OpenCL 端编程流程及主要概念实践
OpenCL 端编程流程及主要概念实践
0. OpenCL 概念
- 平台 platform:
OpenCL实现的顶层容器,通常对应于一个OpenCL的实现厂商; - 设备 device:执行
OpenCL程序的硬件设备,可以是CPU、GPU、FPGA,或其他计算加速设备; - 上下文 context:管理设备和资源的的环境,
一个上下文可以包括多个 device; - 命令队列 command queue:向设备发送命令的队列,一个命令队列与一个给定的
device相关联; - 程序 program:CL 代码及其编译后的二进制,包含一个或多个
kernel; - 内核 kernel:在设备上执行的函数,这是 OpenCL 程序的核心;
- 工作项 work item:
kernel执行的一个实例,类似于线程; - 工作组 work group:工作项的集合,集合内的 work item 共享一个
Local Memory,以及进行同步;
1. 编程流程
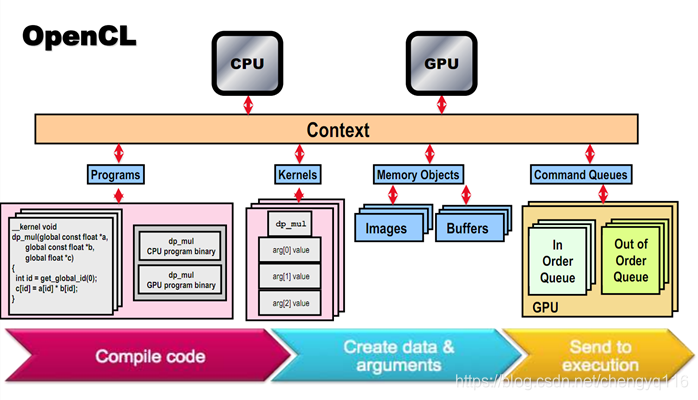
编程步骤如下:

一个示例源码:opencl_002_array_add
2. OpenCL 内存模型
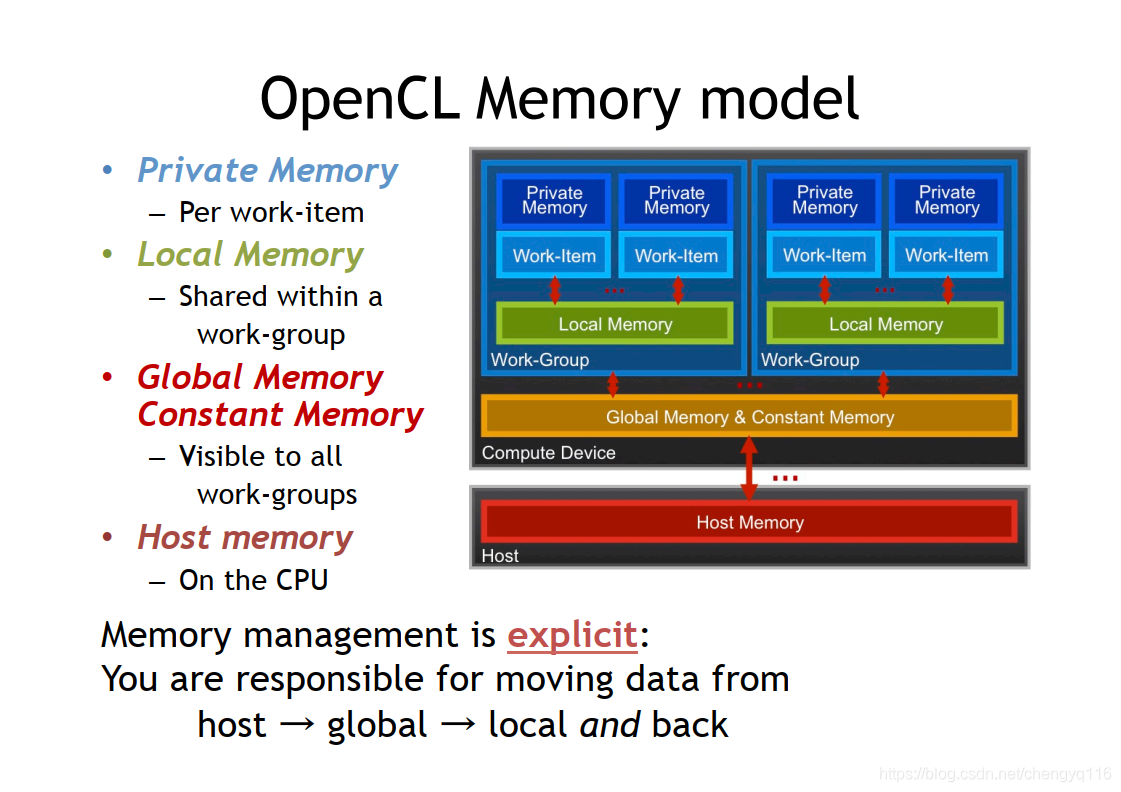
kernel函数中,使用关键字__global标示的变量,存储在上图中的Global Memory中;__local标示的变量,存储在Local Memory中。OpenCL也分WorkGroup,使用__local修饰的变量,存储在Local Memory中,仅限于同一个WorkGroup中的Work Item可以共享访问该变量。kernel函数中定义的变量,存储在Private Memory中,仅限于Work Item内可访问。kernel函数也可以使用值传参,以及指针传参,一般不推荐值传参。
3. 概念解释:work group、work item 与 设置 index
类似于 CUDA 中的 warp 概念以及 thread 概念,OpenCL 中也有 get_global_id() 和 get_local_id() 这两个函数,用来获取当前 work item 的全局和局部索引,用于表示当前任务的index。
使用 clEnqueueNDRangeKernel 时,需要设置维度参数,函数原型如下:
1
2
3
4
5
6
7
8
9
10
11
cl_int clEnqueueNDRangeKernel(
cl_command_queue command_queue, // 命令队列
cl_kernel kernel, // 要执行的内核
cl_uint work_dim, // 工作维度,范围是1到3
const size_t *global_work_offset, // 全局工作项的偏移
const size_t *global_work_size, // 全局工作项的大小
const size_t *local_work_size, // 局部工作项的大小
cl_uint num_events_in_wait_list, // 依赖的事件数量
const cl_event *event_wait_list, // 依赖事件的列表
cl_event *event // 返回的事件
);
work_dim: 工作维度,表示kernel函数的执行次数,可以是 1, 2,3;global_work_offset: 全局工作项的偏移量,可以设为 NULL,表示从 (0,0,0) 开始;global_work_size: 全局工作项的大小,例如对于一个1024x1024的矩阵/图像,设置为(1024, 1024);local_work_size:指定每个work group分配的work item数量;
例如如下代码设置 global_work_size,local_work_size:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
size_t global_work_size[2] = {1024, 1024}; // 1024x1024 的全局工作区
size_t local_work_size[2] = {16, 16}; // 16x16 的局部工作区
// 启动 kernel
cl_int err = clEnqueueNDRangeKernel(
queue,
kernel,
2, // 2 维
NULL, // 全局偏移量设为 NULL
global_work_size,// 全局工作区大小
local_work_size, // 局部工作区大小
0, // 没有依赖的事件
NULL, // 没有依赖的事件列表
NULL // 不需要返回的事件句柄
);
3.1 例子:矩阵转置
work item index 演示代码,测试代码 003_opengl_matrix_transpose。
kernel 部分:
1
2
3
4
5
__kernel void matrixTransposeSimple(__global float* input, __global float* output, const uint width, const uint height) {
uint gdx = get_global_id(0);
uint gdy = get_global_id(1);
output[gdy * width + gdx] = input[gdx * height + gdy];
}
work item index 演示代码 – C++部分代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 5. 准备数据,并创建 cl buffers
Eigen::MatrixXf dst_matrix = Eigen::MatrixXf::Zero(kMatrixSize, kMatrixSize);
Eigen::MatrixXf src_matrix = Eigen::MatrixXf::Random(kMatrixSize, kMatrixSize);
auto src_matrix_ptr = src_matrix.data(), dst_matrix_ptr = dst_matrix.data();
const size_t cl_buff_size = kMatrixSize * kMatrixSize * sizeof(cl_float);
cl_mem clsrc = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, cl_buff_size, src_matrix_ptr, NULL);
cl_mem cldst = clCreateBuffer(context, CL_MEM_READ_WRITE, cl_buff_size, NULL, NULL);
// 6. 设置 kernel 参数,并执行 kernel
cl_int dimx = kMatrixSize, dimy = kMatrixSize;
const auto err1 = clSetKernelArg(kernel, 0, sizeof(cl_mem), &clsrc); // param 0: source matrix
const auto err2 = clSetKernelArg(kernel, 1, sizeof(cl_mem), &cldst); // param 1: destination matrix
const auto err3 = clSetKernelArg(kernel, 2, sizeof(cl_int), &dimx); // param 2: width
const auto err4 = clSetKernelArg(kernel, 3, sizeof(cl_int), &dimy); // param 3: height
size_t global_work_size[] = {kMatrixSize, kMatrixSize}, local_work_size[] = {16, 16};
const auto err6 = clEnqueueNDRangeKernel(queue, kernel, 2, //
0, global_work_size, local_work_size, //
0, 0, 0);
const auto err7 = clFinish(queue);
3.2 如何设置 local_work_size
在kernel中,有如下函数,分别获取指定维度上的local index,group index,global index:
1
2
3
size_t get_global_id(uint D); // 获取全局索引,D=0,1,2
size_t get_local_id(uint D); // 获取局部索引, D=0,1,2
size_t get_group_id(uint D); // 获取组索引,D=0,1,2
使用CL_KERNEL_WORK_GROUP_SIZE获取work group的最大尺寸:
1
2
3
4
size_t max_work_group_size{}, max_work_group_size2{};
clGetKernelWorkGroupInfo(kernel, device, CL_KERNEL_WORK_GROUP_SIZE, sizeof(size_t), &max_work_group_size, NULL);
clGetDeviceInfo(device, CL_DEVICE_MAX_WORK_GROUP_SIZE, sizeof(size_t), &max_work_group_size2, NULL);
SPDLOG_INFO("Max work group size: {} / {}", max_work_group_size, max_work_group_size2); // 输出 256 / 256
在调用clEnqueueNDRangeKernel时,参数local_work_size设置为null,kernel将自动选择合适的local work size。
FIXME:使用clinf 查看 Intel UHD Graphics 620信息,显示推荐的local work size为 8, 16, 32。
4. 参考及资料
本文由作者按照 CC BY 4.0 进行授权