Intel TBB 并行计算
1. TBB 简介
Intel TBB主要功能模块:
- 并行算法
- 任务调度
- 并行容器
- 同步原语
- 内存分配器
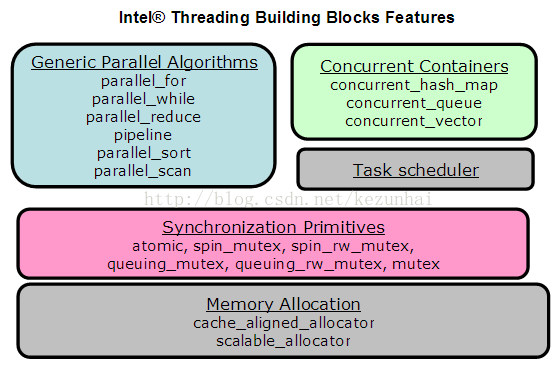
1.1. 并行算法
- parallel_for
- parallel_reduce
- parallel_scan
- parallel_do
- parallel_sort
- parallel_invoke
- pipeline, parallel_pipeline
1.2. 并行容器
concurrent_vectorconcurrent_hash_mapconcurrent_queue
1.3. 编译及链接
参考之前文档Intel TBB malloc 使用 (windows)(2024-08-13)。
2. 并行计算
头文件包含:
#include <oneapi/tbb/parallel_sort.h>
#include <tbb/parallel_for.h>
#include <tbb/tbb.h>
2.1 sort
std::vector<dataxy_info_t> data_xy_info;
//...
tbb::parallel_sort(data_xy_info.begin(), data_xy_info.end(),
[](const dataxy_info_t& a, const dataxy_info_t& b) { return (a.x_ < b.x_); });
对150万数据排序,时间对比:
[2024-08-28 12:44:37.924] [info] 02. Sorted 1503894 samples in 80.45 ms (TBB sort)
[2024-08-28 12:44:42.610] [info] 11. Sorted 1503894 samples in 206.20 ms (std sort)
2.2 parallel_for_each
// void parse_dataxy_info(dataxy_info_t& info);
tbb::parallel_for_each(data_xy_info.begin(), data_xy_info.end(), parse_dataxy_info);
2.3. 任务分块:blocked_range 以及 partitioner
分块是通过分区(partitioner)和粒度(grainsize)控制的。Intel TBB定义了几种partitioner,即不同的分区策略,不同分区策略对grainsize的控制有所不同。默认使用auto_partitioner。
blocked_range的构造函数形式为:blocked_range<T>(begin,end,grainsize)。结合使用blocked_range以及partitioner,如下是不同分区策略的一些区别:
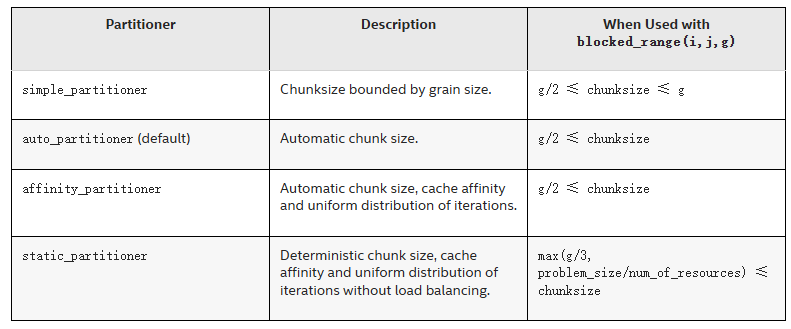
使用auto_partitioner以及affinity_partitioner,会根据执行情况调整每个线程的负载,可能会有一些额外开销,static_partitioner则不会在执行过程中调整线程的负载,可能会有一些负载不均的情况。
2.3.1 affinity_partitioner
affinity_partitioner除了自动选择grainsize(粒度)之外,还会记录每个线程处理的数据块,以便在后续的parallel_for等并行算法中优先分配给同一线程,减少数据迁移,提高缓存命中率。对于内存数据需要重复访问的情况,affinity_partitioner尤其有用。
如下图示中,上半部分显示一个线程加载并处理一块数据,以及对应的Cache区域。下半部分示意两个线程处理的内存区域有重叠,即Cache区域有重叠。如果内存重叠区域的线程都有回写的需求,可能会出现False Sharing或者叫Cache Coherence Traffic,导致线程1的Cache被线程2逐出导致Cache Miss。
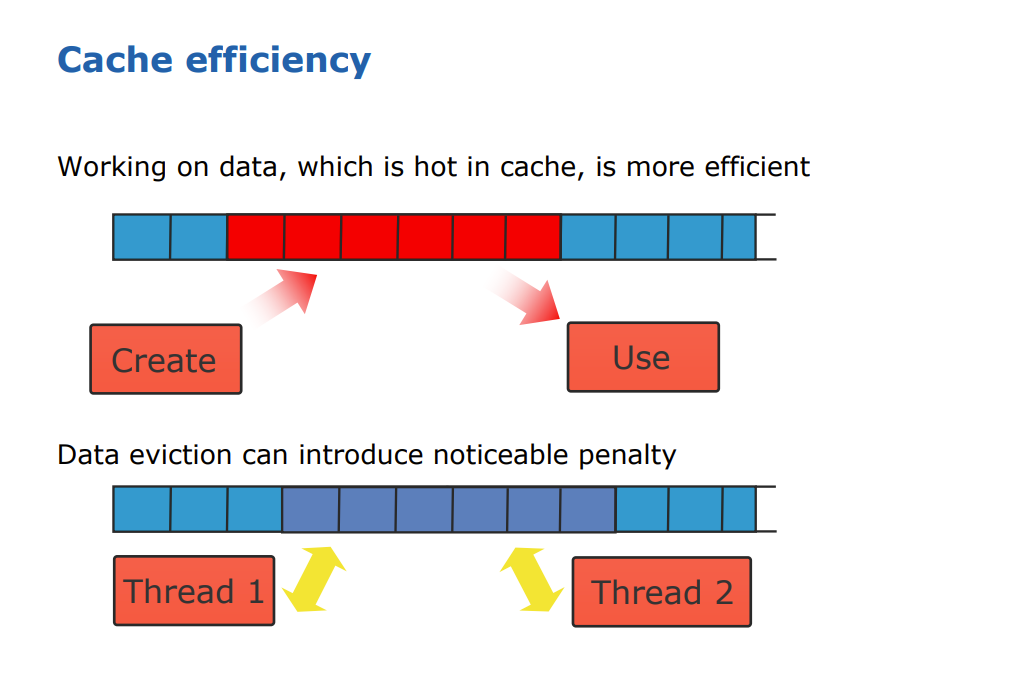
相关官方文档:
2.3.2 示例:基于分块的 parallel_for
如果需要使用到任务共享写变量,需要添加锁,或者使用原子变量,如下面示例中使用到的原子变量。
TBB不保证线程安全。
{
std::atomic_int overflow_acc{}, underflow_acc{};
auto statistic_abnormal_func = [&](const sample_data_t& sample) { // func body: 统计异常数据
if (sample.mapped_pos_.y_ < 0) {
underflow_acc++;
} else if (sample.mapped_pos_.y_ > 255) {
overflow_acc++;
}
};
tbb::parallel_for(
tbb::blocked_range<size_t>(0, ds.ds_.size()),
[&](const tbb::blocked_range<size_t>& r) {
for (size_t i = r.begin(); i != r.end(); i++) {
statistic_abnormal_func(ds.ds_[i]);
}
},
tbb::auto_partitioner());
if (overflow_acc > 0 || underflow_acc > 0) {
//SPDLOG_WARN("samples overflow {}. underflow {} in dataset", overflow_acc.load(), underflow_acc.load());
samples_overflow_acc2 += overflow_acc.load();
samples_underflow_acc2 += underflow_acc.load();
}
}
2.3.3 示例:基于分块的 parallel_reduce
归并主要用于查找最大值,合并计算(如求和)等场景。其原理如下:
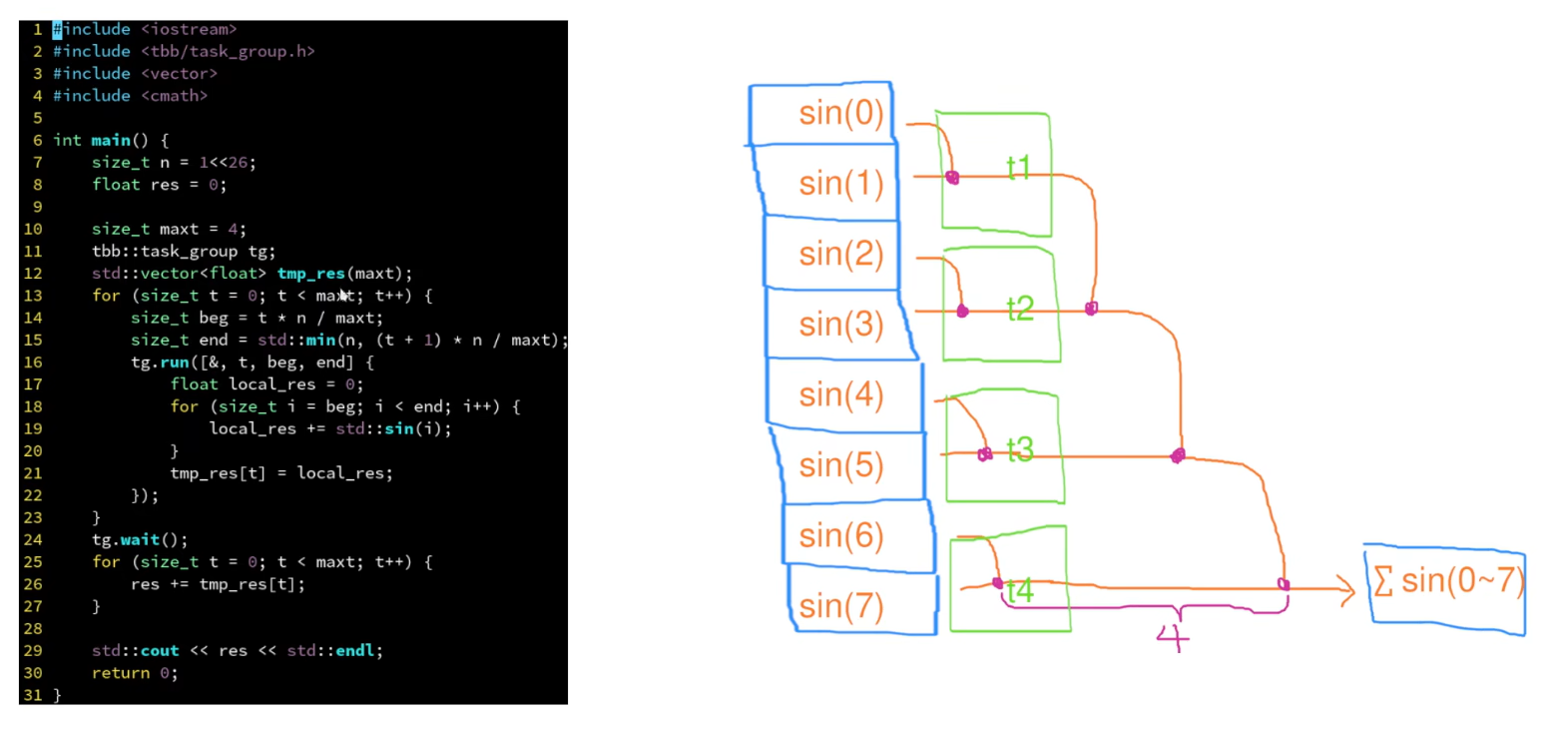
参考资料:intel-TBB使用笔记
3. 任务调度及线程池
针对具体并行任务,设定并行度,使用task_arena。需要设置全局并行度的,使用global_control。
3.1 task_arena
#include <oneapi/tbb/info.h>
#include <oneapi/tbb/parallel_for.h>
#include <oneapi/tbb/task_arena.h>
#include <cassert>
oneapi::tbb::task_arena arena(4); // 4 threads
arena.execute([] {
oneapi::tbb::parallel_for( /* ... */ [] {
// This arena is limited with for threads
assert(oneapi::tbb::this_task_arena::max_concurrency() == 4);
});
});
3.2 global_control
#include <oneapi/tbb/info.h>
#include <oneapi/tbb/task_arena.h>
#include <oneapi/tbb/global_control.h>
#include <cassert>
oneapi::tbb::global_control global_limit(oneapi::tbb::global_control::max_allowed_parallelism, 2);
// the default parallelism
oneapi::tbb::parallel_for( /* ... */ [] {
// No more than two threads is expected; however, tbb::this_task_arena::max_concurrency() can return a bigger value
int thread_limit = oneapi::tbb::global_control::active_value(oneapi::tbb::global_control::max_allowed_parallelism);
assert(thread_limit == 2);
});
3.3 设置并行线程 Stack Size
#include <oneapi/tbb/global_control.h>
oneapi::tbb::global_control global_limit(tbb::global_control::thread_stack_size, 16 * 1024 * 1024);
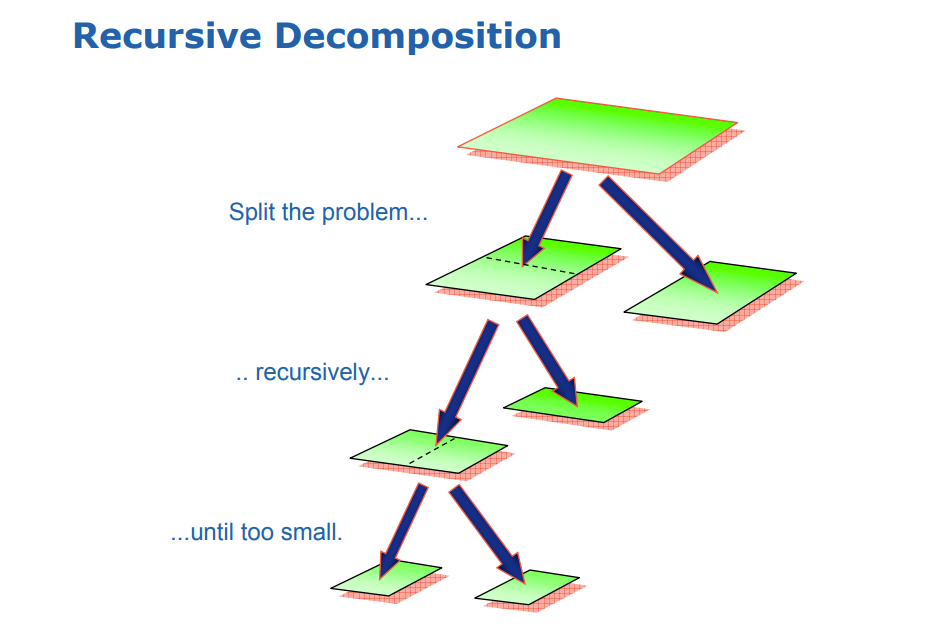
4. TBB原理:任务划分
TBB采用递归分块的方式划分Task,直到任务足够小(小于grainsize)时才执行。如下图所示:
在执行时,按照深度优先的顺序执行Task,以获取最大的局部性和缓存效率。另一方面在,在负载均衡调整的过程中,Work Steal则采样广度优先的方式,以避免与被Steal的线程Cache冲突。如下图所示:
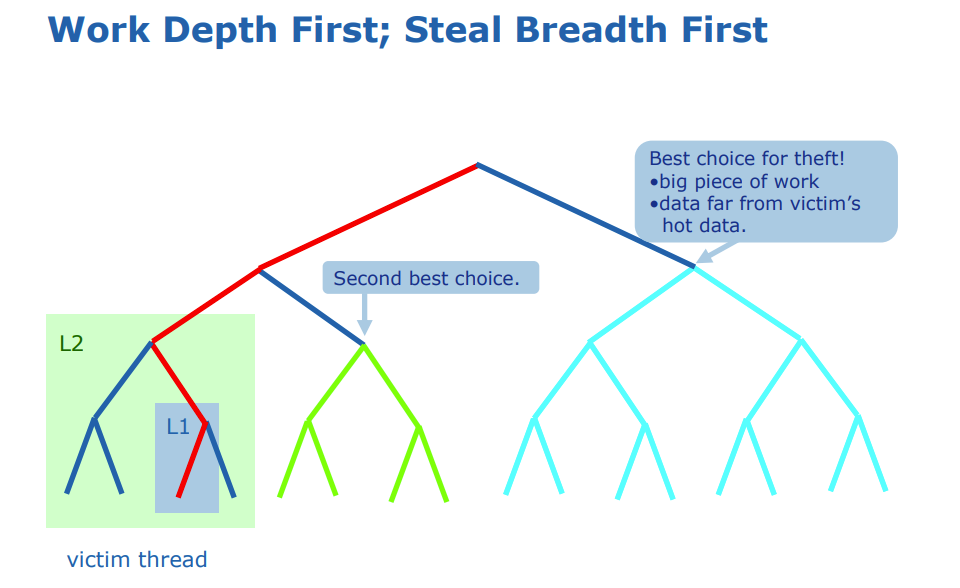
资料:PPT–Parallel Programming with Intel® Threading Building Blocks
A. 资料
- TBB并发库代码学习:博客,介绍了一些内部实现
- Intel Thread Building Blocks (TBB):中文博客,其中任务调度讲解比较好
- Pro TBB:Pro TBB 代码示例
- Intel Community
A.1. 官方文档
Enjoy Reading This Article?
Here are some more articles you might like to read next: