CUDA编程过程中的性能优化
CUDA编程过程中的性能优化
1. 硬件结构
英伟达CUDA/GPU架构演变,以及不同架构的硬件能力:
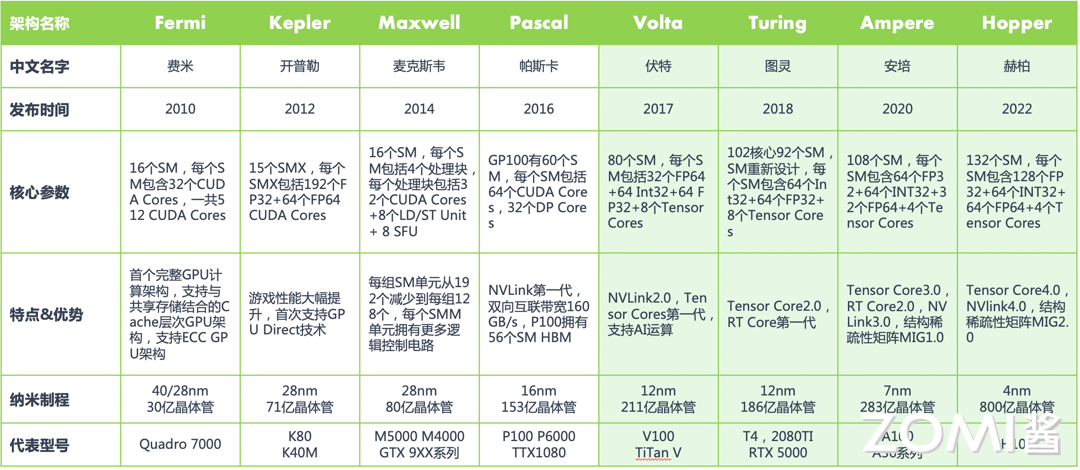
硬件层次结构如下(以Fermi架构为例):
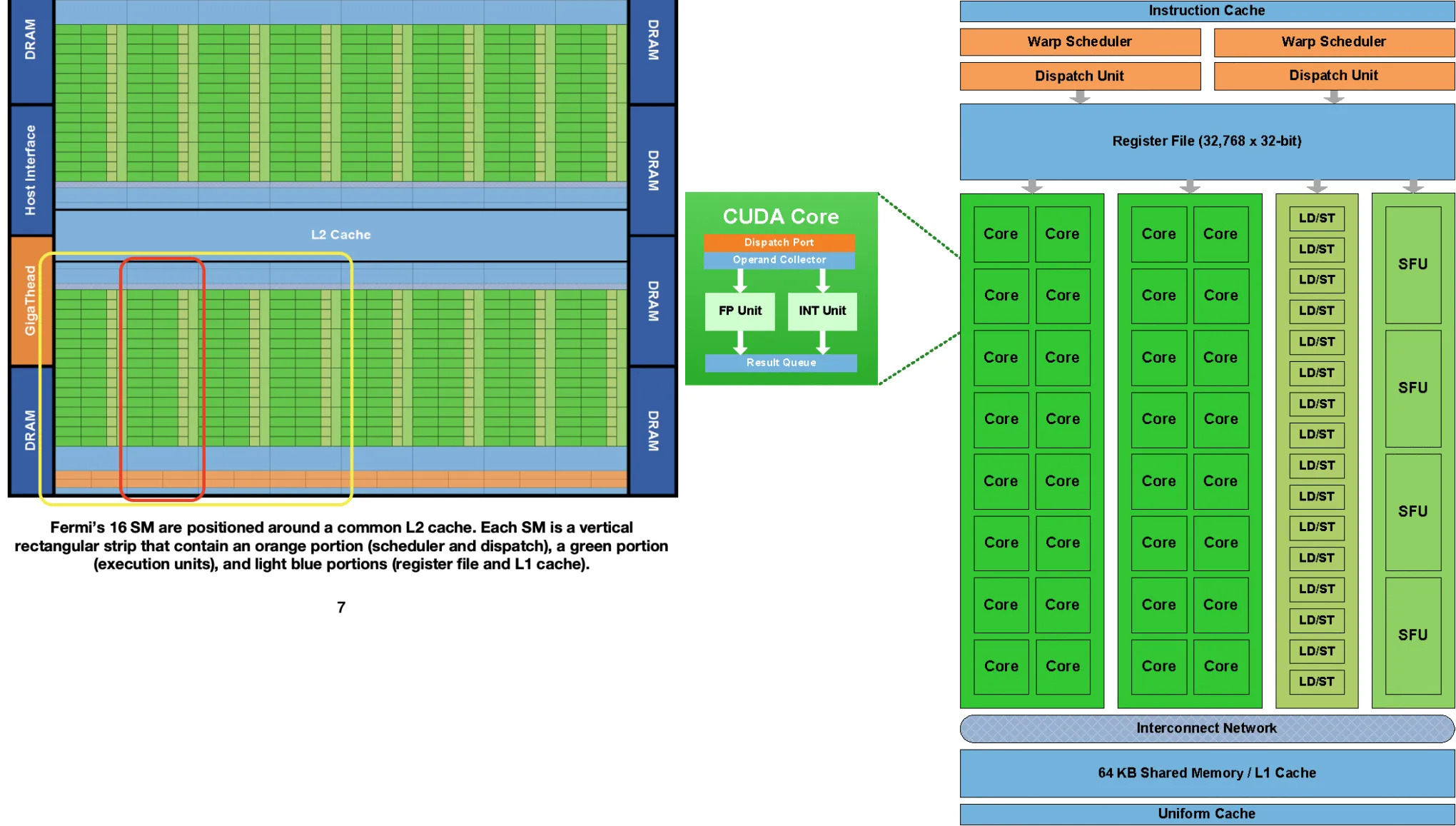
- 一个
GPU中包含若干个SM(Streaming Multiprocessor,流多处理器),对应上图中左边; - 一个
SM中包含32个CUDA Core(也叫SP),对应上图中右边; - 一个
CUDA Core中包含一个ALU,一个FPU。 - 有些
SM中还包含Tensor Core,与CUDA Core协同参与计算。
1.1. 缓存层级
一个CUDA Core内部,包含:
Register File:16K 32-bit寄存器文件;L0 I-Cache
一个SM内部,包含:
Shared Memory:一个SM内部的threads可访问;L1 Cache:一个SM内部的threads可访问;Constant Cache;
整个GPU内部,包含:
L2 Cache:所有SM共享访问;Global Memory:所有SM共享访问。

内存访问速度示意图:
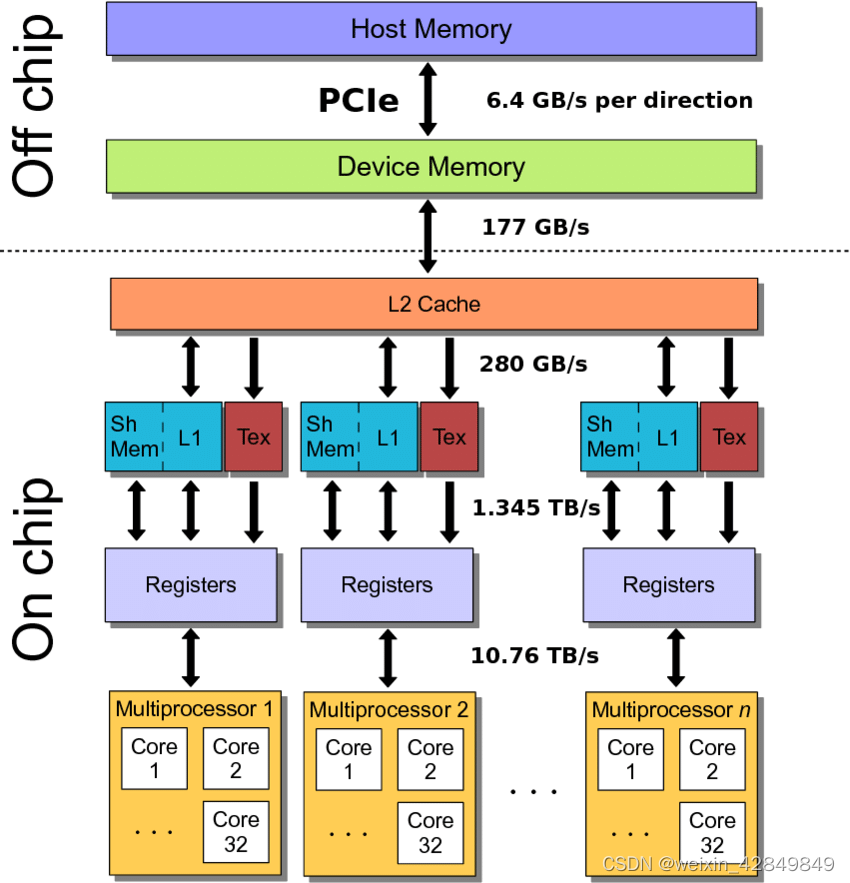
资料:
- CUDA: GPU内存架构示意。文章结尾有一些内存优化相关链接。
- huggingface – The Ultra-Scale Playbook:Training LLMs on GPU Clusters – A primer on GPUs
- 【AI系统】为什么 GPU 适用于 AI
- 英伟达GPU架构总结
2. 编程模型
软件/硬件层次结构对应关系:
| 层级 | 说明 | 硬件对应 |
|---|---|---|
| Grid | 所有要执行的Block的集合 | 整个GPU |
| Block | 一组线程,一起在同一个SM上执行 | 一个SM(流多处理器) |
| Thread | 执行kernel代码的最小单位 | 一个CUDA Core |
代码执行过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
myKernel<<<100, 256>>>(data, n) // 启动kernel
↓ 产生 Grid,包含100个Block
Block 0:
├── Thread 0 执行myKernel
├── Thread 1 执行myKernel
├── ...
└── Thread 255 执行myKernel
Block 1:
├── Thread 0 执行myKernel
├── ...
└── Thread 255 执行myKernel
...(总共100个Block)
在调度时,一个Block中的Theads只会分配到一个SM中执行,如果资源不允许,则需要执行多次调度循环,才能执行完这个Block中的所有Threads。
另一方面,多个Block可以分配到同一个SM中执行。即,如果资源允许,或者当前Block中的Theads由于访问延迟而阻塞时,SM可以调度其他Block中的Threads来执行。(比如一个Warp的寄存器写后读会产生24个时钟延迟,则需要分配24个Warp来掩盖延迟)
1
2
3
4
5
6
同一SM上可运行的Block数量 = min(
⌊最大thread数 / 每个Block的thread数⌋,
⌊共享内存大小 / 每个Block占用的shared memory⌋,
⌊寄存器总数 / (每个thread占用寄存器数 × 每个Block的thread数)⌋,
硬件限制(通常8-16个Block)
)
查看SM资源利用率:
1
2
nvprof --metrics achieved_occupancy ./program
# occupancy = (实际运行的warp数) / (理论最大warp数)
2.1. 索引
| 变量 | 类型 | 说明 |
|---|---|---|
| threadIdx | uint3 | 当前thread在其Block内的索引(0-based) |
| blockIdx | uint3 | 当前Block在Grid中的索引(0-based) |
| blockDim | dim3 | 当前Block的维度/大小(thread数量) |
<<<grid, block>>>中,grid表示Grid的维度/大小(Block数量),block表示Block的维度/大小(Thread数量)。
一维示例及执行分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
__global__ void kernel1D(float *data) {
// blockDim.x = 256(启动时指定)
// blockIdx.x = 0, 1, 2, ... (当前Block在Grid中的位置)
// threadIdx.x = 0, 1, 2, ..., 255(当前thread在Block中的位置)
// 计算全局线程索引
int globalIdx = blockIdx.x * blockDim.x + threadIdx.x;
data[globalIdx] = data[globalIdx] * 2;
}
int main() {
kernel1D<<<100, 256>>>(data); // 100个Block,每个Block 256个thread
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
kernel<<<100, 256>>>(data)
Grid:
Block 0: blockIdx.x=0
├── Thread 0: threadIdx.x=0, globalIdx=0
├── Thread 1: threadIdx.x=1, globalIdx=1
├── ...
└── Thread 255: threadIdx.x=255, globalIdx=255
Block 1: blockIdx.x=1
├── Thread 0: threadIdx.x=0, globalIdx=256
├── Thread 1: threadIdx.x=1, globalIdx=257
├── ...
└── Thread 255: threadIdx.x=255, globalIdx=511
...
Block 99: blockIdx.x=99
├── Thread 0: threadIdx.x=0, globalIdx=25344
└── ...
二维示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
__global__ void kernel2D(float *matrix, int width) {
// blockDim.x = 16, blockDim.y = 16
// blockIdx.x = 0,1,2,... blockIdx.y = 0,1,2,...
// threadIdx.x = 0,...,15 threadIdx.y = 0,...,15
// 计算全局行列索引
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int idx = y * width + x;
matrix[idx] = matrix[idx] * 2;
}
int main() {
dim3 blockDim(16, 16); // 16x16=256个thread/block
dim3 gridDim(10, 10); // 10x10=100个block
kernel2D<<<gridDim, blockDim>>>(matrix, width);
}
3. Bank Conflicts (Shared Memory)
每个SM中,Shared Memory被分为32个bank,存储以word(4字节)为单位,按顺序映射到这个32个bank上(第i个word存放在第(i % 32)个bank上)。这样一个时钟周期,就可以访问128字节。
所谓Bank Conflicts,就是warp访问内存时,没有遵照bank的访问顺序,导致需要多次访问内存。如下情况会产生Bank Conflicts:
warp中线程(同一个线程,或不同线程),访问一个bank中的不同地址;warp中线程,访问到下一个bank簇–即另外一个32个word组的起始地址;
如下情况,Bank Conflicts不会产生:
warp中线程,访问地址分别对应到bank簇的每个bank,不论是顺序,还是错位;warp中多个线程,访问同一个bank中的相同地址–使用boardcast分发相同地址数据到多个线程;
如何避免Bank Conflicts:首先,根据warp需要,配置bank使用4字节/8字节。其次,如果需要,使用padding。
- cuda程序优化-2.访存优化
- 16.4.3. Shared Memory
- How to understand the bank conflict of shared_mem
- CUDA shared memory bank 冲突
学习资料
本文由作者按照 CC BY 4.0 进行授权