使用 CuTe Tiled Copy、Tiled MMA 以及 Multi-Stage 实现高性能 GEMM
代码:
- https://github.com/HPC02/cuda_perf/blob/master/src/cute_gemm_sm80/gemm_sm80.cu
- https://github.com/HPC02/cuda_perf/blob/master/src/cute_gemm_sm80/kernel_sm80.cuh
TODO:GMEM -> SMEM 不会产生 bank conflicts?
配置流程及约束概览:
- 定义 CTA tile 大小
TODO
- 定义 GMEM -> SMEM 的 Tiled Copy 配置
TODO
- 定义 Tiled MMA 配置(包含SMEM TiledCopy)
TODO
- 定义 SMEM swizzle 配置,以及SMEM Layout(包含multi-stage)
TODO
大部分内容已经在其他文章中记录:
- CUTLASS-Cute 初步(4.1):MMA Swizzle – MMA、ldmatrix、smem swizzle;
- CUTLASS-Cute 初步(6):CUDA GEMM 计算优化、Multi-Stage 与软流水(Software Pipelining)。
- CUDA 笔记集合:其中第一个章节:cutlass/CuTe GEMM 中矩阵的存储方式 NT / TN / NN / TT。
本文主要记录一些第三方资料,见末尾附录。
1. 定义 block tile 大小
配置 CTA 大小为 MNK = 128 * 128 * 32,数据类型为FP16:
constexpr auto bM = cute::Int<128 * 2 / sizeof(TA)>{};
constexpr auto bN = cute::Int<128 * 2 / sizeof(TB)>{};
constexpr auto bK = cute::Int<32>{};
constexpr auto cta_tiler = cute::make_shape(bM, bN, bK); // (bM, bN, bK)
constexpr auto bP = cute::Int<3>{}; // pipeline
1.1. Roofline 计算
RTX 3060 Tensor Core FP16 理论峰值为51TFLOPS,内存带宽为 360GB/s。Roofline临界点为:51 * 1000 / 360 = 141.67 FLOPs/Byte。
对于分块矩阵计算,loop over k的过程中,包含一次乘法、一次加法。每个 CTA tile 的计算量与 GMEM 搬运量之比(算术强度AI):
TFLOPS 为:
\[TFLOPS = \text{AI} \times \text{Bandwidth}_{\text{GMEM}} = 64 \times 360 / 1000 = 23.04 \text{TFLOPS}\]明显的,增大
bM和bN可以提升算术强度,从而提升性能。
如上计算公式没有考虑到L2 Cache,如果考虑到L2 Cache,即CTA之间数据共享,理论计算公式为(以M*N*K=4096*4096*4096为例):
实测代码如下:
double flops = 2.0 * M * N * K;
double tflops = flops / (elapsed_ms * 1e-3) / 1e12;
printf("%.2f TFLOPS\n", tflops);
实测结果:
cuBLAS: 5.24442 ms, 26.2067 TFLOPS
Custom: 3.64926 ms, 37.6622 TFLOPS
达到理论峰值的37.66 / 51 = 73.84%。
2. Tiled MMA 配置
TiledMMA 使用SM80_16x8x16_F16F16F16F16_TN,对应 PTX 指令m16n8k16,使用一个warp(32个线程协作)完成子块的MMA计算。打印的MMA Atom配置信息如下:
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_16,_8,_16)
LayoutA_TV: ((_4,_8),(_2,_2,_2)):((_32,_1),(_16,_8,_128))
LayoutB_TV: ((_4,_8),(_2,_2)):((_16,_1),(_8,_64))
LayoutC_TV: ((_4,_8),(_2,_2)):((_32,_1),(_16,_8))
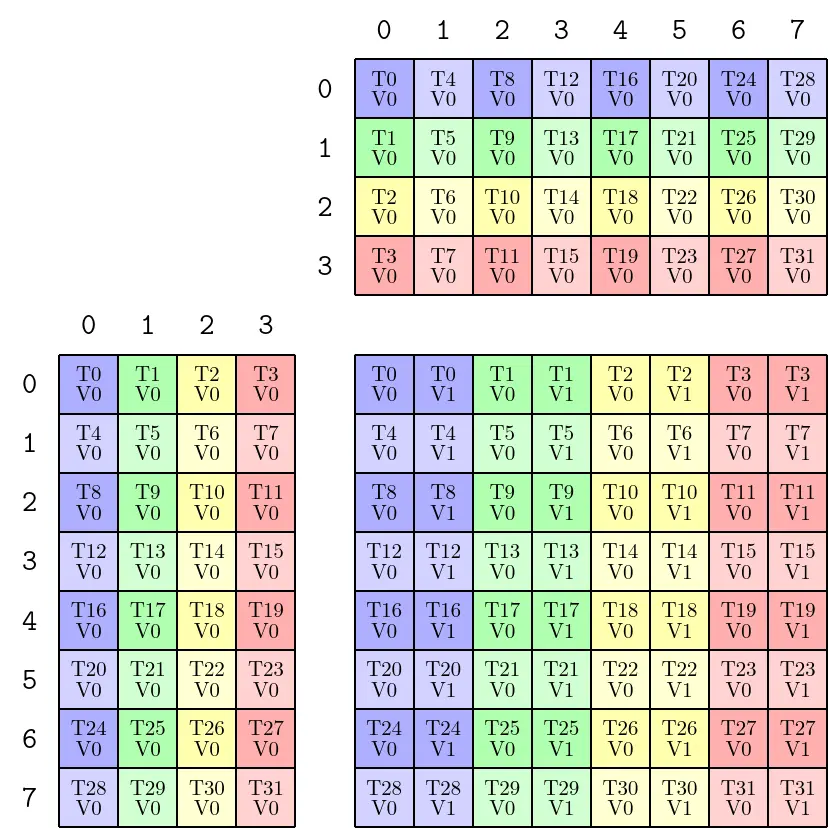
在 SMEM -> REG 的过程中,使用ldmatrix拷贝(具体为使用 CopyTraits:SM75_U16x8_LDSM_T)。ldmatrix以8 x FP16=128-bit为单位进行拷贝(可理解为:每个线程指向的SMEM要求8 x FP16连续)。SM75_U16x8_LDSM_T使用ldmatrix.x4指令,使用一个warp(32个线程),一次拷贝四个8x8 FP16=(32, 8)。SM75_U16x8_LDSM_T的打印信息如下:
Copy_Atom
ThrID: _32:_1
ValLayoutSrc: (_32,_8):(_8,_1)
ValLayoutDst: ((_4,_8),(_1,_2,_4)):((_16,_1),(_1,_8,_64))
ValLayoutRef: ((_4,_8),(_1,_2,_4)):((_16,_1),(_1,_8,_64))
ValueType: 16b
参考https://zhuanlan.zhihu.com/p/696231622,有如下表述:“矩阵中连续的两行无需在shared memory中连续,但1行是连续的128-bit。也就是说,ldmatrix读取shared memory的单元是128-bit。”。
Tiled MMA受上述SMEM的Tiled Copy约束,要求每个线程处理 8 x FP16数据,这个约束作用于A sub-tile和B sub-tile。A sub-tile已经满足要求,针对B sub-tile,SM80_16x8x16_F16F16F16F16_TN只给每个线程分配四个FP16,因此需要使用permutation参数(即mma_layout)使其满足SMEM TiledCopy要求:
using MMATraits = cute::MMA_Traits<cute::SM80_16x8x16_F16F16F16F16_TN>;
using MMAAtomShape = MMATraits::Shape_MNK;
constexpr auto mma_atom = cute::MMA_Atom<MMATraits>{};
constexpr auto mma_atom_shape = MMAAtomShape{}; // (16, 8, 16)
constexpr auto MMA_LAYOUT_M = 2, MMA_LAYOUT_N = 2, MMA_LAYOUT_K = 1; // 线程数扩充
constexpr auto NUM_MMA_TILE_M = 1, NUM_MMA_TILE_N = 2, NUM_MMA_TILE_K = 1; // 每个线程Atom数量扩充
constexpr auto MMA_TILE_M = cute::get<0>(mma_atom_shape) * NUM_MMA_TILE_M * MMA_LAYOUT_M; // 32
constexpr auto MMA_TILE_N = cute::get<1>(mma_atom_shape) * NUM_MMA_TILE_N * MMA_LAYOUT_N; // 32
constexpr auto MMA_TILE_K = cute::get<2>(mma_atom_shape) * NUM_MMA_TILE_K * MMA_LAYOUT_K; // 16
constexpr auto mma_layout =
cute::make_layout(cute::make_shape(cute::Int<MMA_LAYOUT_M>{}, cute::Int<MMA_LAYOUT_N>{}, cute::Int<MMA_LAYOUT_K>{}));
constexpr auto mma_tile = cute::make_tile(cute::Int<MMA_TILE_M>{}, cute::Int<MMA_TILE_N>{}, cute::Int<MMA_TILE_K>{});
constexpr auto tiled_mma = cute::make_tiled_mma(mma_atom, mma_layout, mma_tile);
打印的TiledMMA配置信息如下:
TiledMMA
ThrLayoutVMNK: (_32,_2,_2,_1):(_1,_32,_64,_0)
PermutationMNK: (_32,_32,_16)
MMA_Atom
ThrID: _32:_1
Shape_MNK: (_16,_8,_16)
LayoutA_TV: ((_4,_8),(_2,_2,_2)):((_32,_1),(_16,_8,_128))
LayoutB_TV: ((_4,_8),(_2,_2)):((_16,_1),(_8,_64))
LayoutC_TV: ((_4,_8),(_2,_2)):((_32,_1),(_16,_8))
-
(2,2,1):(_1,2,4):描述Atom的线程扩展配置,即在M、N、K三个维度上分别扩展2倍、2倍、1倍线程。 -
(32,32,16):(_1,32,1024):描述Tile的大小配置,即解决的MNK规模。
2.1. 约束
这个定义的TiledMMA针对线程做了配置:在M方向及N方向均使用MMAAtom的两倍线程,在K方向上保持不变。即使用 2x2=4个warp,共128个线程协作完成一个MMA Tile的计算。
TiledMMA的配置,对 GMEM => SMEM拷贝过程中的线程划分形成约束,即在A/B子块的GMEM => SMEM过程中,配置的线程数量也是 128 个线程。
同时,TildMMA的配置,对输入A/B矩阵的tiler也形成约束,即要求分配给CTA的tile大小在M、N、K三个维度上分别是MMA_TILE_M=32、MMA_TILE_N=32、MMA_TILE_K=16的整数倍。
A. 资料
- cute 之 GEMM流水线
- cute 之 高效GEMM实现
- CUDA SGEMM优化笔记
- 从 GEMM 实践 CUDA 优化
- https://github.com/NVIDIA/cutlass/blob/main/examples/cute/tutorial/sgemm_sm80.cu:官方源码,包含multi-stage pipeline实现
3. Multi-Stage Pipeline
3.1. SMEM 资源分配
GMEM => SMEM采用cp.async指令,重叠内存拷贝与GEMM计算以隐藏GMEM访问延迟。其需要的SMEM计算公式为:
其中:
- $bM \times bK$:加载自矩阵 $A$ 的分块大小
- $bK \times bN$:加载自矩阵 $B$ 的分块大小
- $\text{numStages}$:流水线级数(即 SMEM 中同时维护的分块副本数)
配置部分代码如下:
constexpr auto smem_shape_A = cute::make_shape(bM, bK, bP); // (bM, bK, bP)
constexpr auto smem_shape_B = cute::make_shape(bN, bK, bP); // (bN, bK, bP)
constexpr auto smem_layout_A = cute::tile_to_shape(smem_atom_layout_A_swizzled, smem_shape_A);
constexpr auto smem_layout_B = cute::tile_to_shape(smem_atom_layout_B_swizzled, smem_shape_B);
// GMEM -> SMEM 的 Tiled Copy 配置
constexpr auto gmem_tiled_copy_A =
cute::make_tiled_copy(cute::Copy_Atom<CopyOperationA, TA>{}, thread_layout_A, vector_layout_A);
constexpr auto gmem_tiled_copy_B =
cute::make_tiled_copy(cute::Copy_Atom<CopyOperationB, TB>{}, thread_layout_B, vector_layout_B);
// Tiled MMA 配置
// 见上面章节,此处省略......
// Tiled MMA 配置对 GMEM -> SMEM 过程的约束
CUTE_STATIC_ASSERT(cute::size(tiled_mma) == cute::size(thread_shape_C));
CUTE_STATIC_ASSERT(std::is_same_v<TA, cute::half_t> && std::is_same_v<TB, cute::half_t> && std::is_same_v<TC, cute::half_t>);
// configure tiled copy from smem to register via tiled MMA
using Copy_Atom_A = cute::Copy_Atom<cute::SM75_U16x8_LDSM_T, TA>;
using Copy_Atom_B = cute::Copy_Atom<cute::SM75_U16x8_LDSM_T, TB>;
constexpr auto smem_tiled_copy_A = cute::make_tiled_copy_A(Copy_Atom_A{}, tiled_mma);
constexpr auto smem_tiled_copy_B = cute::make_tiled_copy_B(Copy_Atom_B{}, tiled_mma);
A.1. 全流程优化参考资料
- How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog
- CUTLASS Tutorial: Efficient GEMM kernel designs with Pipelining
- Nvidia Tensor Core-CUDA HGEMM Advanced Optimization:待阅读
- Advanced Matrix Multiplication Optimization on NVIDIA GPUs:待阅读
- 0x_gemm_tutorial.md:cutlass/CuTe仓库教程
- CUDA Techniques to Maximize Compute and Instruction Throughput(pdf)
- Developing CUDA Kernels to Push Tensor Cores to the Absolute Limit on NVIDIA A100 (pdf)
- Performance Analysis of CUDA-based General Matrix Multiplication through Memory Coalescing and Grid-Level Parallelization
- CUTLASS MMA Pipelined Header
- https://github.com/NVIDIA/cutlass/blob/main/test/unit/gemm/device/default_gemm_configuration.hpp
- CuTe– CUDA Tensors:Layout & Tensor基础
A.2. Learn CUTLASS the hard way
A.3. Triton
Enjoy Reading This Article?
Here are some more articles you might like to read next: