 前被处理(x86 不真正延迟处理 invalidation)
ARM: LDAR 指令包含隐式屏障,且强制处理 Invalidate Queue
3.2. memory_order_seq_cst 如何实现全局同步
seq_cst 比 release/acquire 更强:它提供一个全局唯一的操作顺序(single total order),所有线程看到的 seq_cst 操作顺序完全一致。
x86-64 编译器实际生成的汇编(GCC/Clang):
;; seq_cst store (x86-64)
;; ptr.store(p, std::memory_order_seq_cst); (ptr 是 std::atomic<std::string*>)
xchg rax, QWORD PTR ptr[rip] ; XCHG 隐含 LOCK 前缀(64位指针用 QWORD/rax)
; 效果:
; 1. 排空 Store Buffer(之前的 store 全部提交)
; 2. 原子地写入新值
; 3. 等待本次写入被其他 CPU 的 cache 确认(ACK)
; 4. 隐含全屏障(相当于 MFENCE)
;; 或者等价写法:
mov QWORD PTR ptr[rip], rax ; 普通 store
mfence ; 排空 Store Buffer + 阻止 StoreLoad 重排
s
;; seq_cst load (x86-64)
;; std::string* p = ptr.load(std::memory_order_seq_cst);
mov rax, QWORD PTR ptr[rip] ; 普通 MOV 指令!(64位指针用 QWORD/rax)
; ⚠️ 注意:x86 上 seq_cst load 不需要 MFENCE
; 因为屏障已经放在 store 端,而 x86 TSO 保证
; load 不会越过之前的 load(LoadLoad 有序)
ARM64 编译器生成的汇编(GCC/Clang):
;; seq_cst store (ARM64)
;; ptr.store(p, std::memory_order_seq_cst); (ptr 是 std::atomic<std::string*>)
stlr x0, [x1] ; Store-Release(64位指针用 x 寄存器,与 release 相同指令)
; ARMv8 中 STLR+LDAR 组合天然提供 seq_cst 语义
;; seq_cst load (ARM64)
;; std::string* p = ptr.load(std::memory_order_seq_cst);
ldar x0, [x1] ; Load-Acquire(64位指针用 x 寄存器,与 acquire 相同指令)
为什么 x86 的 seq_cst 把屏障放在 store 端而不是 load 端?
在 x86 TSO 下,唯一允许的重排是 StoreLoad(后面的 load 可能在前面的 store 提交到 cache 之前就执行了)。因此只需要在 store 之后 / load 之前插入屏障。编译器选择在 store 端处理,使用 XCHG(隐含 LOCK)或 MOV + MFENCE,这样 load 端可以保持为普通 MOV 指令,性能更好(因为 load 通常比 store 更频繁)。
关键差异:
Release Store(局部同步,成对使用):
-----------------------------------------
CPU 0: store data=42 ; 进入 Store Buffer
store flag=true ; release store,也进入 Store Buffer
; x86 FIFO 保证 data 先于 flag 提交
↓ cache coherence (MESI)
CPU 1: load flag (acquire) ; 如果读到 true,
load data ; 则保证读到 42
Seq_cst Store(全局同步,强制唯一顺序):
-----------------------------------------
CPU 0: XCHG [x], 1 ; 隐含 LOCK 前缀
↓
1. 排空 Store Buffer(之前所有 store 提交到 cache)
2. 锁定 cache line,原子写入
3. 通过 MESI 发送 Invalidate 消息
4. 等待所有 CPU 的 Invalidate ACK
↓
此时所有 CPU 都知道 x 已经被修改
↓
CPU 1,2,3: 后续的 seq_cst load
必须看到一致的全局顺序
3.3. release/acquire 与 seq_cst 的本质区别:IRIW 问题
release/acquire 只提供成对的局部同步,不保证全局顺序。经典的 IRIW(Independent Reads of Independent Writes) 问题展示了这一区别:
std::atomic<int> x{0}, y{0};
// Thread 1: 只写 x
void thread1() { x.store(1, memory_order); }
// Thread 2: 只写 y
void thread2() { y.store(1, memory_order); }
// Thread 3: 先读 x,再读 y
void thread3() {
int r1 = x.load(memory_order); // 读到 1
int r2 = y.load(memory_order); // 读到 0
}
// Thread 4: 先读 y,再读 x
void thread4() {
int r3 = y.load(memory_order); // 读到 1
int r4 = x.load(memory_order); // 读到 0
}
| memory_order | r1=1, r2=0, r3=1, r4=0 是否可能? | 原因 |
|---|---|---|
acquire/release | ✅ 可能 | 没有全局顺序要求;Thread 3 和 Thread 4 可能各自看到不同的写入顺序 |
seq_cst | ❌ 不可能 | 全局唯一顺序:如果 Thread 3 看到 x=1 在 y=1 之前,Thread 4 也必须看到相同的顺序 |
这就是 seq_cst 的额外开销所换来的保证:所有线程对所有 seq_cst 操作看到完全相同的执行顺序。
4. 原子操作的硬件实现
上面讨论的 memory order 解决的是可见性和顺序问题。而原子操作本身要解决的是不可分割性(atomicity) 问题——确保一个操作在观察者看来要么完全完成,要么完全没有发生。
4.1. 原子性的基础:自然对齐的 load/store
在大多数现代 CPU 上,自然对齐的基本类型(≤ 机器字长)的 load 和 store 天然就是原子的:
x86-64:
- 对齐的 1/2/4/8 字节 load/store 是原子的
- 即使是普通的 MOV 指令,只要地址对齐,就是原子操作
- 这就是为什么 relaxed load/store 在 x86 上就是普通 MOV
ARM64:
- 对齐的 1/2/4/8 字节 LDR/STR 是原子的
因此,std::atomic<int> 的 load() 和 store() 本质上不需要特殊的硬件支持来保证原子性——对齐的 MOV/LDR/STR 天然就是原子的。std::atomic 在这里主要提供的是编译器屏障和内存序语义。
std::atomic(即使 relaxed)与普通变量的区别
即使使用最弱的 memory_order_relaxed,std::atomic 仍然比普通变量多做了关键的几件事:
| 特性 | 普通变量 | atomic(relaxed) |
|---|---|---|
| 操作原子性 | 不保证(可能被拆分为多条指令) | 保证不可分割 |
| 编译器优化 | 可合并、删除、重排 | 禁止合并/删除(每次操作都会发出指令) |
| cache coherence | 可能一直停留在寄存器中 | 触发 MESI 的 invalidate,保证跨核可见性 |
| 顺序保证 | 无 | 不保证顺序(relaxed),但保证最终可见 |
// 普通变量:编译器可能优化掉前一条
int x;
x = 42;
x = 43; // 编译器可能直接只保留 x = 43
// atomic:每条 store 都必须执行
std::atomic<int> x;
x.store(42, std::memory_order_relaxed); // 不会被优化掉
x.store(43, std::memory_order_relaxed); // 也不会被优化掉
关键理解:
atomic的”原子性”和”内存序”是两个独立的概念。relaxed只放弃了顺序保证,但原子性、编译器屏障(禁止优化)、cache coherence 触发一个都不少。
4.2. Read-Modify-Write (RMW) 操作
真正需要特殊硬件支持的是 RMW 操作:fetch_add、compare_exchange、exchange 等。这些操作需要在”读取-计算-写入”这个过程中保证没有其他 CPU 插入修改。
x86 实现:LOCK 前缀
;; std::atomic<int> x; x.fetch_add(1, relaxed);
lock add DWORD PTR [rdi], 1 ; LOCK 前缀保证原子 Read-Modify-Write
;; x.compare_exchange_strong(expected, desired);
lock cmpxchg DWORD PTR [rdi], esi ; LOCK + CMPXCHG = 原子 CAS
;; x.exchange(val);
xchg DWORD PTR [rdi], esi ; XCHG 隐含 LOCK(不需要显式写)
以
lock cmpxchg为例,它在硬件中不是拆成多条独立微指令,而是作为一组融合微操作(fused micro-op) 执行:CPU 在执行期间锁定资源,保证”比较-交换”整个过程不可被打断。具体流程:(1) 发出 LOCK# 信号或锁住 cache line → (2) 通过 MESI 抢占独占权限 → (3) 等待其他核 invalidation ACK → (4) 比较并条件写入 → (5) 完成后更新 MESI 状态为 Modified。
LOCK 前缀的硬件实现(现代 x86):
┌──────────────────────────────────────────────────┐
│ 1. 检查目标地址是否在 L1 Cache 中 │
│ ├─ 是 → Cache Line Locking(锁定 cache line) │
│ │ - 将 cache line 设为 Modified 状态 │
│ │ - 在操作期间拒绝其他 CPU 的访问请求 │
│ │ - 操作完成后释放 │
│ └─ 否 → Bus Locking(锁定总线,较慢) │
│ - 发出 LOCK# 信号 │
│ - 阻止其他 CPU 访问内存 │
│ - 现代 CPU 极少走到这条路径 │
├──────────────────────────────────────────────────┤
│ 2. 额外效果: │
│ - LOCK 前缀指令隐含全内存屏障(等同 MFENCE) │
│ - 排空 Store Buffer │
│ - 即使使用 memory_order_relaxed, │
│ x86 上的 RMW 也有 MFENCE 效果 │
└──────────────────────────────────────────────────┘
重要: x86 上
LOCK前缀指令始终隐含全屏障。这意味着x.fetch_add(1, relaxed)在 x86 上的性能和x.fetch_add(1, seq_cst)几乎相同——都会生成lock add。relaxed 的性能优势主要体现在 ARM 等弱内存模型架构上。
ARM 实现:LL/SC 或 LSE 原子指令
;; fetch_add (ARM64, 传统 LL/SC 方式)
.retry:
ldxr w1, [x0] ; Load-Exclusive:加载值并标记为"独占"
add w2, w1, #1 ; 计算新值
stxr w3, w2, [x0] ; Store-Exclusive:仅当独占标记仍有效时写入
cbnz w3, .retry ; 如果 stxr 失败(其他 CPU 写了同一 cache line),重试
;; fetch_add (ARM64, ARMv8.1 LSE 原子指令)
ldadd w1, w0, [x0] ; 硬件原子 load-add,无需重试循环
LL/SC(Load-Linked / Store-Conditional)机制:
┌───────────────┐ ┌───────────────┐
│ CPU 0 │ │ CPU 1 │
│ │ │ │
│ LDXR [addr] │ │ │
│ ↓ 标记 addr │ │ │
│ 为 exclusive │ │ │
│ │ │ STR [addr] │
│ │ │ ↓ 清除 CPU0 │
│ │ │ 的 exclusive │
│ │ │ 标记 │
│ STXR [addr] │ │ │
│ ↓ 发现标记 │ │ │
│ 已被清除 │ │ │
│ → 返回失败 │ │ │
│ → 跳回 LDXR │ │ │
│ 重试 │ │ │
└───────────────┘ └───────────────┘
4.3. 三种内存序对 RMW 的影响(以 fetch_add 为例)
;; x86-64: 三种内存序生成的汇编完全相同!
;; x.fetch_add(1, relaxed / acq_rel / seq_cst)
lock add DWORD PTR [rdi], 1 ; 都是 lock add(LOCK 隐含全屏障)
;; ARM64: 不同内存序生成不同汇编
;; relaxed:
ldxr w1, [x0]
add w2, w1, #1
stxr w3, w2, [x0] ; 普通 LL/SC
;; acquire-release:
ldaxr w1, [x0] ; Load-Acquire-Exclusive
add w2, w1, #1
stlxr w3, w2, [x0] ; Store-Release-Exclusive
;; seq_cst:
ldaxr w1, [x0] ; Load-Acquire-Exclusive
add w2, w1, #1
stlxr w3, w2, [x0] ; Store-Release-Exclusive
dmb ish ; 额外的全屏障(某些实现)
4.4. 总结对比
┌──────────────┬─────────────────┬─────────────────────────┬────────────────────┐
│ 操作类型 │ 保证什么 │ x86-64 实现 │ ARM64 实现 │
├──────────────┼─────────────────┼─────────────────────────┼────────────────────┤
│ relaxed │ 原子性 │ MOV │ LDR/STR │
│ load/store │ │ │ │
├──────────────┼─────────────────┼─────────────────────────┼────────────────────┤
│ acquire │ 原子性 + │ MOV(编译器屏障) │ LDAR │
│ load │ 后续操作不前移 │ │ │
├──────────────┼─────────────────┼─────────────────────────┼────────────────────┤
│ release │ 原子性 + │ MOV(编译器屏障) │ STLR │
│ store │ 之前操作不后移 │ │ │
├──────────────┼─────────────────┼─────────────────────────┼────────────────────┤
│ seq_cst │ 原子性 + │ store: XCHG/MOV+MFENCE │ LDAR/STLR │
│ load/store │ 全局唯一顺序 │ load: MOV │ (+ 可能额外 DMB) │
├──────────────┼─────────────────┼─────────────────────────┼────────────────────┤
│ RMW │ 原子性 + │ LOCK 前缀指令 │ LDXR/STXR │
│ (any order) │ 不可分割的 │ (始终隐含全屏障) │ 或 LSE 原子指令 │
│ │ 读-改-写 │ │ (屏障取决于 order) │
└──────────────┴─────────────────┴─────────────────────────┴────────────────────┘
参考资料
更多资料
Enjoy Reading This Article?
Here are some more articles you might like to read next: